DAPO: An Open-Source LLM Reinforcement Learning System at Scale
-
ArXiv URL: http://arxiv.org/abs/2503.14476v2
-
作者: Haodong Zhou; Honglin Yu; Mu Qiao; Xin Liu; Gaohong Liu; Haibin Lin; Lingjun Liu; Xiaochen Zuo; Yuxuan Song; Zhiqi Lin; 等25人
TL;DR
本文提出了一种名为DAPO的强化学习算法,通过解耦裁剪范围、动态采样、Token级损失计算和超长奖励塑造这四项关键技术,成功解决了大语言模型在长思路链(long-CoT)推理任务中遇到的熵崩溃、训练不稳定和效率低下等问题,并开源了整个大规模强化学习系统。
关键定义
本文的核心是DAPO算法及其包含的四项关键技术,旨在优化基于PPO/GRPO的大模型强化学习(Reinforcement Learning, RL)流程。
-
DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization): 一种改进的策略优化算法。其目标函数在GRPO的基础上,对PPO的裁剪(Clip)机制进行解耦,并结合了动态采样策略,以增强探索和训练稳定性。其目标函数如下:
\[\mathcal{J}_{\text{DAPO}}(\theta)=\mathbb{E}_{(q,a)\sim\mathcal{D},\{o_{i}\}_{i=1}^{G}\sim\pi_{\theta_{\text{old}}}(\cdot\mid q)}\Bigg{[}\frac{1}{\sum_{i=1}^{G} \mid o_{i} \mid }\sum_{i=1}^{G}\sum_{t=1}^{ \mid o_{i} \mid }\min\Big{(}r_{i,t}(\theta)\hat{A}_{i,t},\ \text{clip}\Big{(}r_{i,t}(\theta),1-{\varepsilon_{\text{low}}},1+{\varepsilon_{\text{high}}}\Big{)}\hat{A}_{i,t}\Big{)}\Bigg{]}\]该算法的约束条件是,对于每个问题的采样组,正确答案的数量必须在0和组大小 $G$ 之间,即 $$s.t. 0 < {o_i is_equivalent(a, o_i)} < G$$。 -
Clip-Higher (提高裁剪上限): 一种修改PPO裁剪机制的策略。它将传统的对称裁剪范围 $\varepsilon$ 解耦为不同的下限 $\varepsilon_{\text{low}}$ 和上限 $\varepsilon_{\text{high}}$。通过特意增高 $\varepsilon_{\text{high}}$ 的值,该策略为低概率的“探索性”Token提供了更大的概率提升空间,从而对抗熵崩溃(entropy collapse)现象,增加策略的多样性。
-
Dynamic Sampling (动态采样): 一种提升训练效率的采样策略。在生成训练批次时,该策略会动态地过滤掉那些所有样本都正确或所有样本都错误的“零优势(zero advantage)”数据组。通过不断采样,直到凑够一个批次的有效(非零优势)数据,从而确保每个批次的梯度信号都是有效的,提高了训练的稳定性和样本效率。
-
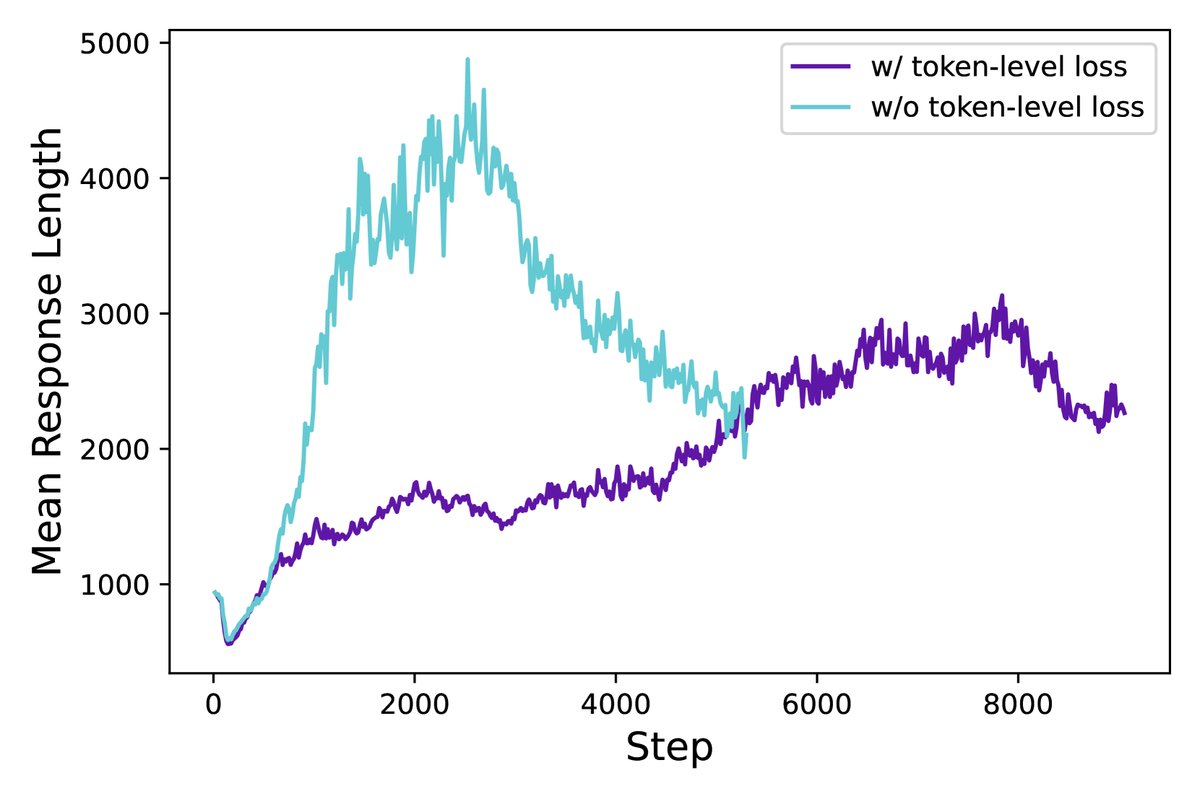
Token-Level Policy Gradient Loss (Token级策略梯度损失): 一种损失计算方式。与GRPO中先在样本内按Token求平均、再在样本间求平均的“样本级”损失不同,该方法将一个批次内所有Token的损失直接求和并按总Token数归一化。这使得每个Token对梯度的贡献是均等的,避免了长序列中的Token信号被稀释,能更有效地学习长推理链中的模式并抑制无意义的长输出。
-
Overlong Reward Shaping (超长奖励塑造): 一种针对超长生成序列的奖励设计机制。它不是对超出最大长度的序列简单施加-1的惩罚,而是引入了一个“软惩罚”区间。当序列长度超过一个预设的软阈值但在硬截断长度之内时,惩罚会随着长度的增加而线性增大。这为模型提供了更平滑的信号来避免过长输出,同时减少了因截断而惩罚合理推理过程所带来的奖励噪声。
相关工作
当前,通过测试时扩展(test-time scaling)如思维链(Chain-of-Thought, CoT)来激发大语言模型(LLM)的复杂推理能力已成为前沿范式,其核心驱动技术是大规模强化学习(RL)。诸如OpenAI的o1和DeepSeek的R1等先进推理模型都依赖于此,但在其技术报告中却隐藏了关键的算法和训练细节。
这导致了该领域的关键瓶颈:社区难以复现SOTA模型的RL训练效果。研究者在使用现有开源算法(如GRPO)进行大规模长CoT推理任务训练时,普遍遇到了熵崩溃(模型过早收敛,探索能力下降)、奖励噪声(不准确的奖励信号干扰学习)和训练不稳定等严重问题。例如,本文的初步实验表明,在Qwen2.5-32B模型上直接使用GRPO在AIME数学竞赛基准上仅能达到30分,远低于DeepSeek声称的47分。
因此,本文旨在解决的具体问题是:如何克服大规模LLM强化学习中的关键技术障碍,构建一个可复现、高效且性能领先的开源RL系统,以释放LLM在复杂推理任务上的全部潜力。
本文方法
为了解决上述问题,本文提出了DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization)算法,并围绕它构建了一个完整的、开源的大规模RL系统。DAPO基于GRPO框架,但移除了不适用于长CoT场景的KL散度惩罚项,并采用基于规则的奖励模型(正确为1,错误为-1)。其核心创新在于引入了以下四项关键技术:
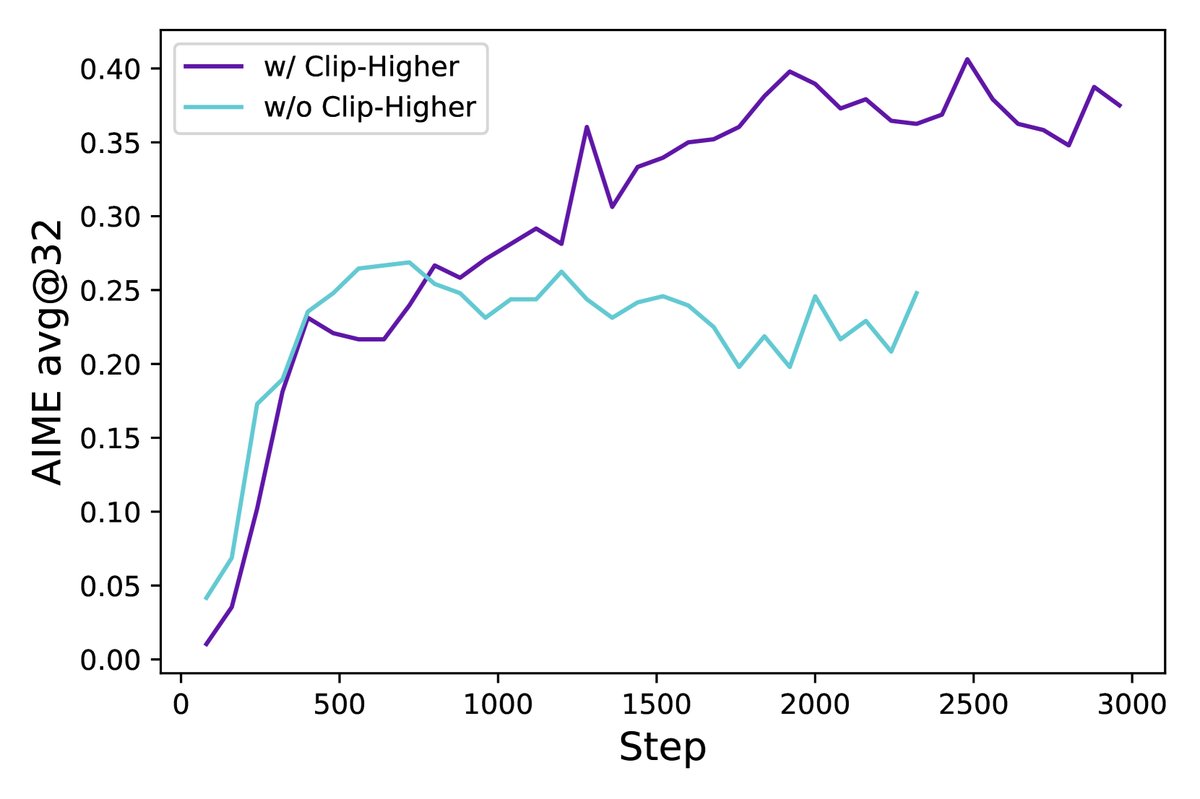
创新点1:Clip-Higher (提高裁剪上限)
问题:标准的PPO/GRPO算法使用对称的裁剪范围(如 \(1±ε\)),这会限制策略的探索能力。当一个有益但初始概率很低的“探索性”Token出现时,其概率的上调空间被严格限制(例如,0.01的概率最多只能变成0.012),而高概率的“利用性”Token则几乎不受影响。这种机制会加速策略收敛到局部最优,导致熵崩溃和样本多样性下降。
创新:DAPO将裁剪范围解耦为下限 \(ε_low\) 和上限 \(ε_high\)。通过将 \(ε_high\) 设置得比 \(ε_low\) 更大(例如,\(ε_low=0.2\), \(ε_high=0.28\)),算法为那些带来正向优势(\(Â_t > 0\))的Token提供了更大的概率提升空间。
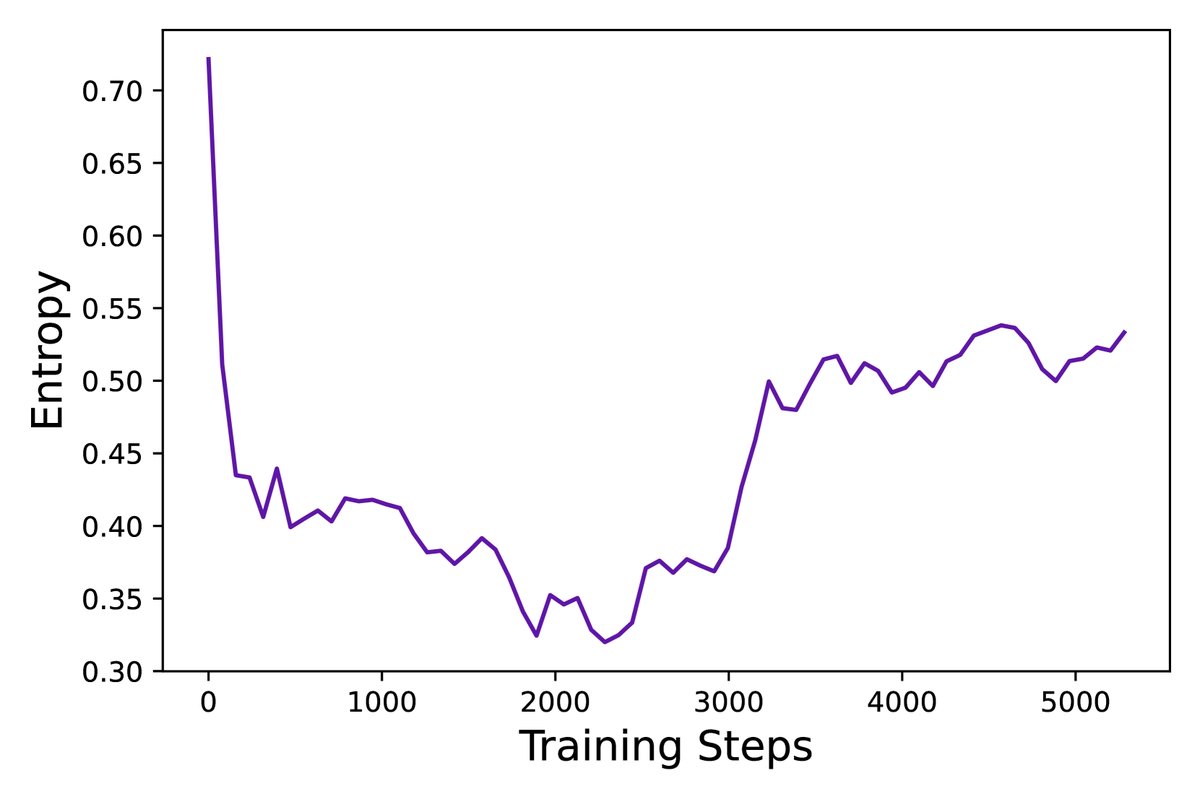
优点:该策略有效缓解了熵崩溃问题,提升了策略熵,使模型能生成更多样化的样本,从而增强了探索能力并最终提升了性能。实验表明,应用此策略后,模型熵值停止了快速下跌趋势。
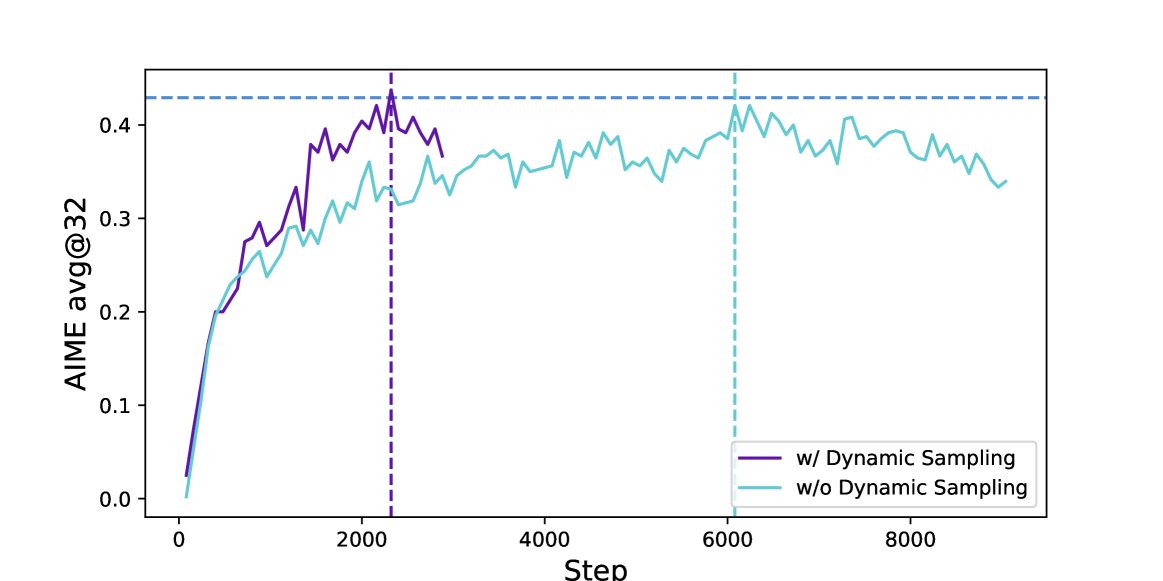
创新点2:Dynamic Sampling (动态采样)
问题:在RL训练中,随着模型能力的提升,会出现某些问题的所有采样回答都正确(或都错误)的情况。此时,根据GRPO的优势计算公式(组内奖励归一化),该组所有样本的优势值 \(Â\) 均为0。这意味着这些样本对梯度更新的贡献为零,导致有效批次大小(batch size)减小,梯度方差增大,训练效率和稳定性下降。
创新:DAPO引入动态采样机制。在构建每个训练批次时,系统会持续采样,并只保留那些既有正确答案又有错误答案的样本组,直到批次被填满。
优点:此举确保了每个参与训练的样本组都能产生有效的、非零的梯度信号,极大地稳定了训练过程并提高了样本效率。虽然这可能增加前向推理的计算量,但实验证明,由于所需的训练步骤减少,总体收敛时间反而更快。
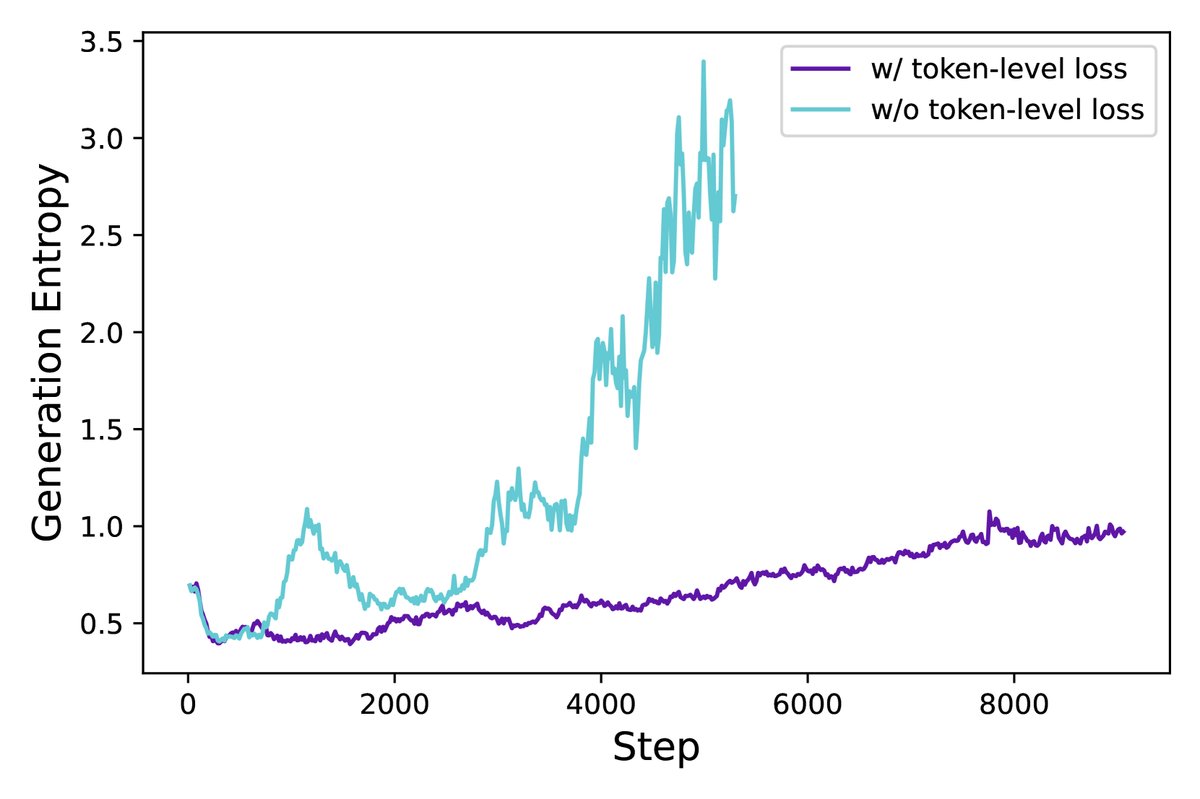
创新点3:Token-Level Policy Gradient Loss (Token级策略梯度损失)
问题:GRPO采用“样本级”损失计算,即先在每个序列内部对所有Token的损失求平均,再对不同序列的平均损失求平均。这导致所有序列在最终损失中的权重相同。然而,在长CoT场景下,序列长度差异巨大。这种方式会稀释长序列中每个Token的梯度信号,使得模型难以从优质的长推理链中充分学习,也难以有效惩罚劣质长序列中的无意义内容(如乱码、重复)。
创新:DAPO改为采用“Token级”损失计算,即将批次内所有Token的损失直接求和,然后除以总Token数。
优点:确保了每个Token对总梯度的贡献权重相等,无论它处于长序列还是短序列。这使得模型能更公平、更有效地从所有Token中学习,从而更好地控制生成长度和熵的健康增长,提升了训练的稳定性。
创新点4:Overlong Reward Shaping (超长奖励塑造)
问题:对于超出最大生成长度而被截断的序列,如何给予奖励是一个棘手的问题。简单地给予负面惩罚会引入奖励噪声,因为一个推理过程可能本身是正确的,仅仅因为过长而被惩罚,这会误导模型。
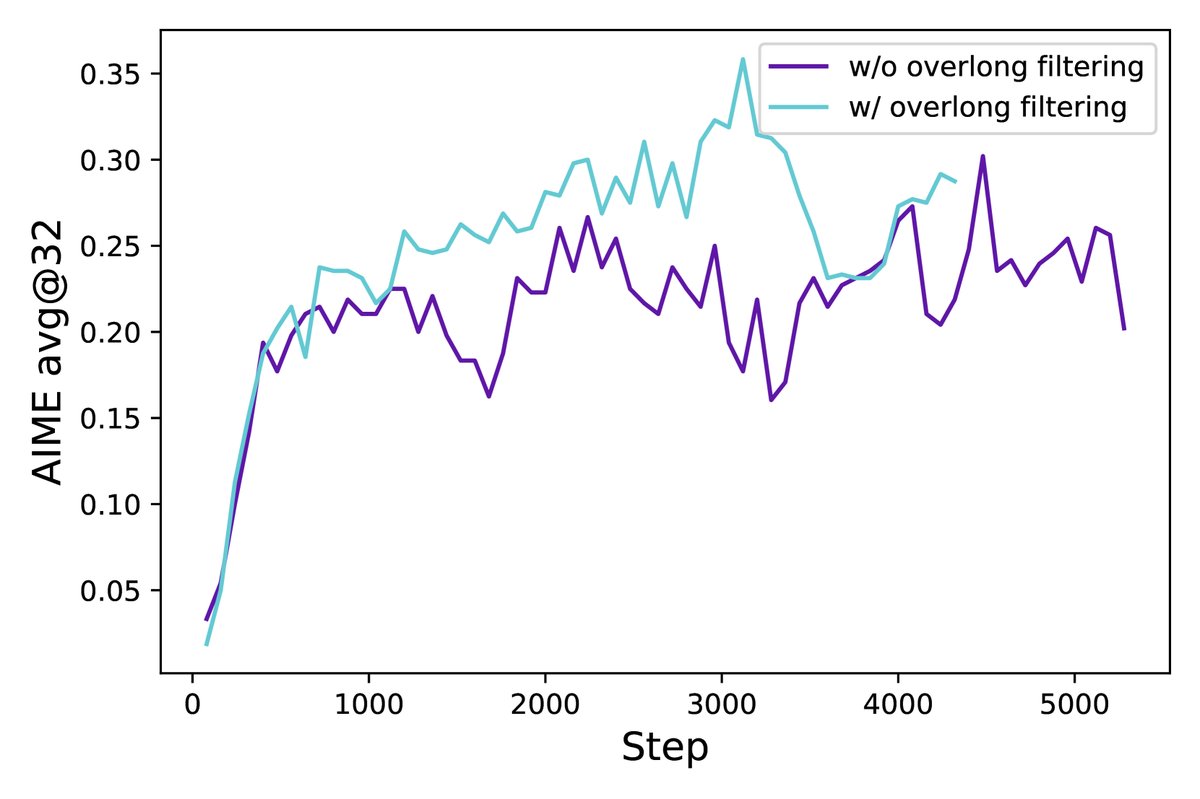
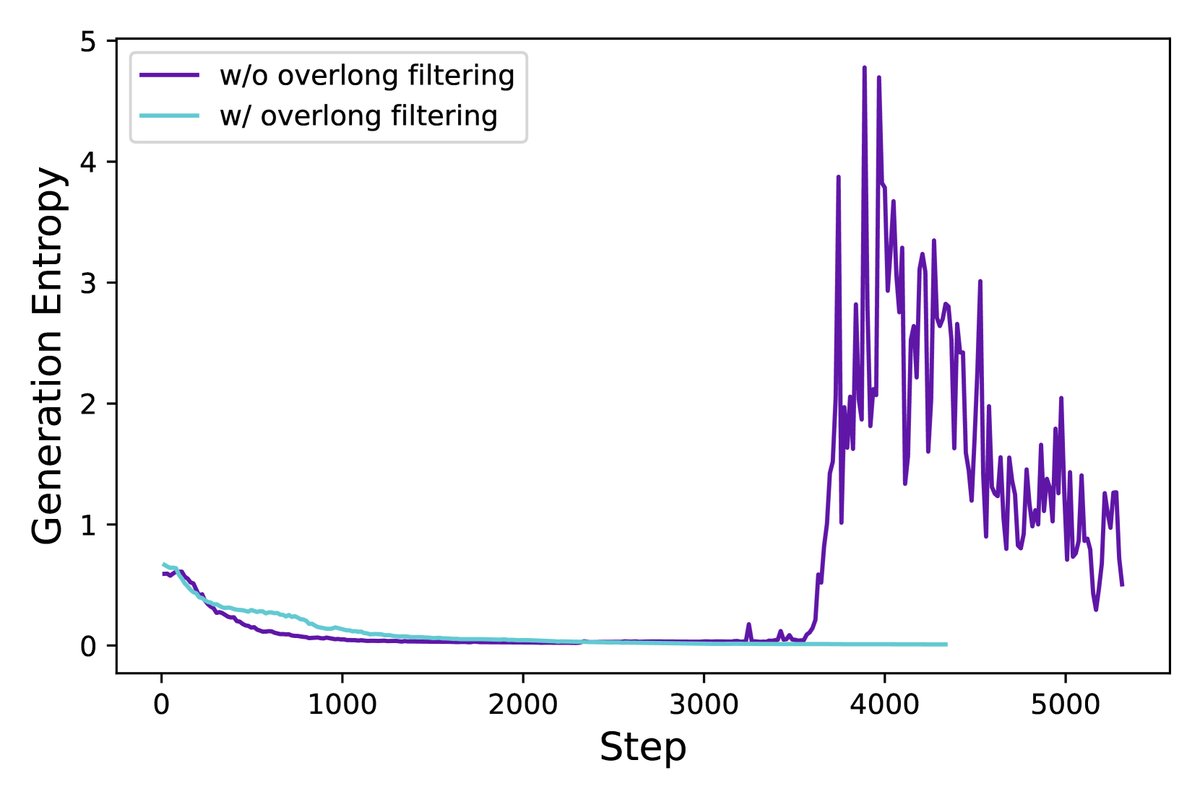
创新:DAPO提出了一种更精细的奖励塑造策略。首先,实验证明仅过滤掉超长样本的损失(Overlong Filtering)就能显著稳定训练。在此基础上,本文进一步提出了软性超长惩罚(Soft Overlong Punishment)。具体来说,设置一个惩罚区间(如最大长度 \(L_max\) 前的4096个Token),当生成长度落入此区间时,会根据超出的长度施加一个线性递增的负奖励。
\[R_{\text{length}}(y)=\begin{cases}0,& \mid y \mid \leq L_{\text{max}}-L_{\text{cache}}\\ \frac{(L_{\text{max}}-L_{\text{cache}})- \mid y \mid }{L_{\text{cache}}},&L_{\text{max}}-L_{\text{cache}}< \mid y \mid \leq L_{\text{max}}\\ -1,&L_{\text{max}}< \mid y \mid \end{cases}\]优点:这种渐进式惩罚为模型提供了更平滑、更明确的信号以避免生成无谓的超长内容,同时避免了因硬性惩罚带来的训练不稳定。实验表明,该策略在稳定训练的同时,进一步提升了模型性能。
此外,本文还介绍了数据集转换工作,将数学问题的答案统一处理为易于程序解析的整数格式,为基于规则的精确奖励计算提供了保障。
实验结论
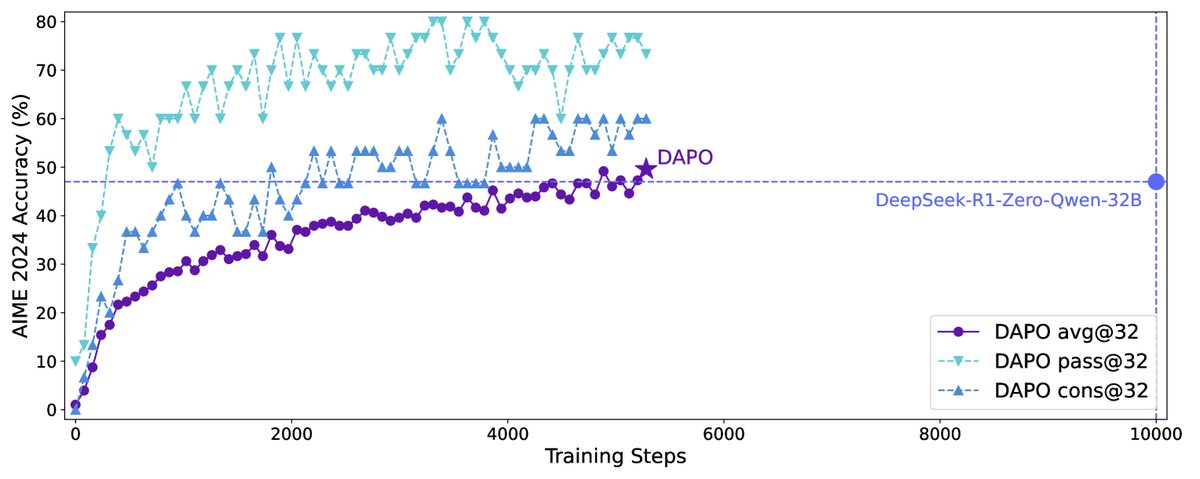
本文在AIME 2024数学竞赛数据集上对DAPO算法进行了全面评估,基座模型为Qwen2.5-32B。
主要结果:
- 性能超越SOTA:采用DAPO算法训练的Qwen2.5-32B模型在AIME 2024测试集上取得了50分(avg@32)的成绩,超过了之前由DeepSeek-R1-Zero-Qwen-32B在该模型上取得的47分的SOTA结果。
- 训练效率更高:达到上述性能仅用了DeepSeek方法50%的训练步数,展示了DAPO算法的高效率。
- 基线对比显著:相比之下,使用朴素的GRPO算法只能达到30分,凸显了DAPO中各项技术改进的巨大价值。
消融实验分析: 实验通过逐步叠加DAPO的各项技术,清晰地展示了每个组件的贡献。如下表所示,从GRPO基线出发,每增加一项技术,模型在AIME 2024上的得分都有稳定提升,证明了各项创新的有效性。
| 模型 | $\textbf{AIME24}_{\text{avg@32}}$ |
|---|---|
| DeepSeek-R1-Zero-Qwen-32B | 47 |
| Naive GRPO (基线) | 30 |
| + Overlong Filtering (超长过滤) | 36 |
| + Clip-Higher (提高裁剪上限) | 38 |
| + Soft Overlong Punishment (软性超长惩罚) | 41 |
| + Token-level Loss (Token级损失) | 42 |
| + Dynamic Sampling (DAPO) (动态采样) | 50 |
训练动态与洞察:
- 通过监控训练过程中的关键指标(如响应长度、奖励得分、生成熵、平均概率),本文发现DAPO能维持各项指标的健康动态,如熵值缓慢上升,避免了崩溃。
- 一个有趣的发现是,在RL训练过程中,模型会自发涌现出新的、更复杂的推理模式,例如在早期模型中不存在的“检查并反思之前步骤”的行为。这表明RL不仅在强化现有能力,还在探索和创造新的解题策略。


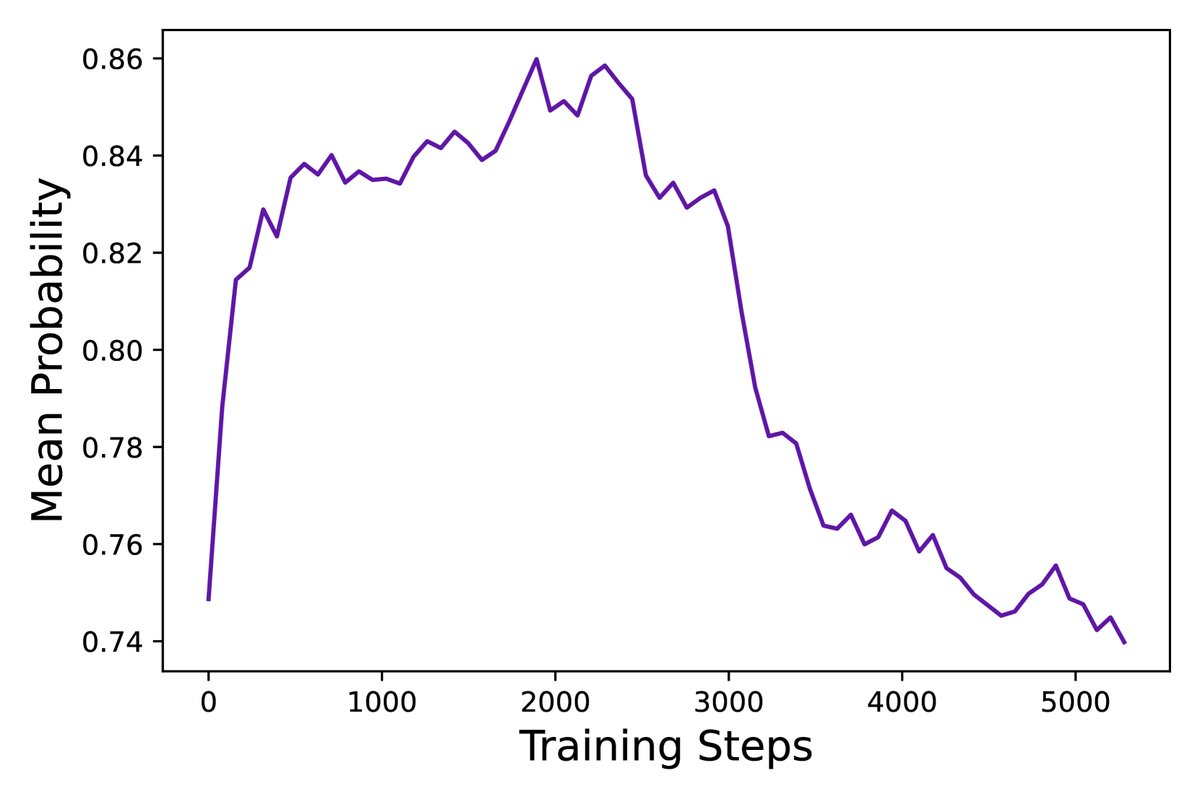
最终结论:本文提出的DAPO算法及其四项关键技术,成功地解决了大规模LLM在长CoT推理任务中进行RL训练时的核心痛点。该方法不仅在数学推理任务上取得了SOTA性能,且效率更高。通过完全开源算法、代码和数据集,本文为社区提供了一个强大且可复现的解决方案,极大地推动了LLM复杂推理能力的研究和应用。