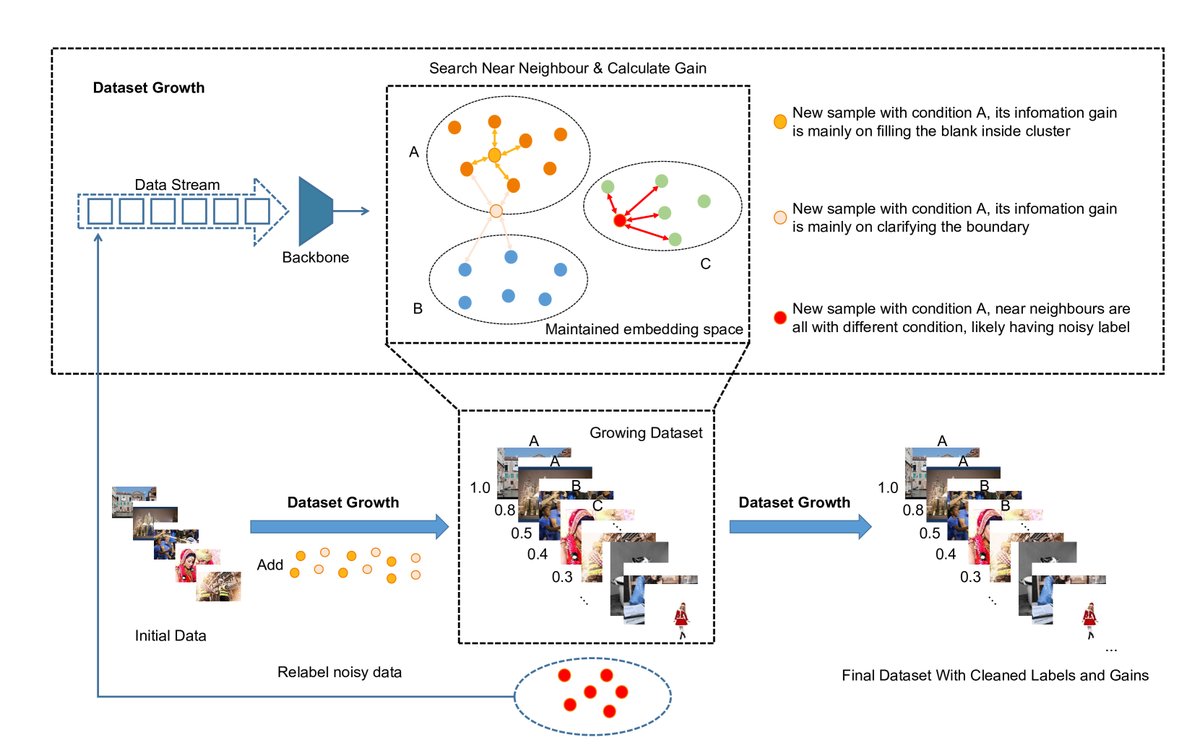
Dataset Growth
-
ArXiv URL: http://arxiv.org/abs/2405.18347v2
-
作者: Wrick Talukdar; Anjanava Biswas
-
发布机构: Alibaba Group; ETH Zurich; Harbin Institute of Technology; National University of Singapore; Shenzhen Technology University
TL;DR
本文提出了一种名为 InfoGrowth 的高效在线算法,通过实时评估数据流中每个数据点的噪声和冗余度,动态地清洗和选择信息量高的数据,以实现高质量数据集的持续、高效增长。
关键定义
本文沿用并组合了多个现有概念,提出了一个新的数据处理框架,其核心在于以下几个术语的组合应用:
- InfoGrowth: 本文提出的核心方法。它是一个在线算法框架,用于在数据持续增长的过程中,同步进行数据清洗和选择,旨在维持一个既干净又多样化的高质量数据集。
- 信息增益 (Information Gain): 本文定义的一个关键指标,用于衡量新数据点所带来的新信息量。它通过计算新数据点在嵌入空间中与其 \(k\) 个最近邻居的平均余弦距离来估计,即 \(Gain_Info = mean_i([cos-dis(d, neighbour_i)])\)。信息增益越大的样本,代表其与现有数据集的差异越大,信息量越丰富。
- 在线近似近邻搜索 (Online Approximate Near Neighbor Search): InfoGrowth 实现效率的关键技术,本文采用了 HNSW 算法。该技术使得在庞大的数据集中查找最近邻居的时间复杂度从 \(O(n)\) 降低到 \(O(log n)\),从而能够高效地在线计算每个新数据点的信息增益。
- 子模函数启发 (Submodular Function Inspired): 本文的信息增益计算受到了子模函数 (Submodular Function) 的启发。子模函数描述了向集合中添加元素时边际效益递减的特性。本文的方法通过关注局部邻域来近似这种特性,在保证效率的同时,有效避免了数据冗余。
相关工作
当前,深度学习的发展严重依赖于大规模数据集,但随着数据量的爆炸式增长,尤其是在网络数据层面,手动维护和清洗数据集已变得不切实际。

现有的数据策管(Curation)技术存在以下关键问题:
- 离线处理为主: 多数方法如 BLIP 中的自举(bootstrapping)或 DivideMix,通常采用“先收集,后清理”的离线模式。这需要对整个数据集进行昂贵的模型训练或多轮处理,效率低下且难以适应数据持续流入的场景。
- 问题拆分: 现有方法通常只专注于解决噪声(cleanness)或冗余(redundancy)中的一个问题,而现实世界的数据流同时存在这两种问题。
- 扩展性受限: 当数据规模达到数十亿级别时,反复对整个数据集进行策管的计算成本变得无法承受。
因此,本文旨在解决的核心问题是:如何设计一个高效、可扩展的在线算法,能够随着数据的持续增长,同时处理噪声和冗余问题,动态地构建一个高质量的训练数据集?
本文方法
本文提出的 InfoGrowth 框架通过一个在线流程,对流入的数据进行实时评估和处理,以保证最终数据集的清洁度和多样性。
概述
InfoGrowth 的整体流程如下图所示。当一个数据流输入时,每个数据点首先被一个预训练的骨干模型(如 BLIP)编码成特征嵌入。随后,该数据点依次通过三个核心模块:
- Cleaner (清洗器):检测并修正噪声样本。
- Gain Calculator (增益计算器):评估样本的信息增益。
- Selector (选择器):根据信息增益决定样本的采样策略。 处理过的数据会被加入到一个动态增长的、高质量的数据池中,同时其特征嵌入也会更新到近邻搜索结构中,用于评估后续数据。
该算法的单步流程可总结如下: ``$$ 算法1 InfoGrowth 算法 (单步)
输入: 流式数据对 (d_i, c_i),邻域超参数 k,列表 L,近邻搜索结构 NN 输出: 带有增益信息的处理后数据列表 L
p ← Cleaner(c_i, d_i) 如果 p < δ: c_i ← Cleaner(d_i) // 重新生成标签/标题 p ← Cleaner(c_i, d_i) 如果 p < δ: Continue // 放弃该样本 结束 结束
d_feature ← Encoder(d_i) Neighbors = NN(d_feature, k) g_i ← mean(cosine-distance(d_feature, Neighbors))
将 (d_i, c_i, g_i) 添加到 L 中,并基于 g_i 值进行采样 将 d_feature 添加到 NN 中 \(`\)
理论基础
本文从贝叶斯推断的视角统一了不同类型的机器学习任务。无论是分类、多模态检索还是自回归预测,其本质都是在学习一个条件概率分布 \(P(d|c)\) 或 \(P(c|d)\)。一个强大的多模态模型(如 BLIP)能将不同数据映射到一个统一的嵌入空间,并根据自然语言描述的条件 \(c\) 将数据点分离开。基于这个嵌入空间,我们就可以通过评估新数据点 \(d\) 相对于已有清洁数据集的位置,来判断它是噪声、冗物还是有价值的新信息。
噪声检测与修正 (Cleaner)
清洗器的本质是一个预测 \(P(c|d)\) 的模型。
- 对于多模态数据:本文使用一个预训练的 BLIP 模型作为编码器。通过计算图像和文本嵌入之间的余弦相似度,过滤掉相似度低于阈值 $\delta$ 的低质量样本。对于识别出的噪声样本,利用更强大的 MiniGPT-4 模型为其重新生成高质量的文本描述(recaptioning)。
- 对于单模态数据:清洗器是一个在该任务上预训练好的模型,用于识别可疑标签并重新标注。
信息增益计算 (Gain Calculator)
这是本文的核心创新之一。为了高效评估新数据点的信息量,InfoGrowth 采用以下策略:
- 高效邻域搜索:利用 HNSW (Hierarchical Navigable Small World) 算法,以 \(O(log n)\) 的时间复杂度在已收集的数据嵌入中找到新数据点的 \(k\) 个最近邻居。
-
增益函数:信息增益 \(Gain_Info\) 定义为该数据点与其 \(k\) 个最近邻居的平均余弦距离。距离越大,表示该数据点周围越“空旷”,信息越新颖。
\[Gain_{Info} = \text{mean}_{i}([\text{cos-dis}(d, \text{neighbour}_{i})])\] - 分类任务扩展:在分类任务中,额外引入“熵增益” (\(Gain_Entropy = 1 - p\)),其中 \(p\) 是用近邻标签预测当前样本标签的准确率。该增益倾向于保留那些位于决策边界附近、有助于模型学习区分性的样本。
信息样本选择 (Sampler)
本文设计了两种采样器:
-
静态采样器 (Static Sampler):在固定的数据集大小下,根据每个样本的归一化信息增益 \(G_i\) 作为采样概率,旨在最大化数据集整体的多样性。
\[\mathcal{P}(x_{i}) = \frac{G_{i}}{\sum_{j=1}^{ \mid L \mid }G_{j}}\] -
动态采样器 (Dynamic Sampler):为节省训练成本,采用两阶段采样策略。一个阶段使用高信息增益的样本以保证多样性(概率同上),另一个阶段则侧重于低信息增愈(更冗余)的样本(概率 \(P(x_i)\) 基于 \(G'(x_i) = max(0.1, 1 - G_i)\))以加强泛化。这种策略可在训练期间交替使用,节约约 45-50% 的训练计算量。
实验结论
关键实验结果
本文在多模态和单模态任务上验证了 InfoGrowth 的有效性。
1. 多模态任务 (BLIP 在 CC3M 数据集)
-
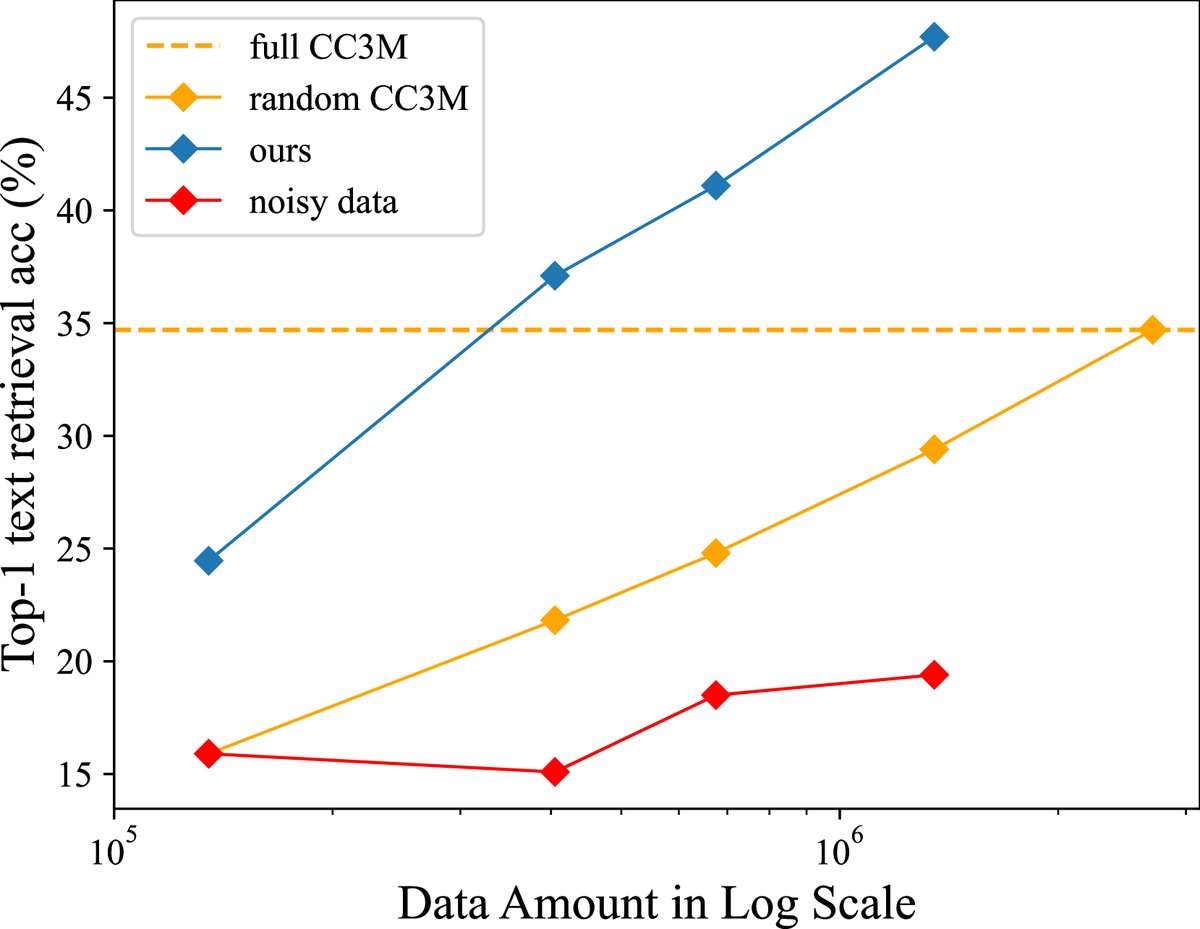
数据效率显著提升:InfoGrowth 展现了 2x~4x 的数据效率。如下图所示,使用 InfoGrowth 处理后的少量数据(如0.4M-0.68M)训练的模型,其性能就能媲美甚至超越使用完整原始 CC3M 数据集(2.7M)训练的模型。
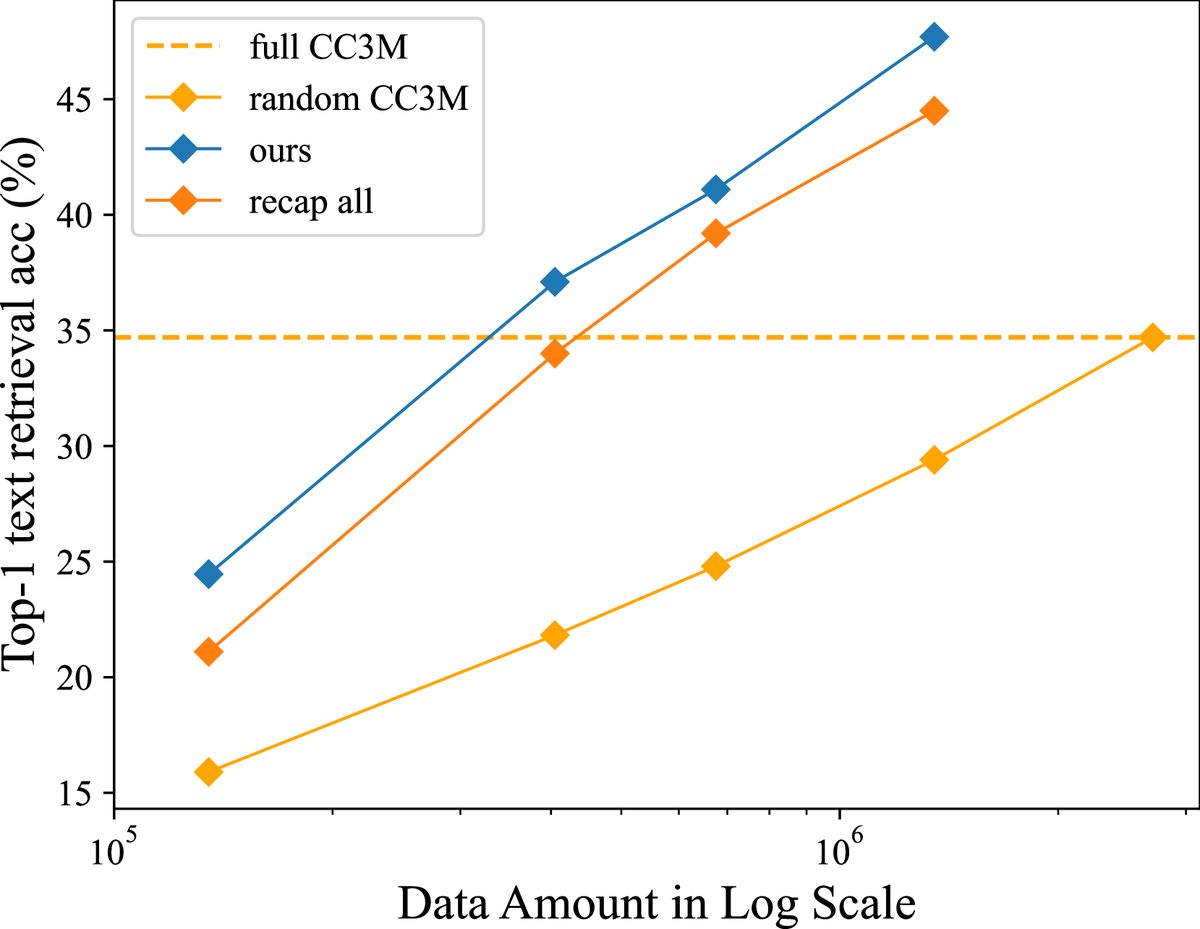
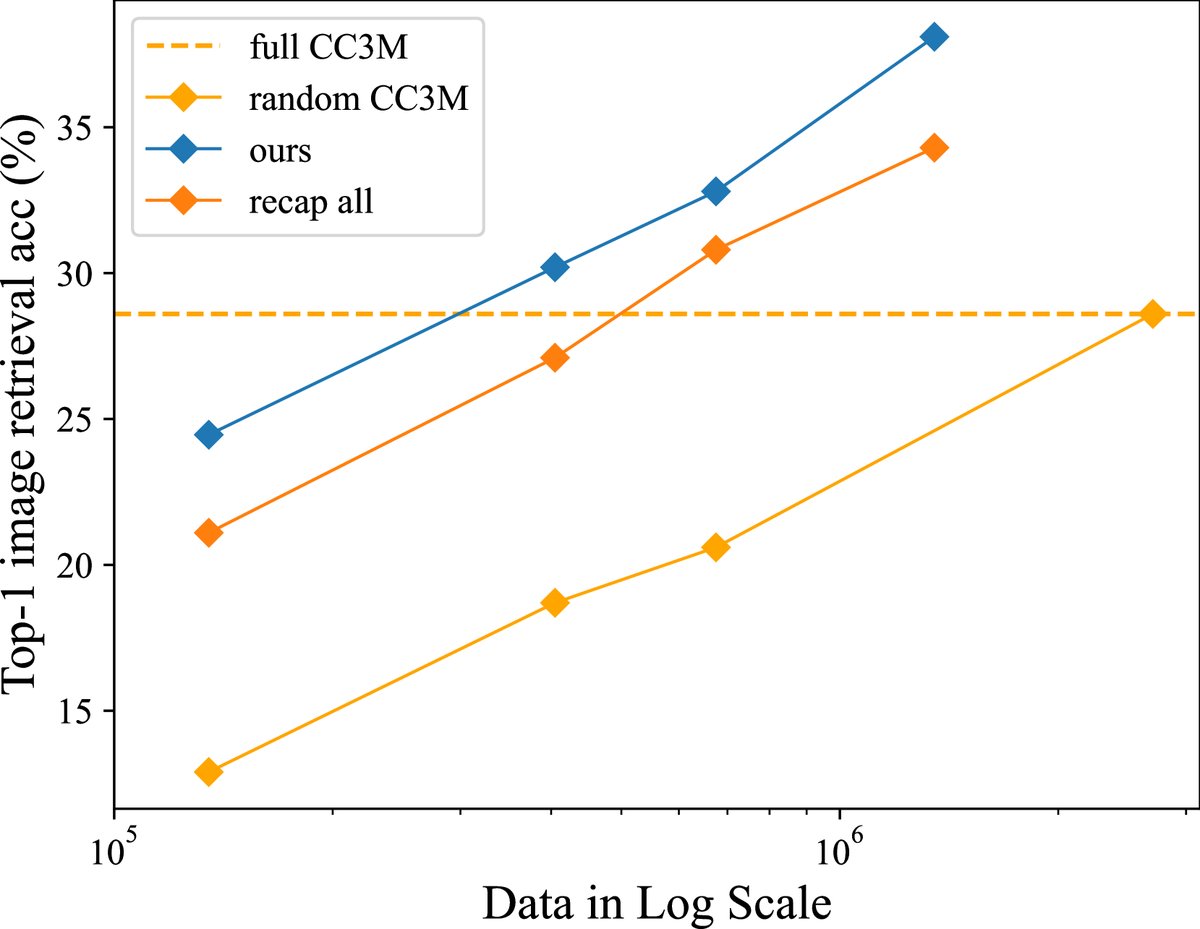
-
下游任务性能优越:如下表所示,在视觉问答 (VQA)、视觉推理 (NLVR²) 和图像描述 (COCO Captioning) 等下游任务中,使用 InfoGrowth 处理后的小规模数据(0.67M 或 1.35M)训练的模型,其性能普遍优于使用完整 2.7M 原始 CC3M 数据训练的基线模型。
| 数据集 | #样本 | VQA | NLVR2 | COCO Caption | Nocaps Validation | ||||
|---|---|---|---|---|---|---|---|---|---|
| test-dev | test-std | dev | test-P | B@4 | CIDEr | CIDEr | SPICE | ||
| Random-CC3M | 0.67M | 68.3 | 66.2 | 73.6 | 73.8 | 35.9 | 118.1 | 85.3 | 11.6 |
| CC3M | 2.7M | 71.3 | 71.4 | 75.9 | 76.5 | 36.1 | 121.4 | 90.6 | 12.8 |
| Ours | 0.67M | 70.9(-0.4) | 71.0(-0.4) | 75.4(-0.5) | 76.8(+0.3) | 36.7(+0.6) | 121.7(+0.3) | 89.8(-0.8) | 13.1(+0.3) |
| Ours | 1.35M | 71.6(+0.3) | 71.9(+0.5) | 76.1(+0.2) | 77.4(+0.9) | 36.9(+0.8) | 122.3(+0.9) | 90.6(+0.0) | 13.3(+0.5) |
2. 单模态任务 (ResNet-50 在 ImageNet-1K 数据集)
- 超越现有方法:在 ImageNet 分类任务中,InfoGrowth 在 50% 的数据剪枝率下,其性能(75.8% Acc)显著优于传统的离线数据选择方法(如 GC、EL2N)和动态剪枝方法(如 UCB),同时计算开销可控。这证明了其方法的普适性和竞争力。
| GC | EL2N-20 | UCB | InfoGrowth | Full Data | |
|---|---|---|---|---|---|
| 准确率 (%) | 72.8±0.4 | 74.6±0.4 | 75.3±0.3 | 75.8±0.3 | 76.4±0.2 |
| 训练时间 (h) | 8.75 | 8.75 | 8.75 | 8.75 | 17.5 |
| 额外开销 (h) | >24 | >17.5 | 0.03 | 0.8 | 0.0 |
| 总计 (节点*小时) | >94 | >210 | 70 | 70.8 | 140.0 |
3. 组件和鲁棒性分析
- 组件有效性:消融实验表明,清洗器(recaption)和基于增益的采样(sampling)模块对最终性能都有显著贡献,两者结合效果最佳。
- 噪声抵抗能力:即使在数据集中人为引入高达 25% 的噪声(标签随机打乱),InfoGrowth 依然能够有效去噪,并取得合理的性能,远超直接在噪声数据上训练的结果。
- 可视化分析:可视化结果直观展示了 InfoGrowth 如何识别冗余样本(如下图左)以及如何通过 $$Cleaner` 提升噪声样本的质量(如下图右)。


总结
实验结果充分验证了 InfoGrowth 作为一个在线数据策管框架的有效性和高效性。它能够在不同模态的任务中,以更少的数据和计算成本,达到甚至超越使用全量原始数据的训练效果。其高效、可扩展的设计使其成为处理未来超大规模数据集的一个极具潜力的解决方案。