DeepAgent: A General Reasoning Agent with Scalable Toolsets
-
ArXiv URL: http://arxiv.org/abs/2510.21618v1
-
作者: Zhicheng Dou; Ji-Rong Wen; Guanting Dong; Yinuo Wang; Yuan Lu; Wenxiang Jiao; Jiajie Jin; Jiarui Jin; Yutao Zhu; Xiaoxi Li; 等11人
-
发布机构: Renmin University of China; Xiaohongshu Inc.
TL;DR
本文提出DeepAgent,一个通用的端到端深度推理智能体(Agent),它将思考、动态工具发现和动作执行统一在单个连贯的推理流中,并通过自主记忆折叠机制和专门的强化学习方法ToolPO,使其能够高效利用规模可变的工具集解决复杂真实世界任务。
关键定义
- DeepAgent: 本文提出的核心智能体框架。它是一个端到端的深度推理智能体,其特点是在单一、连续的推理过程中自主地完成思考、按需搜索工具和执行动作,摆脱了传统智能体固定的“思考-行动”循环模式。
- 自主记忆折叠 (Autonomous Memory Folding): 一种让智能体在长交互过程中“喘口气”的机制。智能体可以通过生成特定指令 \(<fold-memory>\),调用一个辅助模型将之前的交互历史压缩成结构化的记忆,从而节省上下文长度、提高效率,并有机会重新审视策略以摆脱错误的探索路径。
- 脑启发记忆模式 (Brain-Inspired Memory Schema): 为支持记忆折叠而设计的结构化记忆格式。它将记忆分为三个并行的部分:情景记忆 (Episodic Memory) 记录任务关键事件和决策点;工作记忆 (Working Memory) 存储当前子目标和近期计划;工具记忆 (Tool Memory) 整合所有工具的使用记录和效果。这种基于JSON的模式确保了记忆的稳定性和可用性。
- ToolPO (Tool Policy Optimization): 本文为通用工具使用场景设计的端到端强化学习训练方法。其核心在于通过工具模拟器 (Tool Simulator) 解决训练中的API调用不稳定问题,并采用全局与工具调用优势归因 (Global and Tool-Call Advantage Attribution) 机制,将奖励精确分配给导致最终成功的全局轨迹和正确的中间工具调用动作,从而实现更高效、精准的策略学习。
相关工作
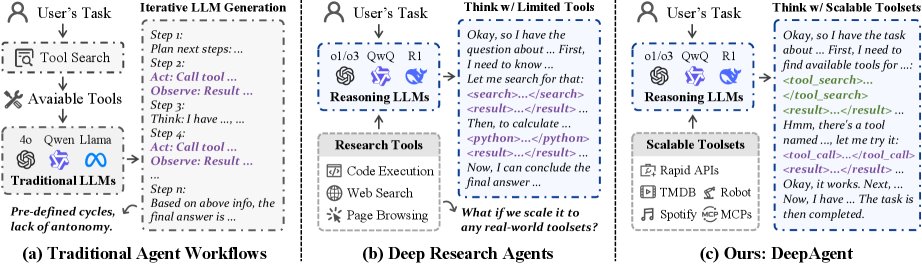
目前,由大型语言模型驱动的智能体主要依赖于预定义的工作流,如ReAct和Plan-and-Solve等方法,它们遵循固定的“推理-行动-观察”循环。这些方法的关键瓶颈在于:
- 缺乏自主性: 执行步骤和整体流程僵化,无法充分发挥大型推理模型(LRM)的自主决策能力。
- 工具集受限: 无法在任务执行过程中动态发现新工具,通常依赖于一小组预定义的工具(如网络搜索、代码执行),限制了其在多样化真实场景中的应用。
- 记忆管理不善: 缺乏对长交互历史的自主管理能力,导致上下文冗长、效率低下。
- 推理深度不足: 迭代式的局部操作使得智能体难以对整个任务进行连贯和深入的全局推理。
本文旨在解决上述问题,创建一个能够从大规模工具集中动态发现并调用工具的通用推理智能体,以应对更广泛、更复杂的真实世界任务。
本文方法
本文提出的DeepAgent框架旨在打破传统智能体僵化的工作流,通过一个统一的推理过程实现任务的端到端解决。
框架概述
DeepAgent的架构围绕一个核心的主推理过程 (Main Reasoning Process),并由一系列辅助机制 (Auxiliary Mechanisms) 支持,以确保系统的鲁棒性和效率。
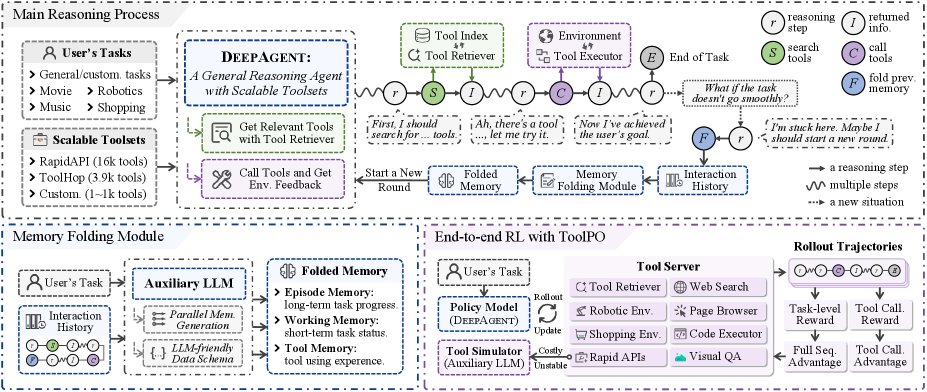
- 主推理过程: 由一个强大的大型推理模型(LRM)驱动。该模型在单一的思维流中,自主完成对任务的推理、动态发现所需工具、执行动作并管理自身记忆。这种统一的方法使LRM能始终保持对任务的全局视角。
- 辅助机制: 由一个辅助LLM负责处理与大规模工具集和长历史记录的复杂交互。该模型通过以下方式提升系统稳定性:(1) 当检索到的工具文档过长时进行过滤和总结;(2) 对工具调用返回的冗余信息进行去噪和压缩;(3) 将长交互历史压缩为结构化记忆。这种分工使主LRM能专注于高层次的战略性推理。
自主工具搜索与调用
DeepAgent的主LRM通过在其连续的推理过程中生成特定文本来执行所有动作。
工具搜索
当智能体判断需要工具时,它会生成一个封装在特殊Token内的工具搜索查询:\(<search-tool> q_s </search-tool>\)。系统采用密集检索(dense retrieval)方式。首先,使用嵌入模型 $E$ 为工具集 $\mathcal{T}$ 中每个工具 $\tau_i$ 的文档 $d_i$ 预计算嵌入 $E(d_i)$ 并建立索引。在推理时,系统根据查询 $q_s$ 与工具文档嵌入的余弦相似度检索top-k个最相关的工具:
\[\mathcal{T}_{\text{retrieved}}=\underset{\tau_{i}\in\mathcal{T}}{\text{top-k}}\left(\text{sim}(E(q_{s}),E(d_{i}))\right).\]检索到的工具文档会由辅助LLM处理(如果过长则总结),然后返回给主LRM的上下文。
工具调用
智能体通过生成一个结构化的JSON格式调用来执行工具:\(<tool-call> {"name": "tool_name", "arguments": ...} </tool-call>\)。框架解析此调用、执行工具,并捕获输出。该输出同样会由辅助LLM进行必要的总结,确保信息简洁有效,然后反馈到主LRM的推理上下文中。
自主记忆折叠与脑启发记忆模式
智能体在其推理过程的任何逻辑节点(如完成子任务或意识到探索路径错误后),可以通过生成特殊Token \(<fold-memory>\) 来触发记忆折叠。系统检测到此Token后,辅助LLM会处理之前的全部交互历史 $s_t$,并并行生成三个结构化的记忆组件:
\[(M_{E},M_{W},M_{T})=f_{\text{compress}}(s_{t};\theta_{\text{aux}}).\]这些压缩后的情景记忆 ($M_E$)、工作记忆 ($M_W$) 和工具记忆 ($M_T$) 会取代原始的交互历史,使智能体能以一个刷新和精炼的视角继续任务,同时避免陷入错误的探索路径。这种基于JSON的结构化模式确保了记忆内容的稳定性和可解析性,有效防止了在长文本摘要中可能发生的信息丢失。
端到端RL训练:ToolPO
本文采用Tool Policy Optimization (ToolPO) 对DeepAgent进行端到端训练,这是一种专为通用工具使用智能体设计的强化学习方法。
工具模拟器
由于在训练中与数千个真实世界的API交互存在不稳、延迟和成本高的问题,本文开发了一个工具模拟器 (Tool Simulator)。该模拟器由一个辅助LLM驱动,能够模仿真实API的响应,为强化学习训练提供了一个稳定、高效且低成本的环境。
全局与工具调用优势归因
ToolPO定义了两种奖励:一是任务成功奖励 $R_{\text{succ}}(\tau)$,评估最终结果的质量;二是工具调用奖励 $R_{\text{action}}(\tau)$,评估中间动作的质量,包括工具调用的正确性和记忆折叠的效率。
基于这两种奖励,计算两种相对优势:
-
任务成功优势:
\[A_{\text{succ}}(\tau_{k})=R_{\text{succ}}(\tau_{k})-\frac{1}{K}\sum\nolimits_{j=1}^{K}R_{\text{succ}}(\tau_{j}).\]该优势被归因于轨迹中的所有生成Token,提供全局学习信号。
-
动作级别优势:
\[A_{\text{action}}(\tau_{k})=R_{\text{action}}(\tau_{k})-\frac{1}{K}\sum\nolimits_{j=1}^{K}R_{\text{action}}(\tau_{j}).\]该优势仅被归因于构成工具调用和记忆折叠动作的特定Token,实现了更精细的信用分配。
优化目标
一个给定Token $y_i$ 的总优势是全局和局部优势的和:
\[A(y_{i})=A_{\text{succ}}(\tau_{k})+M(y_{i})\cdot A_{\text{action}}(\tau_{k}),\]其中 $M(y_i)$ 是一个掩码,当 $y_i$ 属于工具调用或记忆折叠序列时为1,否则为0。ToolPO使用一个裁剪的替代目标函数来优化策略:
\[\mathcal{L}_{\text{ToolPO}}(\theta)= \mathbb{E}_{\tau_{k}}\left[\sum\nolimits_{i=1}^{ \mid \tau_{k} \mid }\min\Big(\rho_{i}(\theta)A(y_{i}),\text{clip}(\rho_{i}(\theta),1-\epsilon,1+\epsilon)A(y_{i})\Big)\right],\]其中 $\rho_i(\theta)$ 是新旧策略下生成Token $y_i$ 的概率比。该目标函数鼓励模型提升那些同时带来高全局收益和正确中间行为的动作的概率,从而确保策略更新的稳定性和有效性。
实验结论
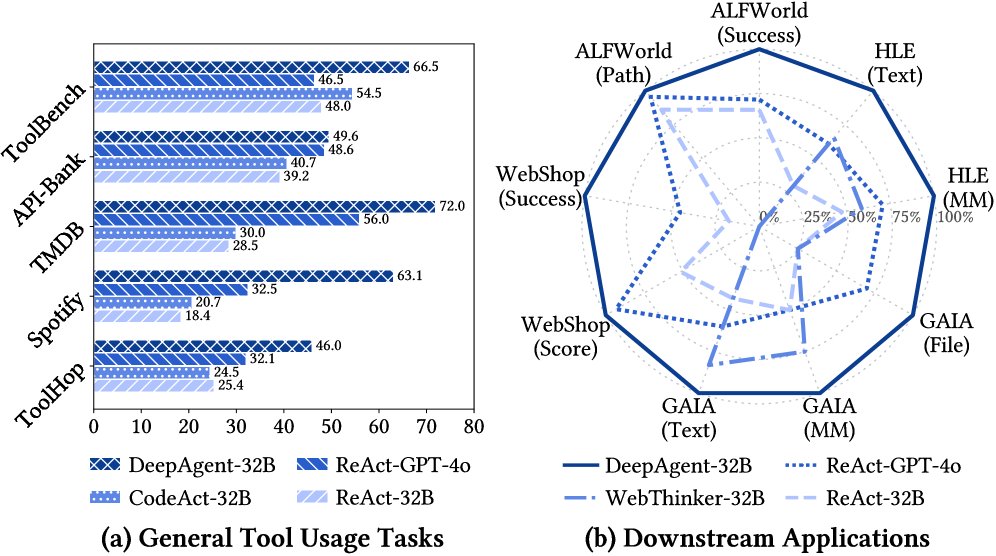
本文在涵盖通用工具使用和下游应用的八个基准测试上进行了广泛实验,结果表明DeepAgent在所有场景中均表现出卓越的性能。
通用工具使用任务结果
在含数万个工具的通用工具任务上,DeepAgent的统一推理过程显著优于基线的僵化工作流。
- 封闭工具集任务: 在TMDB和Spotify等工具集给定的任务上,DeepAgent-32B-RL的成功率分别达到89.0%和75.4%,远超最强32B基线的55.0%和52.6%。
- 开放工具集任务: 在需要动态发现工具的ToolBench和ToolHop任务上,DeepAgent的优势更加明显,成功率分别达到64.0%和40.6%,而最强基线仅为54.0%和29.0%。
下表展示了在通用工具使用任务上的详细结果,“GT Tools”表示工具已给定,“Tool Retrieval”表示需要从工具库中检索。
| 模型 | 基线 | API-Bank (GT) | ToolBench (GT) | TMDB (GT) | Spotify (GT) | ToolHop (GT) | ToolBench (Retrieval) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Success | Path | Success | Path | Success | Path | Success | Path | Correct | Path | Success | ||
| Qwen2.5-32B | ReAct | 41.0 | 64.7 | 60.4 | 68.3 | 46.0 | 65.3 | 29.8 | 56.3 | 37.6 | 49.1 | 55.0 |
| Qwen2.5-32B | CodeAct | 53.0 | 68.3 | 62.4 | 70.6 | 48.0 | 67.4 | 33.3 | 58.7 | 34.7 | 48.8 | 51.0 |
| Qwen2.5-32B | Plan-Solve | 52.0 | 65.4 | 58.4 | 67.5 | 51.0 | 71.6 | 28.1 | 54.8 | 39.2 | 49.7 | 54.0 |
| QwQ-32B | ReAct | 52.0 | 61.6 | 73.3 | 78.6 | 43.0 | 65.3 | 47.4 | 69.4 | 47.4 | 51.6 | 44.0 |
| QwQ-32B | CodeAct | 54.0 | 63.4 | 74.3 | 79.4 | 55.0 | 74.5 | 52.6 | 75.4 | 43.2 | 53.4 | 48.0 |
| QwQ-32B | Plan-Solve | 55.0 | 64.7 | 70.3 | 75.4 | 48.0 | 61.3 | 49.1 | 70.6 | 45.4 | 50.6 | 45.0 |
| DeepAgent-32B | - | 61.0 | 71.3 | 83.1 | 85.3 | 87.0 | 90.4 | 68.2 | 83.4 | 59.3 | 63.4 | 60.0 |
| DeepAgent-32B-RL | - | 66.0 | 73.5 | 85.1 | 87.3 | 89.0 | 92.4 | 75.4 | 85.6 | 61.2 | 67.4 | 64.0 |
下游应用任务结果
在需要长程规划和复杂交互的下游任务(如ALFWorld, WebShop, GAIA)上,DeepAgent同样表现出色,证明了其对真实世界应用的强大适应性。
| 模型 | 基线 | ALFWorld | WebShop | GAIA (Level 1) | HLE (Level 1) | HLE (Level 2) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Success | Path | Success | Score | Text | MM | File | All | Text | MM | All | ||
| Qwen2.5-32B | ReAct | 60.4 | 79.1 | 6.0 | 28.8 | 25.2 | 16.7 | 13.2 | 21.2 | 6.5 | 7.1 | 6.6 |
| Qwen2.5-32B | CodeAct | 65.7 | 83.3 | 12.4 | 34.5 | 28.2 | 20.8 | 18.4 | 24.8 | 7.5 | 8.0 | 7.6 |
| QwQ-32B | ReAct | 82.1 | 87.8 | 17.2 | 45.3 | 35.0 | 8.3 | 36.8 | 31.5 | 13.2 | 8.8 | 12.2 |
| QwQ-32B | CodeAct | 78.4 | 86.2 | 18.0 | 46.4 | 38.8 | 20.8 | 31.6 | 34.5 | 14.2 | 8.0 | 12.8 |
| HiRA | QwQ-32B | 84.3 | 87.6 | 23.2 | 51.9 | 44.7 | - | 42.1 | 42.5 | 14.5 | 10.6 | 13.6 |
| DeepAgent-32B | - | 86.1 | 89.5 | 25.2 | 54.5 | 45.6 | 25.0 | 44.7 | 45.5 | 15.4 | 11.2 | 14.3 |
| DeepAgent-32B-RL | - | 88.1 | 90.4 | 31.1 | 59.4 | 48.5 | 25.0 | 47.4 | 48.0 | 17.8 | 12.5 | 16.3 |
消融实验
消融实验验证了DeepAgent各个核心组件的有效性。如下表所示,移除ToolPO训练、记忆折叠、工具模拟器或工具优势归因都会导致性能下降,证明了这些设计对于实现卓越性能至关重要。
| 方法 | API-Bank | ToolBench | ToolHop | WebShop | GAIA |
|---|---|---|---|---|---|
| DeepAgent-32B-RL (Full) | 66.0 | 64.0 | 40.6 | 31.1 | 48.0 |
| w/o Training (Base) | 60.0 | 60.0 | 38.4 | 25.2 | 45.6 |
| w/o Memory Folding | 63.0 | 62.0 | 36.6 | 28.4 | 44.7 |
| w/o Tool Simulation | 62.0 | 61.0 | 35.2 | 26.6 | 46.5 |
| w/o Tool Adv. Attribution | 62.0 | 63.0 | 39.6 | 27.2 | 47.1 |
最终结论
实验结果全面证实,DeepAgent通过其统一的推理过程、自主记忆管理和创新的RL训练方法,在处理大规模工具集和复杂长程任务方面,相较于传统的、工作流固定的智能体方法取得了显著的优势,为构建更通用、更强大的AI智能体提供了新的范式。