DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL
-
ArXiv URL: http://arxiv.org/abs/2509.10446v1
-
作者: Jie Tang; Zhenyu Hou; Hanchen Zhang; Xiao Liu; Yujiang Li; Shi Feng; Rui Lu; Yuxiao Dong; Zihan Wang
-
发布机构: Northeastern University; Tsinghua University
TL;DR
本文提出了 DeepDive 方法,通过从知识图谱自动合成高难度问题,并采用端到端多轮强化学习进行训练,旨在提升大型语言模型(LLM)作为深度搜索智能体所需的长时序推理和信息检索能力。
关键定义
- 深度搜索智能体 (Deep Search Agent): 指能够整合外部浏览工具的大型语言模型。这类智能体被期望能够对来自上百个在线信息源的内容进行推理和搜索,以定位和解决复杂、答案难以查找的问题,这要求其具备长时序推理能力。
- 难寻问题 (Hard-to-find Questions): 指那些涉及多个模糊实体、需要长时序推理和深度搜索才能解答的复杂问题。这类问题与传统问答数据(如 HotpotQA)中通过几次明确实体搜索就能解决的简单问题形成鲜明对比。
- 多轮强化学习 (Multi-Turn Reinforcement Learning): 一种端到端的训练范式,允许智能体在给出最终答案前,执行多轮“思考-行动-观察”的循环。这与单轮RL不同,它能更好地训练智能体进行迭代式推理和序贯式工具调用。
- 严格奖励 (Strict Rewards): 本文设计的一种二元(0/1)奖励函数。一个轨迹只有在同时满足两个条件时才能获得+1奖励:(1) 轨迹中每一步的格式(包括思维链和工具调用)都必须完全正确;(2) 最终答案必须与标准答案完全匹配。这种设计旨在防止奖励“作弊”并确保生成高质量的轨迹。
相关工作
当前,尽管大型语言模型在数学和编程等复杂推理任务上表现出色,但在作为深度搜索智能体方面,尤其是在开源模型领域,与顶尖的专有模型(如 OpenAI DeepResearch)相比仍存在巨大差距。
研究现状的主要瓶颈可归结为两点:
- 缺乏高质量的训练数据:现有的问答数据集(如 HotpotQA)中的问题通常过于简单,无法模拟真实世界中信息分散、模糊且难以查找的“深度搜索”场景。这使得模型难以学习到真正的长时序推理和搜索能力。
- 缺乏有效的训练方法:如何将长时序推理与深度搜索工具的使用有效结合,仍然是一个开放问题。即使是强大的推理模型(如 DeepSeek-R1),在实际使用中也仅进行浅层工具调用,并且容易产生幻觉。
本文旨在解决上述两个核心问题,即通过创新的数据合成策略和训练框架,提升开源模型作为深度搜索智能体的能力。
本文方法
本文提出了 DeepDive 方法,旨在通过高质量的数据构建和端到端的强化学习训练,来提升深度搜索智能体的长时序信息获取能力。该方法包含两大核心技术:从知识图谱自动化合成问答数据,以及端到端多轮强化学习。
交互框架
本文首先建立了一个模仿人类网页浏览的交互框架,作为智能体学习的环境。智能体的每个决策遵循一个“推理-工具调用-观察”的迭代循环。在第 $t$ 步,智能体生成一段思维链 $c_{t}$,执行一个浏览动作 $a_{t}$,并观察返回的网页内容 $o_{t}$。这个过程会持续进行,直到智能体认为收集到足够信息并输出最终答案。整个任务执行过程可以表示为一个轨迹 $\mathcal{T}$:
\[\mathcal{T}=\left[q,\left(c\_{1},a\_{1},o\_{1}\right),\ldots,\left(c\_{m},a\_{m},o\_{m}\right),c\_{\mathrm{ans}},a\_{\mathrm{eos}}\right],\quad m\leq n\]智能体的动作空间包括 \(search\)、\(click\) 和 \(open\) 三种核心操作。
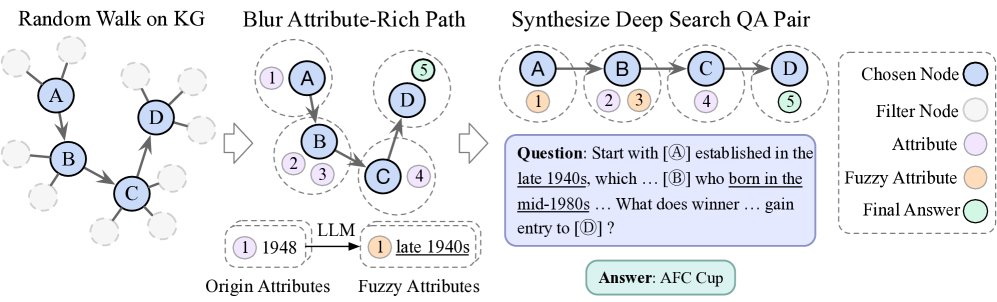
基于知识图谱的自动化数据合成
为了解决高质量训练数据稀缺的问题,本文提出了一种基于知识图谱 (Knowledge Graphs, KGs) 的自动化、可控的数据合成方法。
创新点: 使用知识图谱的优势在于其事实的可验证性、天然的多跳结构以及可控的推理难度。通过对实体属性进行选择性地模糊化,可以创造出需要模型进行迭代式推理和搜索才能解决的难题。
合成流程:
- 生成复杂路径:在知识图谱 $G=(V, E)$ 中,从一个初始节点 $v_0$ 开始进行 $k$ 步的随机游走,生成一条路径 $P=\left[v_{0},v_{1},\ldots,v_{k}\right]$。为了增加问题的复杂性,路径长度 $k$ 通常较大(如 $k>5$)。
-
属性丰富与混淆:将路径中的每个节点 $v_i$ 与其属性集合结合,形成一条富含属性的路径 $P_A$。
\[P_{A}=\left[\left(v_{0},\left[a_{0}^{0},a_{0}^{1},\ldots\right]\right),\left(v_{1},\left[a_{1}^{0},a_{1}^{1},\ldots\right]\right),\ldots,\left(v_{k},\left[a_{k}^{0},a_{k}^{1},\ldots\right]\right)\right]\]接着,从路径的末端节点 $v_k$ 中选择一个属性 $a_k^i$ 作为标准答案。
-
LLM混淆生成:利用一个强大的LLM对整条属性路径 $P_A$ 进行信息混淆(例如,将具体日期泛化为时间范围),最终生成一个具有挑战性的问答对 $(q, a_k^i)$。
\[(q,a_{k}^{i})=\text{LLM-obscure}(P_{A})\]

为了进一步提升路径质量和问题难度,本文还引入了两个约束:
- 节点出度过滤:在随机游走时,只选择出度在特定范围 $\left[d_{\min},d_{\max}\right]$ 内的候选节点,以避免路径过于简单或中断。
- LLM辅助选择:利用LLM评估候选节点与当前路径的关联性,选择最合适的下一步节点,确保路径的逻辑连贯性。
- 自动化难度过滤器:使用一个前沿模型(如 GPT-4o)对生成的问题进行尝试。只有那些该模型多次尝试均失败的问题才会被保留,确保最终数据集的挑战性。
端到端多轮强化学习
在获得高质量的问答数据后,本文采用端到端多轮强化学习 (RL) 来训练深度搜索智能体。
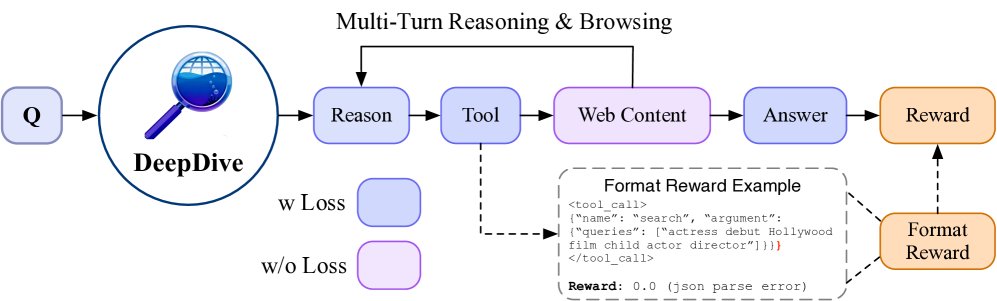
创新点: 本文采用了 GRPO (Group Relative Policy Optimization) 算法进行多轮RL训练,并设计了严格的奖励机制来引导模型学习如何在多步交互中进行有效的搜索、推理并在合适的时机终止。
训练流程:
-
GRPO 算法:对于每个问题,从当前策略 $\pi_{\theta}$ 中采样一组轨迹 $G$。对每个轨迹计算归一化优势 $A_i$,并更新策略参数 $\theta$ 以最大化一个带KL散度惩罚的裁剪目标函数:
\[\mathcal{L}(\theta)=\frac{1}{G}\sum_{i=1}^{G}\left[\min\left(\rho_{i}A_{i},\operatorname{clip}\left(\rho_{i},1-\epsilon,1+\epsilon\right)A_{i}\right)-\beta\mathrm{KL}\left(\pi_{\theta}\ \mid \pi_{\mathrm{ref}}\right)\right]\]其中 $\rho_i$ 是重要性采样比。
-
严格奖励函数:为了确保学习的有效性和鲁棒性,本文设计了一个严格的二元奖励函数。只有当轨迹中每一步的格式都正确,并且最终答案也正确时,奖励才为1,否则为0。
\[r(\mathcal{T})=\begin{cases}1,&\left(\forall\ i,\text{Format}\left(c_{i},a_{i}\right)\right)\wedge\text{Judge}\left(a_{\mathrm{eos}},a^{\*}\right)\\ 0,&\text{otherwise}\end{cases}\]同时,引入了提前退出机制,即一旦模型在任何步骤中产生格式错误,轨迹生成将立即终止并获得0奖励,这大大提高了训练效率和正样本的可靠性。
实验结论
整体性能
DeepDive 在多个具有挑战性的深度搜索基准测试中展现了卓越的性能。
- 开源模型中的领先者:在 BrowseComp 基准上,DeepDive-32B 取得了 14.8% 的准确率,创造了新的开源模型记录,远超其他同类开源智能体(如 WebSailor, Search-o1)。
- RL的显著贡献:仅经过监督微调(SFT)的 DeepDive-32B 模型(9.5%)已经能超越配备了基本浏览功能的 GPT-4o 等专有模型。而经过多轮强化学习(RL)后,模型性能得到进一步的稳定提升,证明了 RL 在融合推理与搜索方面的核心作用。
| 模型 | 推理 | 浏览 | BrowseComp | BrowseComp-ZH | Xbench-DeepSearch | SEAL-0 | | :— | :—: | :—: | :—: | :—: | :—: | :—: | | 专有模型 | | | | | | | | GPT-4o$\dagger$ | ✗ | ✓ | 1.9* | 12.8 | 30.0 | 9.1 | | Claude-3.7-Sonnet$\dagger$ | ✗ | ✓ | 4.5 | 14.2 | 29.0 | 14.4 | | o1 | ✓ | ✗ | 9.9* | 29.1* | 38.0 | 11.7 | | Claude-4-Sonnet-Thinking$\dagger$ | ✓ | ✗ | 14.7 | 30.8 | 53.0 | 37.8 | | DeepResearch | ✓ | ✓ | 51.5* | 42.9* | - | - | | 开源模型 | | | | | | | | QwQ-32B$\dagger$ | ✓ | ✓ | 1.3 | 14.5 | 27.0 | 4.5 | | DeepSeek-R1-0528 | ✓ | ✗ | 3.2 | 28.7 | 37.0 | 5.4 | | WebSailor-32B | ✓ | ✓ | 10.5* | 25.5* | 53.3* | - | | DeepDive-9B (sft-only) | ✓ | ✓ | 5.6 | 15.7 | 35.0 | 15.3 | | DeepDive-9B | ✓ | ✓ | 6.3 | 15.1 | 38.0 | 12.2 | | DeepDive-32B (sft-only) | ✓ | ✓ | 9.5 | 23.0 | 48.5 | 23.9 | | DeepDive-32B | ✓ | ✓ | 14.8 | 25.6 | 50.5 | 29.3 | 注:$\dagger$ 表示通过函数调用配备了浏览功能。
RL的作用
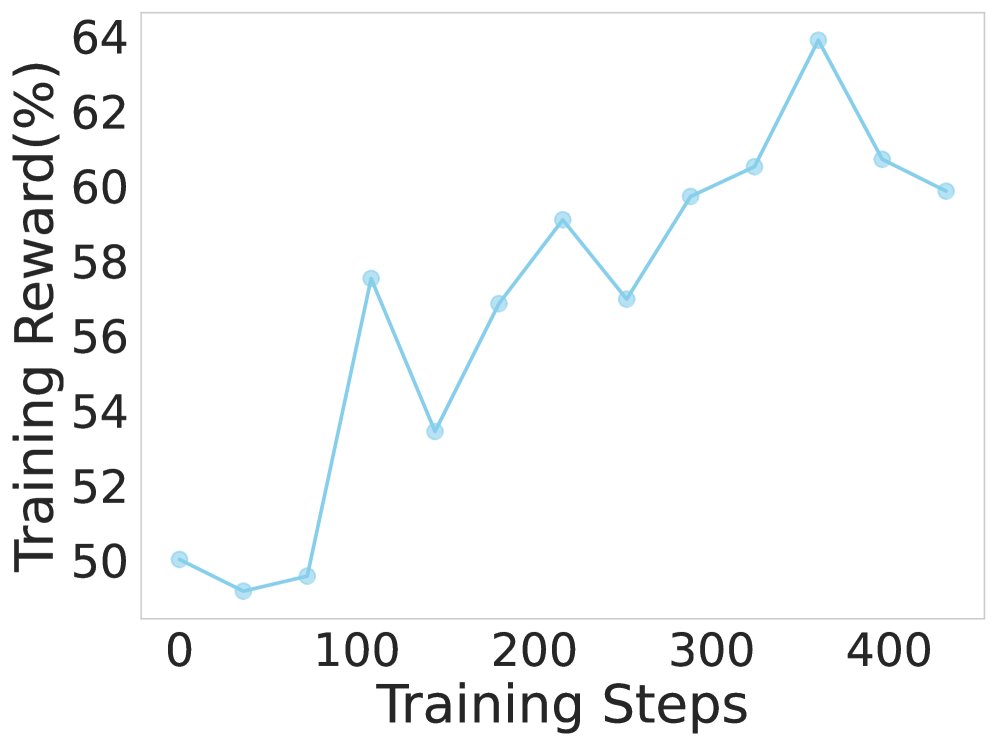
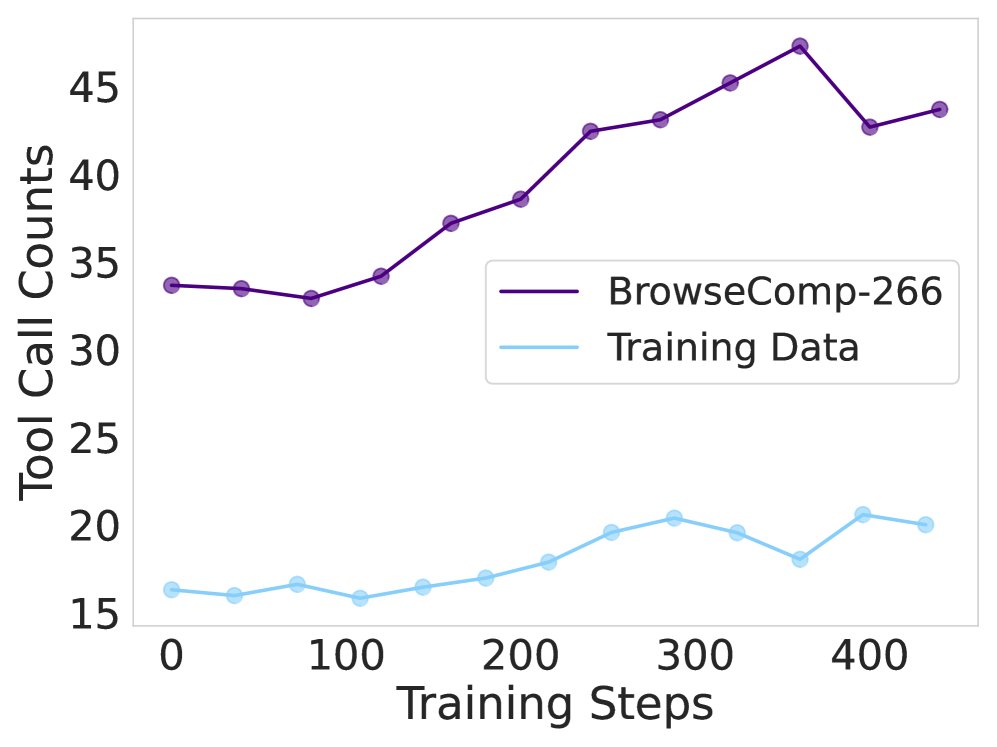
实验证明,强化学习是驱动模型进行更深度搜索的关键。
- 在 RL 训练过程中,模型的训练奖励和在验证集上的准确率都呈现出持续上升的趋势。
- 更重要的是,智能体的平均工具调用次数在训练和评估阶段都显著增加(约30%),表明 RL 成功地教会了模型采用更深入的搜索策略来解决复杂问题,并将这种能力泛化到未见过的数据上。

泛化能力与推理的重要性
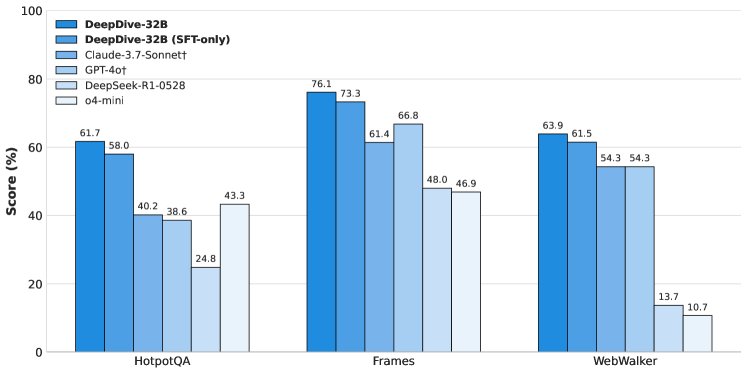
- 泛化能力:DeepDive 不仅在复杂的深度搜索任务上表现优异,在相对简单的搜索任务(如 HotpotQA, WebWalker)上也取得了 SOTA 级别的性能,表明其搜索能力具有很强的泛化性。
- 推理是基础:实验强调了强大的推理能力是深度搜索的基石。在没有浏览工具的情况下,具备强推理能力的模型(如 DeepSeek-R1-0528)表现远超非推理模型,甚至超过了一些配备了搜索功能的专有模型。这证明了本文选择强推理模型作为基座的正确性。
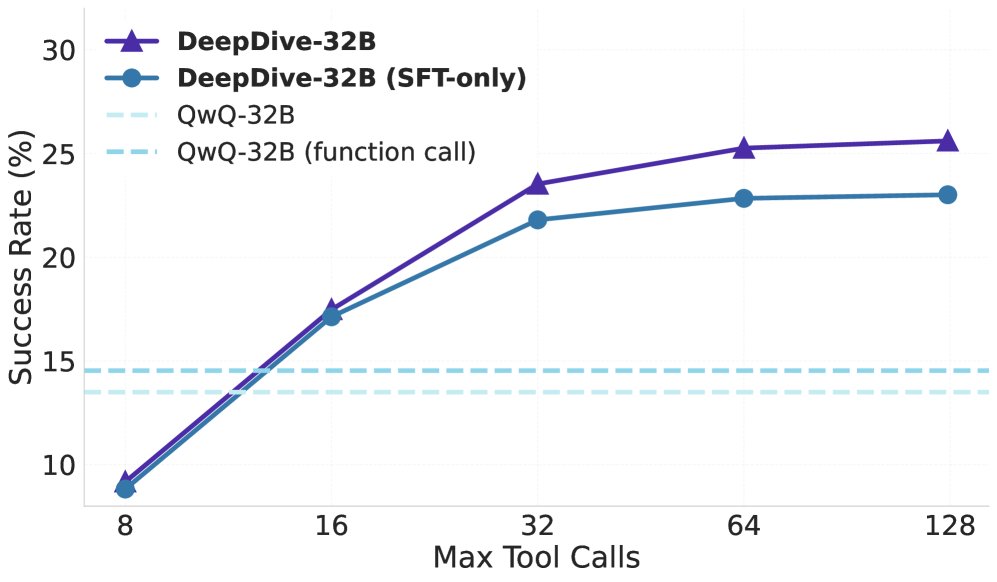
测试时扩展性
本文探索了在推理阶段通过增加计算量来提升性能的策略,即“测试时扩展 (test-time scaling)”。
- 工具调用扩展:随着允许的最大工具调用次数增加,模型在 BrowseComp 和 BrowseComp-ZH 上的准确率稳步提升。这表明给模型更长的“思考时间”(更多的交互步数)能有效提高其解决难题的能力。

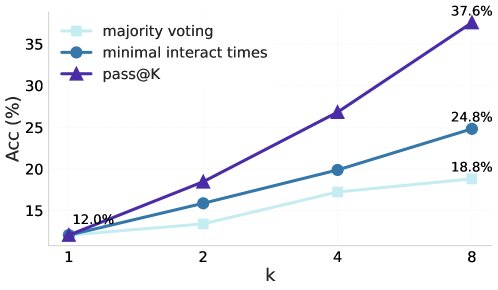
- 并行采样投票:通过为每个问题生成8个独立的解答轨迹,并采用一种新颖的投票策略——选择工具调用次数最少的那个答案——可以在 BrowseComp-266 子集上将准确率从12.0%大幅提升至24.8%。该策略远优于传统的多数投票(18.8%),其背后的洞察是:更少的调用次数通常意味着模型更快地找到了确定性高的答案。
消融研究
消融实验证实了本文提出的合成数据和训练方法的有效性。
- 无论是SFT还是RL阶段,使用本文从KG合成的数据都比使用传统数据集(如HotpotQA)带来了显著的性能提升,尤其是在准确率和平均工具调用次数两个维度上。
- 这表明本文的合成数据对于激活和训练模型的长时序深度搜索能力至关重要。
| 骨干模型 | 训练数据 | BrowseComp-266 | BrowseComp-ZH | SEAL-0 | XBench-DeepSearch | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | #Turn | Acc | #Turn | Acc | #Turn | Acc | #Turn | ||
| 监督微调 (SFT) | |||||||||
| QwQ-32B | – | 1.9 | 1.5 | 14.5 | 1.2 | 4.5 | 1.1 | 27.0 | 1.5 |
| + HotpotQA | 4.9 | 20.2 | 13.5 | 11.1 | 18.0 | 8.0 | 35.0 | 8.1 | |
| + 本文数据 | 7.5 | 32.7 | 19.0 | 24.1 | 25.2 | 13.0 | 45.5 | 15.4 | |
| 强化学习 (RL) | |||||||||
| DeepDive-32B (SFT only) | + HotpotQA | 9.2 | 33.2 | 22.7 | 23.3 | 21.6 | 13.6 | 47.0 | 15.1 |
| + 本文数据 | 12.0 | 47.2 | 25.6 | 29.1 | 29.3 | 14.9 | 50.5 | 17.5 |
附加研究:i.i.d. 数据合成
为了进一步提升在特定基准上的性能,本文进行了附加研究,采用半自动化的方式生成了与 BrowseComp 基准独立同分布(i.i.d.)的训练数据。通过让标注员在模型辅助下生成高质量的问答对,并利用这些数据进行RL训练,DeepDive-32B 在 BrowseComp 上的准确率从14.8%进一步提升至20.8%,实现了约40%的性能增长,并在中文基准上也取得了显著进步。
| 模型 | 数据 | BrowseComp | BrowseComp-ZH | Xbench-DeepSearch | SEAL-0 | | :— | :— | :—: | :—: | :—: | :—: | | DeepDive-32B (sft-only) | KG data | 9.5 | 23.0 | 48.5 | 23.9 | | DeepDive-32B | KG data | 14.8 | 25.6 | 50.5 | 29.3 | 注:使用i.i.d数据训练后,DeepDive-32B在BrowseComp上的准确率达到20.8%。