DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
-
ArXiv URL: http://arxiv.org/abs/2405.04434v5
-
作者: Zhihong Shao; Damai Dai; Bo Liu (Benjamin Liu); Huajian Xin; Zihan Wang; Daya Guo
TL;DR
本文提出了一种名为DeepSeek-V2的强混合专家(MoE)语言模型,该模型通过创新的多头潜在注意力(MLA)和DeepSeekMoE架构,在实现顶尖性能的同时,显著降低了训练成本并提升了推理效率。
关键定义
- 混合专家模型 (Mixture-of-Experts, MoE):一种神经网络架构,其中包含多个“专家”子网络。对于每个输入token,一个路由网络会选择一小部分(通常是2个或更多)专家来处理它。这使得模型总参数量可以非常大,但每个token的计算成本(激活参数量)却很低。
- 多头潜在注意力 (Multi-head Latent Attention, MLA):本文提出的一种创新的注意力机制。其核心思想是通过低秩键值联合压缩(low-rank key-value joint compression),将大量的Key和Value信息压缩到一个低维的“潜在向量”中,从而在推理时大幅减少KV缓存,提升生成速度和吞吐量。
- DeepSeekMoE:本文采用的一种MoE架构。它通过“细粒度专家分割”(将专家切分得更小)和“共享专家隔离”(引入所有token都使用的共享专家)来提升专家特化能力和减少知识冗余,从而以更经济的成本训练出性能更强的模型。
- 解耦的旋转位置嵌入 (Decoupled Rotary Position Embedding, RoPE):为解决标准RoPE与MLA的低秩压缩不兼容的问题,本文提出的一种策略。它使用额外的多头查询和共享的键来专门承载RoPE,从而使位置信息能够被正确编码,同时不破坏MLA的推理效率优势。
相关工作
大语言模型(LLMs)的智能水平通常随参数量增加而提升,但这带来了巨大的训练计算成本和推理效率瓶颈,阻碍了其广泛应用。
为了提升推理效率,研究人员探索了多种减少注意力机制中键值(Key-Value, KV)缓存的方法,例如分组查询注意力(Grouped-Query Attention, GQA)和多查询注意力(Multi-Query Attention, MQA)。然而,这些方法在减少KV缓存的同时,往往会带来模型性能的损失。在模型训练成本方面,传统的稠密(Dense)模型训练成本高昂,而MoE模型虽然能降低计算量,但其路由策略、负载均衡和通信开销是需要解决的关键挑战。
本文旨在解决这一核心矛盾:如何在不牺牲模型性能的前提下,同时实现经济的训练成本和高效的推理效率。
本文方法
DeepSeek-V2的整体架构仍是Transformer,但其在注意力和前馈网络(FFN)两个核心模块上进行了根本性创新,分别引入了MLA和DeepSeekMoE。
 图注: DeepSeek-V2的架构图。MLA通过显著减少生成过程中的KV缓存来保证高效推理,而DeepSeekMoE通过稀疏架构以经济的成本训练出强大模型。
图注: DeepSeek-V2的架构图。MLA通过显著减少生成过程中的KV缓存来保证高效推理,而DeepSeekMoE通过稀疏架构以经济的成本训练出强大模型。
Multi-Head Latent Attention (MLA):提升推理效率
标准的多头注意力(MHA)在生成任务中需要缓存所有历史token的Key和Value,这导致KV缓存成为制约推理效率(尤其是长序列)的主要瓶颈。MLA通过以下设计解决了这个问题。
创新点:低秩键值联合压缩
MLA的核心是将高维的Key和Value向量通过一个“瓶颈”结构联合压缩成一个低维的潜在向量 \($\mathbf{c}\_{t}^{KV}\)$。
\[\mathbf{c}_{t}^{KV} = W^{DKV}\mathbf{h}_{t}\]其中 \($\mathbf{h}\_{t}\)$ 是输入,\($W^{DKV}\)$ 是下采样投影矩阵。之后,再从这个压缩的潜在向量中重构出Key和Value。
\[\mathbf{k}_{t}^{C} = W^{UK}\mathbf{c}_{t}^{KV}\] \[\mathbf{v}_{t}^{C} = W^{UV}\mathbf{c}_{t}^{KV}\]在推理时,模型只需缓存这个低维的 \($\mathbf{c}\_{t}^{KV}\)$,从而极大地减少了显存占用。同时,投影矩阵 \($W^{UK}\)$ 和 \($W^{UV}\)$ 可以被数学上吸收到其他线性层中,不增加额外的计算。
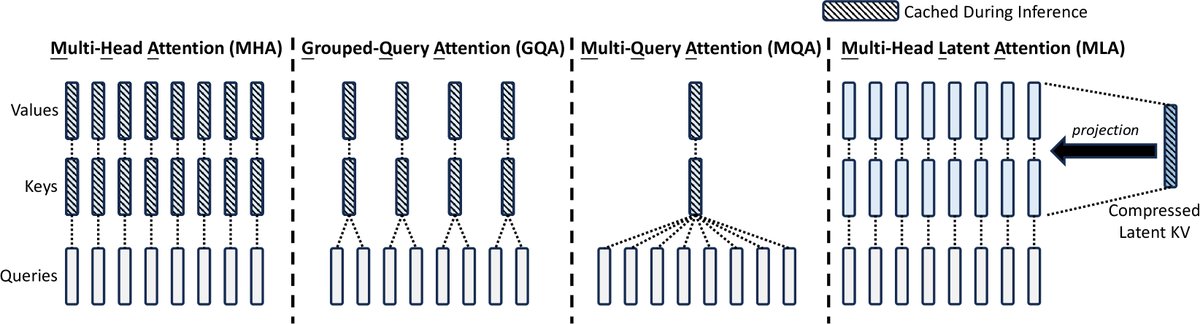 图注: MHA、GQA、MQA和MLA的简化对比。MLA通过将Key和Value联合压缩到一个潜在向量中,显著减少了推理时的KV缓存。
图注: MHA、GQA、MQA和MLA的简化对比。MLA通过将Key和Value联合压缩到一个潜在向量中,显著减少了推理时的KV缓存。
创新点:解耦的旋转位置嵌入
标准RoPE直接作用于Key和Query,与MLA的压缩机制不兼容,会导致推理时无法利用缓存,效率急剧下降。为此,本文设计了“解耦RoPE”,引入了专门用于承载位置信息的额外查询 \($\mathbf{q}\_{t,i}^{R}\)$ 和一个共享的键 \($\mathbf{k}\_{t}^{R}\)$。
\[\mathbf{q}_{t,i} = [\mathbf{q}_{t,i}^{C}; \mathbf{q}_{t,i}^{R}]\] \[\mathbf{k}_{t,i} = [\mathbf{k}_{t,i}^{C}; \mathbf{k}_{t}^{R}]\]RoPE仅应用于 \($\mathbf{q}\_{t,i}^{R}\)$ 和 \($\mathbf{k}\_{t}^{R}\)$。这样,位置信息得以保留,同时核心的KV压缩 \($\mathbf{c}\_{t}^{KV}\)$ 保持与位置无关,保证了推理效率。
优点
如下表所示,MLA在实现比MHA更强性能的同时,其KV缓存大小与仅有2.25个组的GQA相当,远小于标准MHA。
| 注意力机制 | 每个token的KV缓存大小 (# 元素) | 能力 |
|---|---|---|
| 多头注意力 (MHA) | \($2n\_hd\_hl\)$ | 强 |
| 分组查询注意力 (GQA) | \($2n\_gd\_hl\)$ | 中等 |
| 多查询注意力 (MQA) | \($2d\_hl\)$ | 弱 |
| MLA (本文) | \($(d\_c+d\_h^R)l \approx \frac{9}{2}d\_hl\)$ | 更强 |
表注: DeepSeek-V2中 \($d\_c = 4d\_h\)$ 且 \($d\_h^R = d\_h/2\)$。
DeepSeekMoE:以经济成本训练强模型
对于FFN层,模型采用了DeepSeekMoE架构,它有两个核心思想:
- 细粒度专家分割:将专家切分得更小,以实现更精准的知识学习和更高的特化潜力。
- 共享专家隔离:引入少量(2个)共享专家,所有token都会经过它们进行计算,用于学习通用知识,从而减少被路由专家之间的知识冗余。
其计算公式为:
\[\mathbf{h}_{t}^{\prime} = \mathbf{u}_{t} + \sum_{i=1}^{N_{s}}{\operatorname{FFN}^{(s)}_{i} \left(\mathbf{u}_{t}\right)} + \sum_{i=1}^{N_{r}}{g_{i,t}\operatorname{FFN}^{(r)}_{i}\left(\mathbf{u}_{t}\right)}\]其中 \($\operatorname{FFN}^{(s)}\)$ 是共享专家,\($\operatorname{FFN}^{(r)}\)$ 是被路由的专家,\($g\_{i,t}\)$ 是门控值,决定了每个token激活哪些路由专家(Top-K)。
创新点:训练优化
为了高效训练DeepSeekMoE,本文设计了三个关键机制:
- 设备受限的路由 (Device-Limited Routing):在专家并行训练时,限制每个token最多只能将计算任务分发到 \($M\)$ 个不同的设备(GPU)上(本文 \($M=3\)$),从而控制了通信开销的上限。
- 负载均衡的辅助损失 (Auxiliary Loss for Load Balance):设计了三个辅助损失函数来确保负载均衡:
- \($\mathcal{L}\_{\mathrm{ExpBal}}\)$:专家级损失,防止部分专家过载或饥饿。
- \($\mathcal{L}\_{\mathrm{DevBal}}\)$:设备级损失,确保不同设备间的计算负载均衡。
- \($\mathcal{L}\_{\mathrm{CommBal}}\)$:通信级损失,确保设备间的通信数据量均衡。
- Token丢弃策略 (Token-Dropping Strategy):在训练时,对于超出设备计算容量的token,会根据其与专家的亲和度分数(affinity score)丢弃分数最低的token,以进一步缓解负载不均导致的计算资源浪费。
实验结论
预训练与效率
- 模型性能:DeepSeek-V2(236B总参数,21B激活参数)在广泛的中英文基准测试中,性能全面超越了之前的DeepSeek 67B模型,并在开源模型中达到顶尖水平。
- 与Qwen1.5 72B相比,在多数英文、代码和数学基准上优势明显。
- 与Mixtral 8x22B相比,在MMLU等关键基准上更优,中英文能力更强。
- 与LLaMA3 70B相比,尽管英文训练数据更少,但在代码和数学能力上仍具可比性,中文能力则遥遥领先。
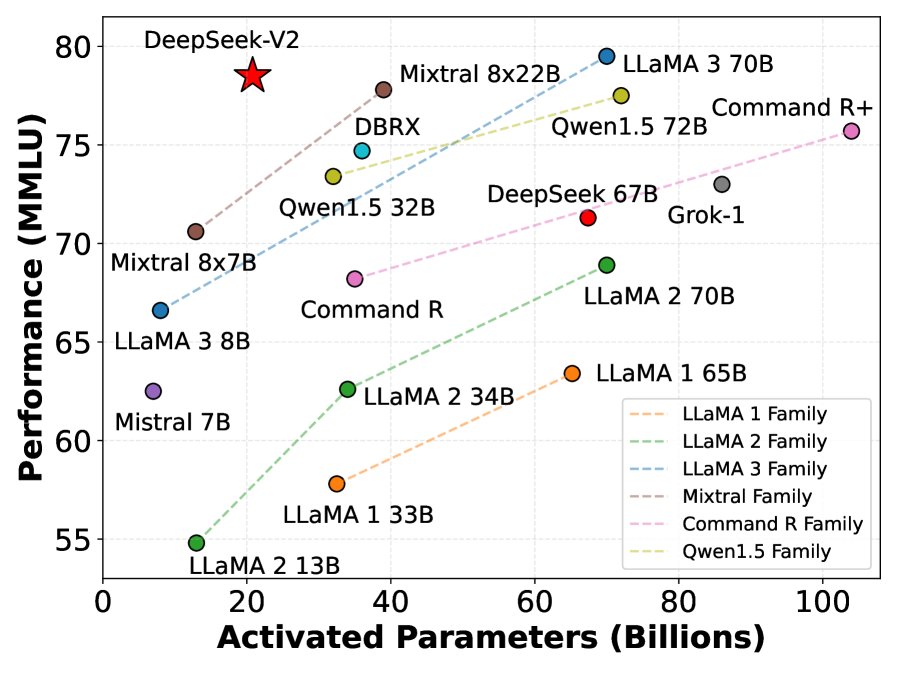
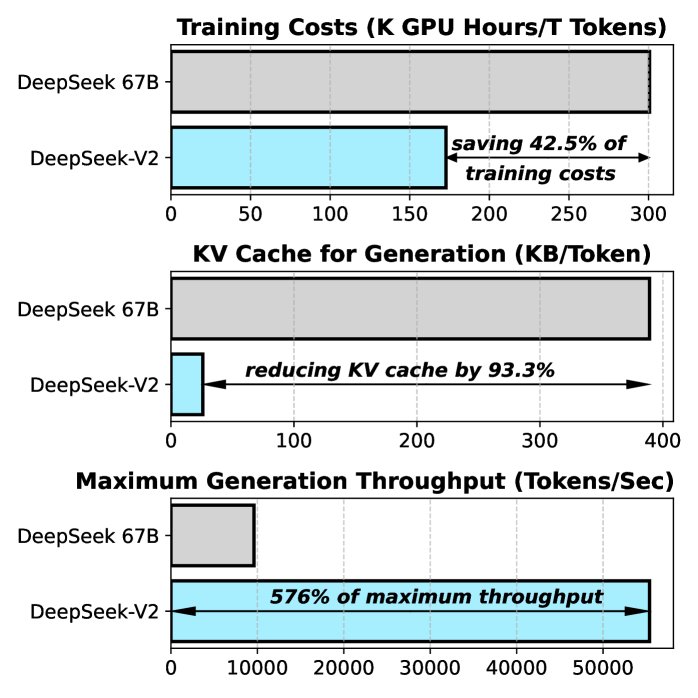 图注: (a) 不同开源模型在MMLU上的准确率与激活参数对比。(b) DeepSeek 67B(稠密模型)与DeepSeek-V2的训练成本和推理效率对比。
图注: (a) 不同开源模型在MMLU上的准确率与激活参数对比。(b) DeepSeek 67B(稠密模型)与DeepSeek-V2的训练成本和推理效率对比。
- 训练与推理效率:
- 训练成本:相较于DeepSeek 67B,DeepSeek-V2的训练成本节省了42.5%。
- 推理效率:得益于MLA,部署时(使用FP8参数和KV缓存量化)KV缓存减少了93.3%,最大生成吞吐量提升至DeepSeek 67B的5.76倍,达到每秒超过5万个token。
- 长上下文能力:通过YaRN方法,模型上下文窗口从4K扩展到128K。在“大海捞针”(NIAH)测试中,DeepSeek-V2在高达128K的上下文长度内均表现出色。
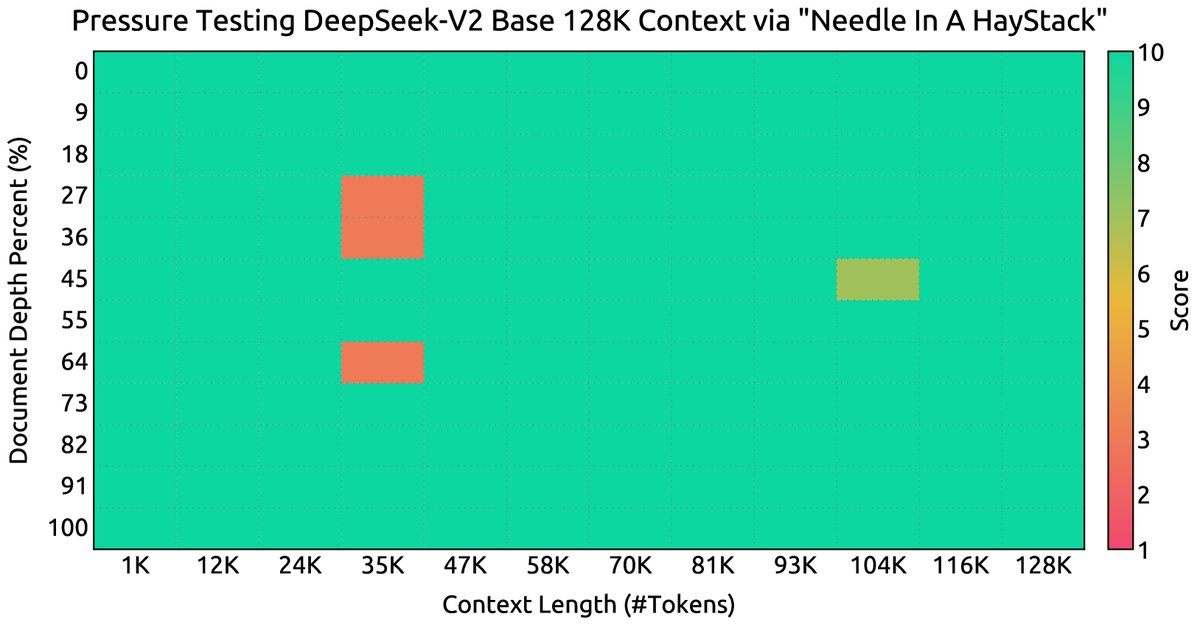 图注: DeepSeek-V2在不同上下文长度下的NIAH测试结果,展现了优异的长文本处理能力。
图注: DeepSeek-V2在不同上下文长度下的NIAH测试结果,展现了优异的长文本处理能力。
| DeepSeek | Qwen1.5 | Mixtral | LLaMA 3 | DeepSeek-V2 | |||
|---|---|---|---|---|---|---|---|
| 基准 (指标) | # Shots | 67B | 72B | 8x22B | 70B | ||
| 架构 | - | 稠密 | 稠密 | MoE | 稠密 | MoE | |
| 激活参数 | - | 67B | 72B | 39B | 70B | 21B | |
| 总参数 | - | 67B | 72B | 141B | 70B | 236B | |
| 英语 | MMLU (Acc.) | 5-shot | 71.3 | 77.2 | 77.6 | 78.9 | 78.5 |
| BBH (EM) | 3-shot | 68.7 | 59.9 | 78.9 | 81.0 | 78.9 | |
| 代码 | HumanEval (Pass@1) | 0-shot | 45.1 | 43.9 | 53.1 | 48.2 | 48.8 |
| MBPP (Pass@1) | 3-shot | 57.4 | 53.6 | 64.2 | 68.6 | 66.6 | |
| 数学 | GSM8K (EM) | 8-shot | 63.4 | 77.9 | 80.3 | 83.0 | 79.2 |
| MATH (EM) | 4-shot | 18.7 | 41.4 | 42.5 | 42.2 | 43.6 | |
| 中文 | C-Eval (Acc.) | 5-shot | 66.1 | 83.7 | 59.6 | 67.5 | 81.7 |
| CMMLU (Acc.) | 5-shot | 70.8 | 84.3 | 60.0 | 69.3 | 84.0 |
对齐微调
- SFT与RL:经过监督微调(SFT)和基于GRPO算法的强化学习(RL)后,DeepSeek-V2 Chat模型在对话能力上表现优异。
- 对话能力:在AlpacaEval 2.0、MT-Bench等开放式对话评测中,DeepSeek-V2 Chat (RL) 版本在英文对话方面达到开源模型顶尖水平,在中文AlignBench上则超越了所有开源及大部分闭源模型。
最终结论
DeepSeek-V2成功地证明了,通过创新的模型架构设计(MLA和DeepSeekMoE),可以在大幅降低训练与推理成本的同时,构建出性能处于顶尖水平的大语言模型。这为未来开发更强大、更经济、更易于部署的AI模型提供了新的范式。