DeepSeek-V3 Technical Report
-
ArXiv URL: http://arxiv.org/abs/2412.19437v2
-
作者: K. Yu; Bei Feng; Yuting Yan; Yanping Huang; Shiyu Wang; Jingchang Chen; Xiaodong Liu; Yu-Wei Luo; Jingyang Yuan; Zhean Xu; 等186人
TL;DR
本文提出了一种名为 DeepSeek-V3 的671B参数的强混合专家(MoE)模型,它通过创新的无辅助损失负载均衡策略、多Token预测训练目标以及高效的MLA和DeepSeekMoE架构,以极高的训练效率和经济成本,实现了与顶级闭源模型相媲美的性能。
关键定义
本文的核心创新和关键技术主要建立在以下几个概念之上:
- 多头潜在注意力 (Multi-head Latent Attention, MLA):一种高效的注意力机制,通过对键(K)和值(V)进行低秩联合压缩,大幅减少推理过程中的KV缓存大小,同时保持与标准多头注意力(MHA)相当的性能。这是实现高效推理的核心。
- 带无辅助损失负载均衡的DeepSeekMoE (DeepSeekMoE with Auxiliary-Loss-Free Load Balancing):一种改进的混合专家(MoE)架构。其创新点在于不使用传统的辅助损失函数来平衡专家负载,而是为每个专家引入一个动态调整的偏置项 \(b_i\) 来指导路由决策,从而在保证负载均衡的同时,最小化对模型性能的负面影响。
- 多Token预测 (Multi-Token Prediction, MTP):一种新的训练目标,它在每个位置上不仅预测下一个Token,还通过多个顺序的MTP模块预测未来的多个Token。这种设计通过保持完整的因果链来增强训练信号的密度,旨在提升模型性能和数据效率。
- DualPipe算法:一种为解决MoE模型中跨节点通信瓶颈而设计的创新流水线并行算法。它通过重叠计算和通信阶段,并采用双向流水线调度,显著减少了流水线气泡和通信开销,实现了近乎完全的计算-通信重叠。
- 细粒度FP8训练 (Fine-Grained FP8 Training):一种为实现极致训练效率而设计的低精度训练框架。它通过在更细的粒度上(对激活进行tile-wise分组,对权重进行block-wise分组)进行量化,并改进GEMM的累积精度,首次在超大规模模型上成功验证了FP8训练的可行性和有效性。
相关工作
近年来,大型语言模型(LLMs)发展迅速,开源模型(如LLaMA、Qwen、Mistral系列)也在努力追赶顶尖的闭源模型(如GPT-4、Claude系列)。然而,这一领域面临两大关键瓶颈:
- 性能差距:开源模型与最先进的闭源模型在综合能力上仍存在差距,特别是在复杂的推理、代码和数学等领域。
- 训练成本:训练一个性能强大的大规模模型通常需要巨大的计算资源和时间,高昂的成本限制了社区的研究和发展。
本文旨在解决上述问题,其核心目标是:在大幅降低训练成本、提升训练效率的前提下,构建一个性能卓越的开源MoE模型(DeepSeek-V3),以缩小与业界领先闭源模型之间的差距。
本文方法
DeepSeek-V3的架构和训练方法在继承DeepSeek-V2高效设计的基础上,引入了多项关键创新,旨在同时优化模型性能和训练/推理效率。
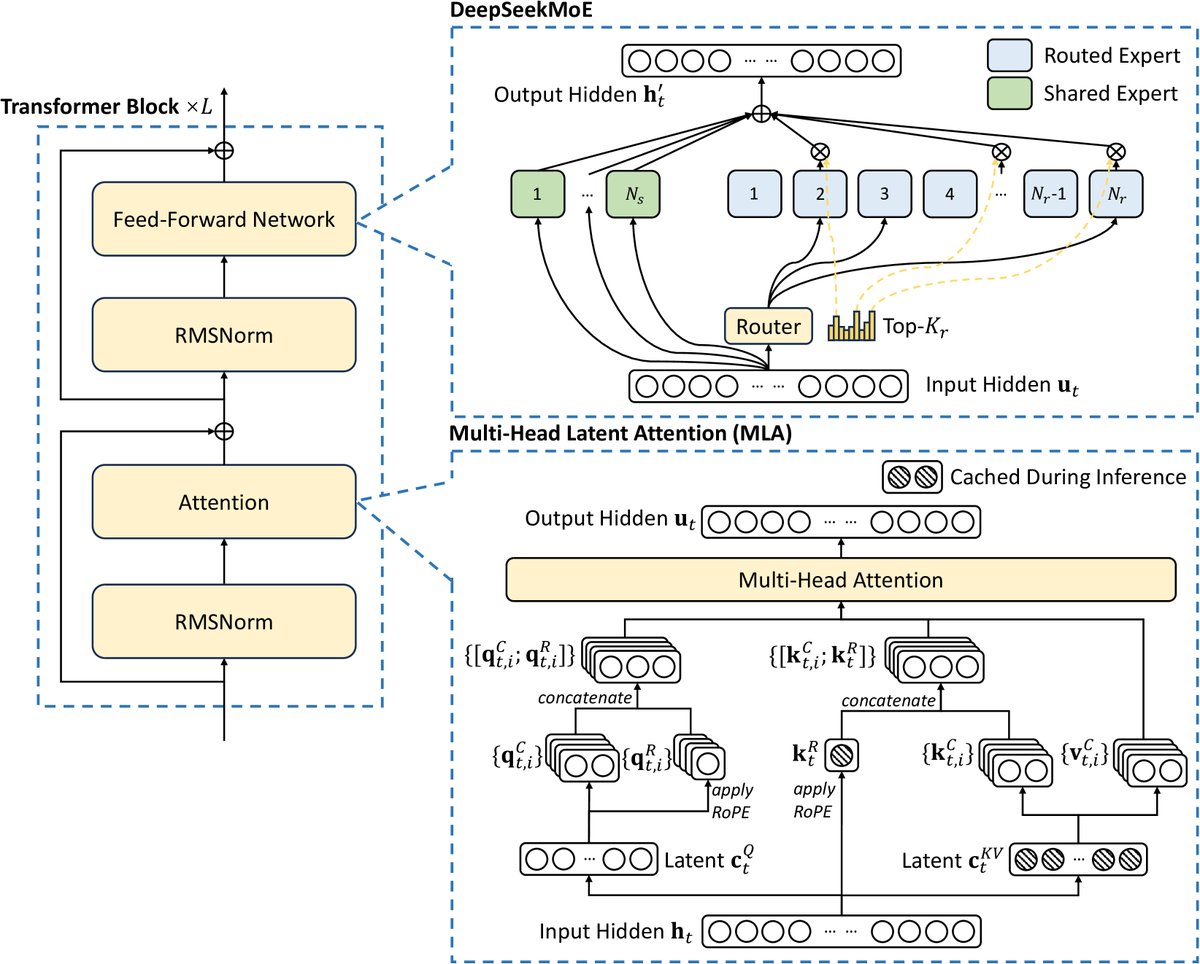 图注:DeepSeek-V3 的基础架构示意图。沿用 DeepSeek-V2 的 MLA 和 DeepSeekMoE 实现高效推理和经济的训练。
图注:DeepSeek-V3 的基础架构示意图。沿用 DeepSeek-V2 的 MLA 和 DeepSeekMoE 实现高效推理和经济的训练。
架构创新
多头潜在注意力 (MLA)
为了实现高效推理,DeepSeek-V3沿用了MLA架构。其核心思想是压缩KV缓存。对于每个token \(t\) 的输入 \(\mathbf{h}_{t}\),MLA首先将其压缩成一个低维的潜向量 \(\mathbf{c}_{t}^{KV}\),然后从此潜向量上投影生成大部分的键(K)和值(V)。
\[\mathbf{c}_{t}^{KV} = W^{DKV}\mathbf{h}_{t}\]此外,为了保留位置信息,MLA会独立生成一小部分携带旋转位置编码(RoPE)的键 \(\mathbf{k}_{t}^{R}\)。最终的KV缓存只需存储压缩后的 \(\mathbf{c}_{t}^{KV}\) 和 \(\mathbf{k}_{t}^{R}\),从而大幅减小了显存占用。
DeepSeekMoE与无辅助损失的负载均衡
对于前馈网络(FFN),模型采用了DeepSeekMoE架构,它包含共享专家(Shared Experts)和路由专家(Routed Experts)两部分。
\[\mathbf{h}_{t}^{\prime} = \mathbf{u}_{t} + \sum_{i=1}^{N_{s}}{\operatorname{FFN}^{(s)}_{i} \left(\mathbf{u}_{t}\right)} + \sum_{i=1}^{N_{r}}{g_{i,t}\operatorname{FFN}^{(r)}_{i}\left(\mathbf{u}_{t}\right)}\]创新点:本文摒弃了传统的通过辅助损失函数来强制专家负载均衡的方法,因为这种方法可能损害模型性能。取而代之的是一种无辅助损失的负载均衡策略。该策略为每个专家引入一个偏置项 \(b_i\),在路由决策时将其加到亲和度分数 \(s_{i,t}\) 上进行Top-K选择:
\[g^{\prime}_{i,t} = \begin{cases}s_{i,t},&s_{i,t}+b_{i}\in\operatorname{Topk}(\{s_{j ,t}+b_{j} \mid 1\leqslant j\leqslant N_{r}\},K_{r}),\\ 0,&\text{otherwise}.\end{cases}\]偏置项 \(b_i\) 在每个训练步后动态调整:如果一个专家过载,则减小其偏置;如果欠载,则增加其偏置。这种方法在不引入额外损失的情况下有效维持了负载均衡。此外,模型还采用了一个权重极小的序列级平衡损失作为补充,并使用节点限制路由 (Node-Limited Routing) 机制来限制通信成本,保证训练效率。
多Token预测 (MTP)
为了增强训练信号,DeepSeek-V3引入了MTP训练目标。与传统只预测下一个token不同,MTP会预测未来的 \(D\) 个token。 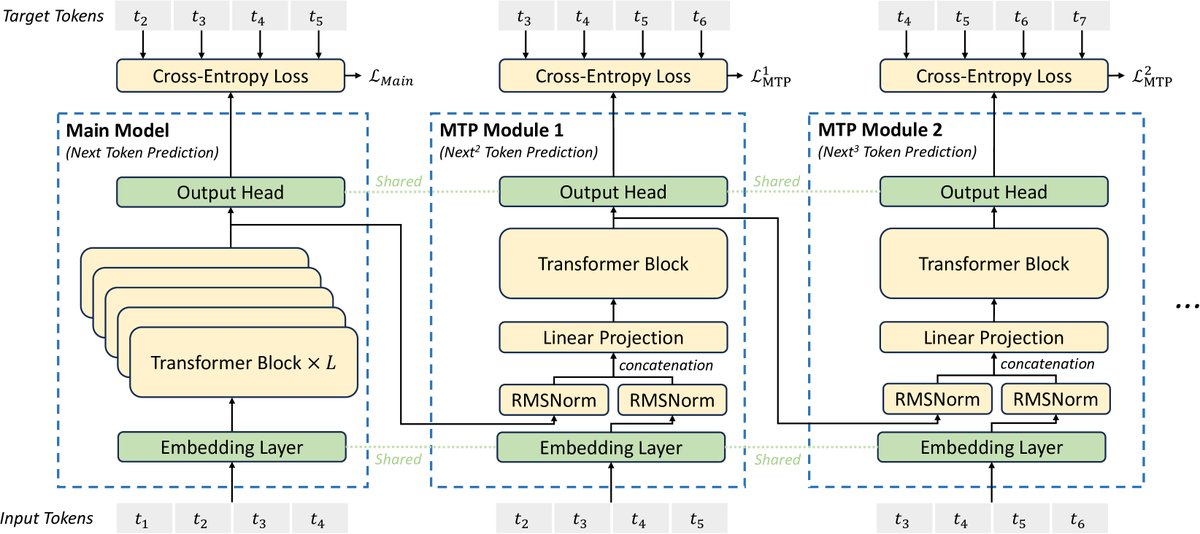 图注:MTP实现示意图。在每个预测深度上为每个token的预测保留了完整的因果链。
图注:MTP实现示意图。在每个预测深度上为每个token的预测保留了完整的因果链。
实现方式:MTP由 \(D\) 个顺序的模块构成。第 \(k\) 个MTP模块接收来自第 \(k-1\) 个模块的隐藏状态 \(\mathbf{h}_{i}^{k-1}\) 和真实目标token \(t_{i+k}\) 的嵌入,通过一个Transformer块来预测第 \(i+k+1\) 个token。这种设计保持了完整的因果关系链,让模型能够“预先规划”其表示。
\[\mathcal{L}_{\text{MTP}} = \frac{\lambda}{D}\sum_{k=1}^{D}\mathcal{L}_{\text{MTP}}^{k}\]这个MTP损失作为主损失函数的补充,共同优化模型。在推理时,MTP模块可以被丢弃,也可以用于推测解码来加速生成。
训练效率优化
训练框架与DualPipe算法
DeepSeek-V3的训练基于自研的HAI-LLM框架,采用了16路流水线并行(PP)、64路专家并行(EP)和ZeRO-1数据并行(DP)的混合并行策略。
核心创新:DualPipe算法。为了解决MoE跨节点通信开销大的问题(计算通信比接近1:1),本文设计了DualPipe算法。它将每个计算块细分为Attention、MLP和All-to-all通信等部分,并巧妙地重新排列前向和反向传播中的这些子任务,实现了计算与通信的高度重叠。  图注:一对前向和反向块的重叠策略。All-to-all和PP通信都可以被完全隐藏。
图注:一对前向和反向块的重叠策略。All-to-all和PP通信都可以被完全隐藏。
DualPipe采用双向流水线调度,同时从流水线的两端输入微批次数据,显著减少了流水线气泡。与1F1B等方法相比,DualPipe在略微增加激活内存的情况下,大幅减少了等待时间。
 图注:8个PP rank和20个微批次的DualPipe调度示例。
图注:8个PP rank和20个微批次的DualPipe调度示例。
| 方法 | 气泡时间 (Bubble) | 参数内存 | 激活内存 |
|---|---|---|---|
| 1F1B | $(PP-1)(F+B)$ | $1\times$ | $PP$ |
| ZB1P | $(PP-1)(F+B-2W)$ | $1\times$ | $PP$ |
| DualPipe (Ours) | $(\frac{PP}{2}-1)(F\&B+B-3W)$ | $2\times$ | $PP+1$ |
表注:不同流水线并行方法的开销比较。
FP8混合精度训练
本文首次在671B规模的模型上成功应用了FP8混合精度训练,极大地提升了训练速度并降低了显存占用。 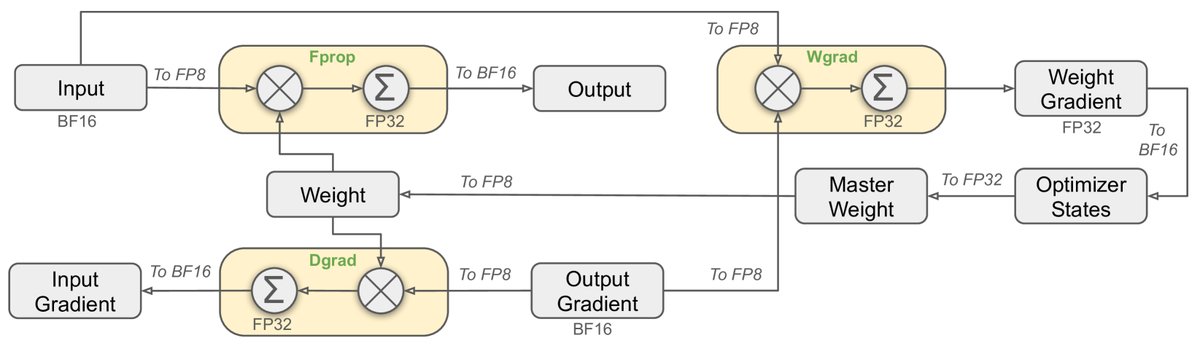 图注:FP8混合精度框架示意图,此处以线性算子为例。
图注:FP8混合精度框架示意图,此处以线性算子为例。
创新点:
-
细粒度量化 (Fine-Grained Quantization):为解决FP8动态范围有限易受异常值影响的问题,本文采用了细粒度量化策略。对激活函数按 \(1x128\) 的tile-wise方式进行分组缩放,对权重按 \(128x128\) 的block-wise方式进行分组缩放。这种方法有效隔离了异常值的影响。
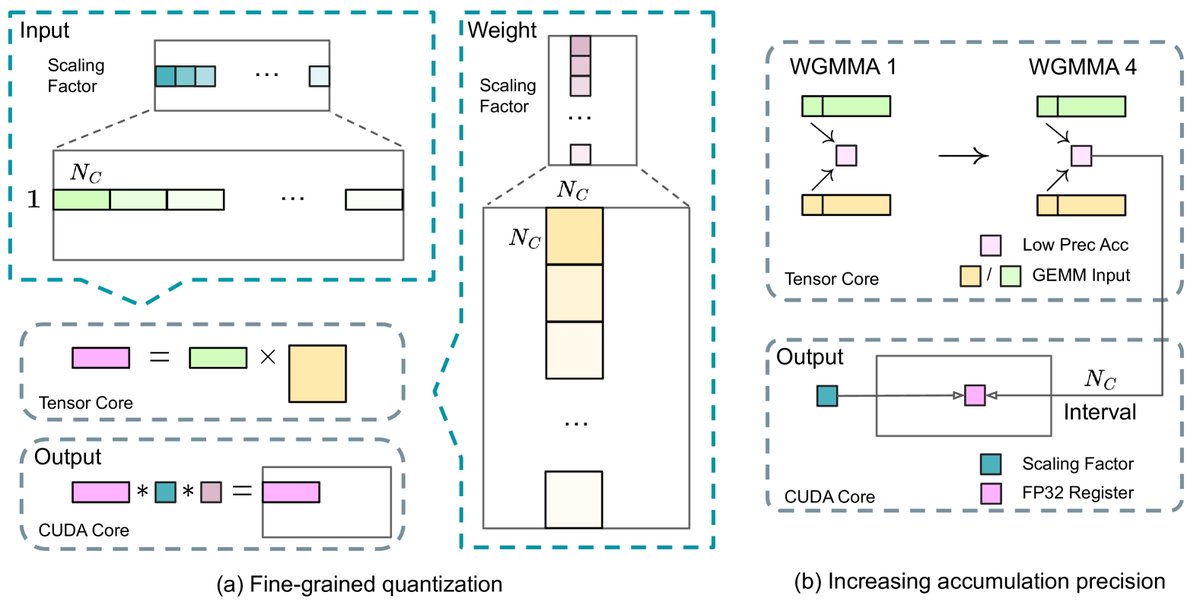 图注:(a) 细粒度量化减轻异常值导致的量化误差;(b) 结合量化策略,通过在CUDA核上进行高精度累积来提升FP8 GEMM精度。
图注:(a) 细粒度量化减轻异常值导致的量化误差;(b) 结合量化策略,通过在CUDA核上进行高精度累积来提升FP8 GEMM精度。 -
提升累积精度 (Increasing Accumulation Precision):标准的FP8 GEMM在H800上的累积精度有限。本文通过在Tensor Core执行一定数量的矩阵乘加(MMA)操作后,将中间结果提升到CUDA Core上进行全精度FP32累积,显著提高了计算的准确性,同时几乎不引入额外开销。
-
统一使用E4M3格式:得益于细粒度的量化策略,本文在所有张量上统一使用E4M3(4位指数,3位尾数)格式,相比混合使用E4M3和E5M2的方案,获得了更高的精度。
实验结论
DeepSeek-V3在极低的训练成本下,取得了卓越的性能,其基座模型和聊天模型在多项评测中均表现出色。
训练成本:
| 训练成本 | 预训练 | 上下文扩展 | 后训练 | 总计 | | :— | :— | :— | :— | :— | | H800 GPU小时 | 2664K | 119K | 5K | 2788K | | 美元(假设$2/h) \mid $5.328M | $0.238M \mid $0.01M | $5.576M | 注:总训练成本(不含研究和消融实验)仅为约279万H800 GPU小时。
核心评测结果:
- 知识与通用能力:在MMLU、MMLU-Pro和GPQA等教育和知识类基准上,DeepSeek-V3全面超越了其他所有开源模型,取得了与GPT-4o和Claude-3.5-Sonnet等顶级闭源模型相当的成绩,显著缩小了开源与闭源的差距。
- 代码与数学:
- 在数学方面(如MATH-500),DeepSeek-V3在所有非长思维链(non-long-CoT)模型中达到SOTA水平,甚至在某些基准上超越了o1-preview,展示了强大的数学推理能力。
- 在代码方面,DeepSeek-V3在编程竞赛类基准(如LiveCodeBench)上表现最佳,成为该领域的领导者。
- 对齐与聊天:经过后训练的DeepSeek-V3-Chat版本,在与人类偏好对齐后,同样在多个标准和开放式评测中优于其他开源模型,并能与顶尖闭源模型进行有力竞争。
最终结论:DeepSeek-V3通过在架构、训练算法和系统工程上的协同优化,成功地以极高的性价比训练出了目前最强的开源基础模型。实验结果充分验证了其无辅助损失负载均衡、多Token预测、DualPipe算法以及大规模FP8训练等一系列创新策略的有效性。