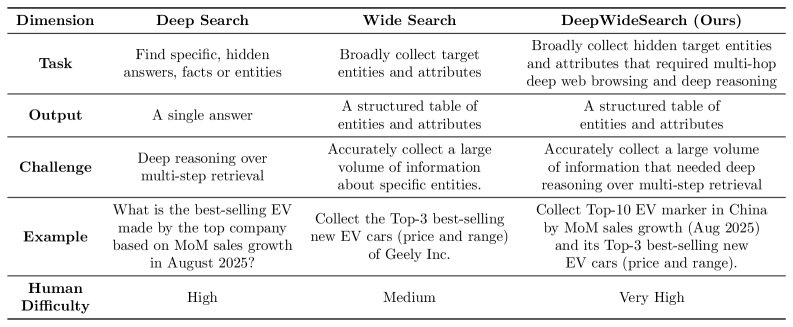
DeepWideSearch: Benchmarking Depth and Width in Agentic Information Seeking
-
ArXiv URL: http://arxiv.org/abs/2510.20168v1
-
作者: Weihua Luo; Longyue Wang; Haijun Li; Bin Zhu; Zhao Xu; Kaifu Zhang; Tian Lan; Junyang Ren; Qianghuai Jia
-
发布机构: Alibaba International Digital Commerce
TL;DR
- 本文提出了首个专为评估智能体(agent)信息搜寻中“深度”(多跳推理)与“宽度”(规模化信息收集)结合能力的基准测试——DeepWideSearch,并揭示了即便是最先进的智能体在该任务上的成功率也极低,暴露出当前智能体架构的根本性局限。
关键定义
- 深度搜索 (Deep Search): 指需要通过多步推理(multi-hop reasoning)和检索才能找到目标答案的搜索任务,强调逻辑链条的深度。
- 宽度搜索 (Wide Search): 指需要围绕特定问题收集大量、广泛信息的搜索任务,强调信息覆盖的广度。
- DeepWideSearch: 本文提出的新型基准测试,其核心特点是要求智能体同时处理大量数据(宽度),且每项数据的获取都需要通过多跳检索路径进行深度推理(深度),旨在填补现有评测体系的空白。
- Deep2Wide: 一种数据集构建方法,通过为现有的深度搜索任务(如GAIA)人工标注表格模式(table schemas),将其扩展为兼具深度和宽度的任务。
- Wide2Deep: 另一种数据集构建方法,通过将现有宽度搜索任务中的明确实体替换为需要多跳搜索才能解决的复杂子问题,从而增加任务的推理深度。
相关工作
现有用于评估智能体的基准测试主要沿着两个维度发展:搜索宽度与搜索深度。
- 研究现状:
- 深度推理型: 如GAIA和BrowseComp,专注于评估智能体在复杂问题上的多跳推理和检索能力。
- 宽度收集型: 如WideSearch和PaSa,侧重于评估智能体围绕特定主题收集全面信息的能力。
- 简单事实查找型: 如TriviaQA和HotpotQA,任务相对简单。
-
存在问题: 当前没有任何基准测试能同时评估智能体在广度探索和深度推理上的综合能力。现实世界中的许多复杂任务,如全面的市场分析,恰恰需要这种“深宽结合”的能力,即需要收集大量候选信息(宽度),并对每个候选信息进行深度验证(深度)。这种组合复杂性超出了现有基准的评估范围。
- 本文目标: 针对这一评测空白,本文引入了DeepWideSearch,首个明确设计用于评估智能体在深宽信息搜寻(deep and wide information seeking)方面能力的基准测试。
本文方法
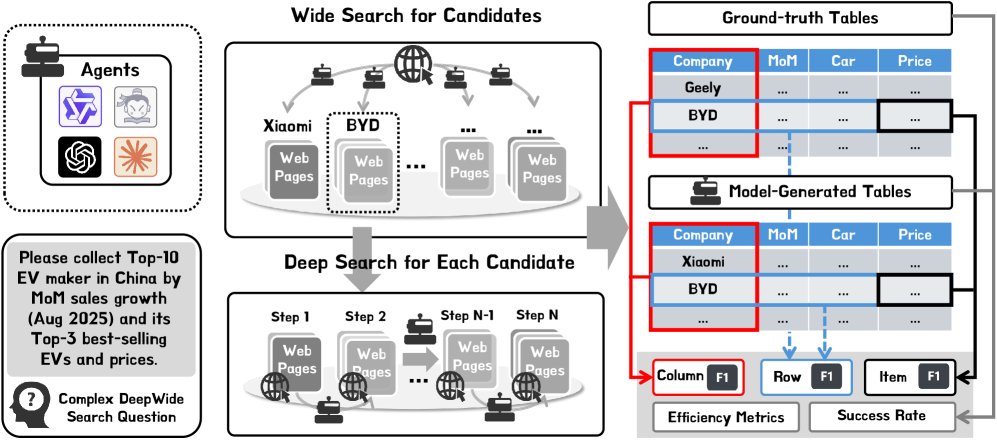
任务设定
DeepWideSearch框架要求智能体在处理任务时,既要进行深度推理,又要进行大规模信息收集。
- 输入: 每个任务定义为一个元组 \($(Q, C)\)$,其中 \(Q\) 是一个复杂的自然语言查询,\(C\) 定义了需要收集和验证的属性及约束的表格模式。
- 输出: 智能体需要生成一个结构化的表格响应 \(R\),这需要通过广泛搜索来收集众多候选条目,并通过深度搜索来验证每个条目的具体信息。
数据集构建方法
为了高效构建具有高质量和复杂度的测试实例,本文提出了两种基于现有数据集的转换方法,并辅以人工验证。
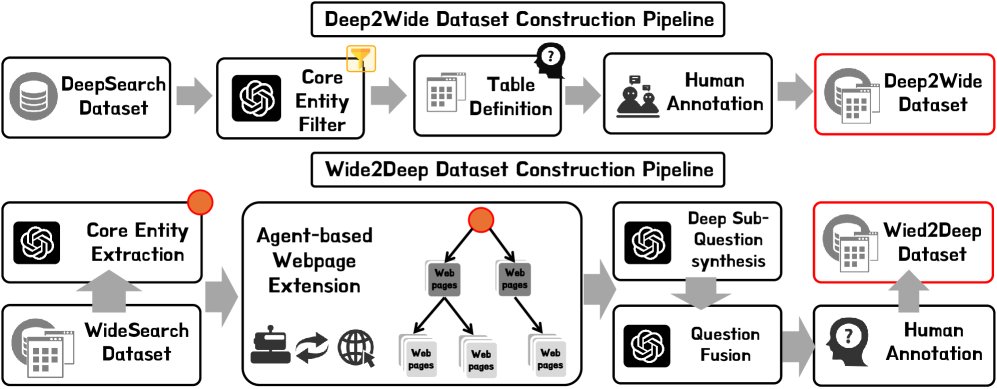
### Deep2Wide转换
该方法旨在将现有的深度搜索数据集扩展至更广的信息范围。
- 核心实体提取 (Core Entity Extraction): 从BrowseComp等深度搜索数据集中筛选出问题,其答案可作为核心实体(Core Entity)。
- 表格模式定义 (Schema Definition): 人工标注员为这些核心实体设计相关的表格结构,定义需要收集的信息属性。
- 答案填充 (Answer Population): 标注员通过详尽的网络搜索来填充表格,确保数据的高质量。为保证答案的时效性,每个问题都加入了时间戳。
### Wide2Deep转换
该方法旨在增加宽度搜索任务的推理深度。
- 核心实体提取: 使用LLM从WideSearch等宽度搜索数据集中识别出核心实体。
- 子问题合成 (Sub-question Synthesis): 基于核心实体信息,利用一个搜索智能体自动生成一个复杂的子问题。该子问题需满足两个条件:(a) 答案唯一;(b) 无法直接从问题中推断,至少需要一次额外的网络搜索。
- 问题融合 (Question Fusion): 使用LLM将新生成的深度子问题与原始的宽度搜索查询进行融合。
- 人工验证 (Human Validation): 由标注员团队对合成的问题进行验证和优化,确保其唯一性、复杂性和语言的自然性。
数据统计
DeepWideSearch在复杂性上远超现有基准。平均每个任务需要处理414.1个信息单元,识别核心实体的平均搜索步骤为4.21步,是WideSearch的近4倍。该数据集包含220个问题,覆盖15个不同领域,支持中英双语。
评测指标
从深度、宽度和效率三个维度评估智能体性能。
### 深度评测
- 列F1值 (Column F1): 计算智能体输出表格与标准答案表格在唯一标识列(通常是核心实体)上的F1分数。这可以看作是对传统深度搜索准确率的扩展,用于衡量一组实体的识别精度。
- 核心实体准确率 (Core Entity Accuracy): 一个额外的指标,直接评估智能体识别问题核心实体的能力。
### 宽度评测
- 成功率 (Success Rate): 一个二元指标,当且仅当智能体输出的表格与标准答案完全一致时才算成功。
- 行F1值 (Row F1): 在行(即每个实体及其所有属性)的粒度上计算精确率、召回率和F1值,衡量实体完整信息的检索情况。
- 项F1值 (Item F1): 在单个单元格的粒度上计算准确性,是最精细的指标。
### 效率评测
- Token消耗 (Tokens): 整个任务过程中消耗的总Token数量。
- 预估成本 (Cost): 根据模型API定价估算出的费用。
为了保证结果的稳健性,每个问题进行四次独立运行,并报告平均值(Avg@4)、最佳值(Best@4)和至少成功一次的比例(Pass@4)。
实验结论
主要结果
| 模型/智能体 | 列F1 (Avg@4) | 核心实体准确率 (Avg@4) | 行F1 (Avg@4) | 项F1 (Avg@4) | 成功率 (Avg@4) | 成功率 (Pass@4) |
|---|---|---|---|---|---|---|
| LLMs | ||||||
| GPT-5 | 42.12 | 58.41 | 10.66 | 21.08 | 0.00% | 0.00% |
| Claude Sonnet 4 | 32.63 | 57.95 | 9.49 | 20.31 | 0.45% | 1.82% |
| Gemini 2.5 Pro | 45.27 | 73.98 | 12.44 | 24.59 | 0.45% | 1.82% |
| … | … | … | … | … | … | … |
| 智能体系统 | ||||||
| WebSailor (GPT-5) | 39.40 | 74.32 | 11.23 | 24.23 | 0.91% | 1.82% |
| WebSailor (C Sonnet 4) | 33.15 | 70.91 | 11.20 | 25.13 | 1.36% | 2.27% |
| WebSailor (G 2.5 Pro) | 39.81 | 68.64 | 11.83 | 24.27 | 1.36% | 2.27% |
| … | … | … | … | … | … | … |
- 总体表现极差: 即便是最先进的智能体系统,在DeepWideSearch上的平均成功率也仅为2.39%,证实了同时处理深度和宽度任务的巨大挑战。
- Gemini 2.5 Pro表现突出: 作为基础LLM,Gemini 2.5 Pro在深度指标(列F1和核心实体准确率)上甚至超越了部分智能体系统,表明其拥有强大的推理能力和丰富的内部知识。
深度指标分析
- 智能体框架普遍能提升基础LLM的核心实体识别能力(CE Acc.)。例如,WebSailor将GPT-5的CE Acc.从58.41%提升至74.32%。这得益于智能体的迭代式工具调用和多步推理机制。
- 然而,一个关键的限制是:即便智能体成功识别了核心实体,它们也无法可靠地收集完整的相关信息。在列F1值上,智能体系统的表现甚至可能不如直接利用内部知识的基础LLM。
宽度指标分析
- 大多数智能体框架未能显著提升基础LLM的宽度搜索能力。与基础LLM相比,多个智能体系统在宽度指标上表现出性能退化。
- 分析发现,某些智能体架构(如Smolagents)在调用工具前缺乏充分的推理,导致无法形成精确的搜索查询,从而影响信息覆盖的广度。
分析
### 效率分析
DeepWideSearch任务的计算开销巨大。即使是SOTA智能体,平均解决一个问题的成本也高达$1.40至$2.75,且很多问题仍未解决。在考虑网络不稳定和工具调用重试的情况下,成本会更高。这表明当前智能体架构在可扩展性方面存在严重不足。
### 工具调用分析
| 模型 (WebSailor) | 搜索工具调用次数 | 访问工具调用次数 |
|---|---|---|
| GPT-5 | 8.72 | 16.59 |
| Claude Sonnet 4 | 23.23 | 24.16 |
| Gemini 2.5 Pro | 4.77 | 6.83 |
数据显示,表现更优的Claude Sonnet 4智能体进行了更多的搜索工具调用,这表明增加搜索广度有助于提升性能。
### 不同构建方法下的性能差异
实验表明,由Deep2Wide方法生成的数据比Wide2Deep方法生成的更具挑战性。在Deep2Wide子集上,智能体的成功率几乎为零,核心实体准确率也远低于Wide2Deep子集(33.29% vs 88.84%)。这说明Wide2Deep中合成的子问题相对更容易解决。
### 分主题性能分析
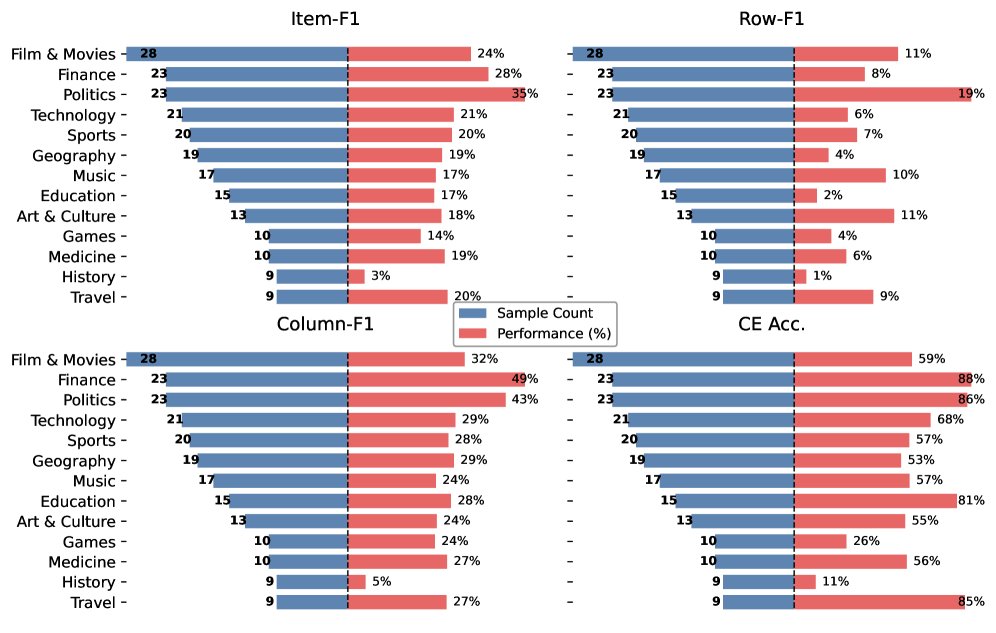
- 在“商业”、“技术”和“科学”等主题上,智能体表现出较强的深度搜索能力(高列F1和CE准确率),但在宽度指标上表现很差。这揭示了深度搜索能力强并不等同于宽度搜索能力也强。
- “地理”和“历史”主题在所有指标上都表现不佳,是最具挑战性的领域。
### 错误分析
通过分析失败案例,本文总结了当前智能体的四大失败模式:
- 缺乏反思 (Lack of reflection): 当遇到错误的搜索路径或工具调用失败时,智能体倾向于直接放弃,而不是分析失败原因并尝试替代方案。
- 过度依赖内部知识 (Overreliance on internal knowledge): 即使正确识别了核心实体,智能体也常常使用其参数化的内部知识来填充表格,而不是执行网络查询,导致信息过时或不准确。
- 检索不充分 (Insufficient retrieval): 智能体即使找到了相关网页,也常常未能通过访问操作获取完整上下文,导致信息遗漏。即使执行了访问,网页摘要也可能丢失关键细节。
- 上下文溢出 (Context overflow): 深宽搜索任务需要大量的推理步骤和工具调用,导致上下文长度急剧膨胀,超出了当前智能体架构的管理能力。
总结与未来工作
本文通过引入DeepWideSearch基准,首次量化了信息搜寻领域中结合深度推理与广度收集的挑战,并实验证明了现有SOTA智能体在该任务上的能力严重不足。分析揭示了当前智能体架构在反思、知识使用、检索策略和上下文管理方面的根本性缺陷。
未来的工作方向包括:
- 提升数据集难度: 迭代优化Wide2Deep方法,生成更复杂的子问题。
- 对齐真实场景: 持续优化数据集,使其更贴近真实世界的复杂应用。
- 自动化数据生成与评测: 探索自动化的数据生成技术和免参考(reference-free)的评测指标,以降低对人工标注的依赖,实现数据集的快速扩展。