Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls
-
ArXiv URL: http://arxiv.org/abs/2510.01631v1
-
作者: Mostafa Elhoushi; Carole-Jean Wu; Ruoxi Jia; Ramya Raghavendra; Feiyang Kang; Shang-Wen Li; Michael Kuchnik; Newsha Ardalani
-
发布机构: Cerebras Systems; Independent consultant; Meta; Virginia Tech
TL;DR
本文通过大规模实证研究系统地揭示了,在大型语言模型预训练中战略性地混合约30%的重述(rephrased)合成数据与自然网络文本,可以在大数据量下将达到相同损失所需的训练速度提升5-10倍,但合成数据的最终效果高度依赖其类型、混合比例和生成器模型的能力。
关键定义
本文的核心是围绕两种不同范式的合成数据展开的,并未引入全新的理论术语,而是对以下两种合成数据生成方法进行了操作化定义和系统性研究:
- 网页重述 (Web Rephrasing): 一种利用预训练语言模型(生成器模型)来重写和改进现有网络文档(如来自CommonCrawl的数据)的方法。本文探索了两种具体风格:
- 高质量重述 (High-Quality Rephrasing, HQ): 将源文本改写为类似维基百科风格的清晰、连贯、结构良好的高质量文本,旨在提升数据的信息密度和质量。
- 问答重述 (Question-Answering Rephrasing, QA): 将源文本的信息重组为对话式的问答格式,旨在将指令遵循或对话能力直接整合到预训练阶段。
- 合成教科书 (Synthetic Textbooks, TXBK): 一种生成全新内容的范式,旨在模仿教科书或高质量教育材料的结构、风格和信息密度。该方法使用从网络文本中提取的关键词作为种子,提示生成器模型创造出关于特定主题的、包含清晰解释、定义、示例甚至练习的原创“教科书式”文档。
相关工作
当前,高质量自然文本数据的稀缺性已成为训练更强大型语言模型(LLM)的瓶颈,使得合成数据成为一个备受关注的解决方案。尽管合成数据在指令微调等后训练阶段已证明其价值,但其在 foundational pre-training(基础预训练)阶段的作用仍不明确,相关研究存在以下问题:
- 方法论不统一:现有研究(如Phi系列、WRAP等)大多采用定制化的设置,导致实验结果难以直接比较和泛化。
- 效果矛盾:关于合成数据是提升了质量但牺牲了多样性,还是多样性本身是关键,学界存在矛盾的观点。部分研究甚至报告称,在某些合成数据上训练的模型性能会过早饱和。
- 理论风险:理论研究(如“模型崩溃” model collapse)警告,在模型生成的数据上进行递归训练可能导致性能退化,但这一风险在结合了大量自然数据的大规模单轮训练场景下缺乏充分的实证证据。
本文旨在解决上述知识鸿沟,通过统一协议下的大规模系统性实验,明确回答以下问题:合成数据能否以及在何种条件下有效提升LLM预训练性能?不同类型的合成数据及其混合比例如何影响训练动态和扩展行为?
本文方法
本文的核心创新并非提出一种全新的算法,而是设计并执行了一项前所未有的大规模、系统性的实证研究,以揭示合成数据在LLM预训练中的作用。研究方法主要包含两种合成数据生成范式。
网页重述
该方法借鉴了WRAP等工作的思想,利用一个预训练的生成器模型(本文使用Mistral-7B-Instruct)来“提纯”现有的网络文档。具体流程是,从CommonCrawl(CC)数据集中采样文档,然后通过特定提示词(prompt)让模型重写。本文生成了两种风格的重述数据:
- 高质量 (HQ) 重述:模仿维基百科等高质量信源的风格,将原始文本改写得更清晰、连贯、结构化。其目标是作为一种激进的数据筛选或质量增强手段,提高训练数据的有效信息密度。
- 问答 (QA) 重述:将原始文本的信息内容重构成一问一答的对话形式。其目标是探索在预训练阶段直接注入指令遵循和对话能力的可能性,这与“指令预训练”的理念相契合。
合成教科书 (TXBK)
该方法基于一个假设:与零散的网络文本相比,信息密集的教育类内容可能在培养模型的推理、编码和事实性能力方面更具计算效率。其目标是生成全新的、高质量的教育内容。具体流程是,使用从CC中提取的关键词作为主题种子,然后通过结构化提示词引导生成器模型创作出类似教科书章节或教程的文本。这些提示词明确要求包含清晰的解释、定义、代码示例及相关练习,并强调事实准确性和教学结构。
实验结论
本文进行了大规模实验,训练了超过1000个LLM变体(模型参数量达3B,训练数据量达200B tokens),旨在系统评估不同类型合成数据及其混合比例对预训练的影响。
扩展定律分析
通过对模型大小($N$)和数据量($D$)的扩展定律分析,本文得出了关于训练损失($\mathcal{L}$)的可靠预测模型。
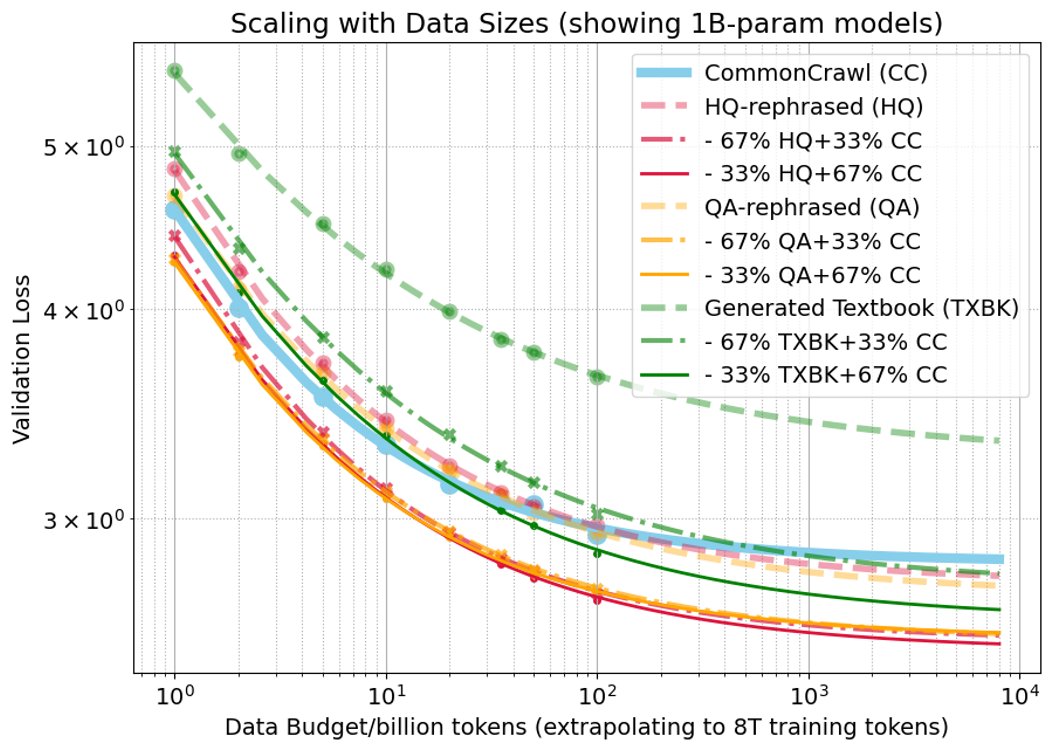
数据扩展
固定模型大小在不同数据量上训练,损失函数遵循 $\hat{\mathcal{L}}(D)=\frac{B}{D^{\beta}}+E$。 主要发现如下:
- 纯合成数据表现不佳:单独使用任何一种合成数据(HQ, QA, TXBK)进行预训练,其性能均不优于仅使用自然数据(CC)。特别是纯TXBK数据,表现明显更差。
- 混合策略显著提升:将任何类型的合成数据与CC混合,其性能都远超单独使用该合成数据。
- 最佳混合比例因类型而异:对于HQ和QA重述数据,33%和67%的混合比例表现相似。而对于TXBK数据,33%的混合比例远优于67%,并且在大约20B tokens的训练数据量之后,其表现开始超越纯CC数据。
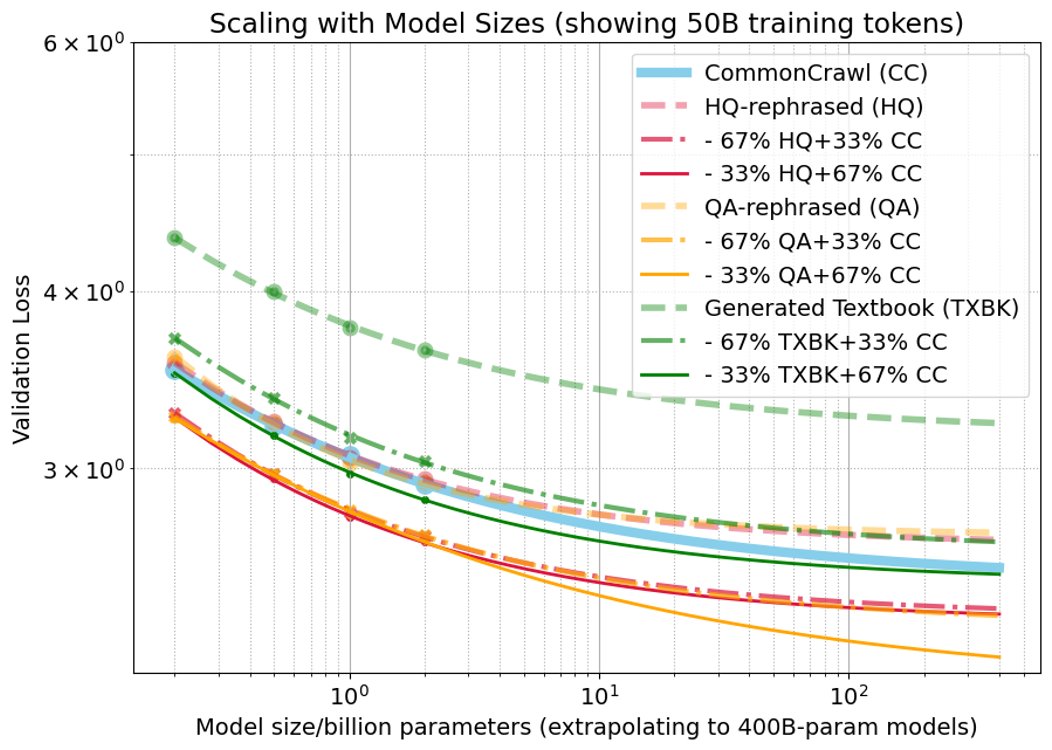
模型扩展
固定数据量在不同模型大小上训练,损失函数遵循 $\hat{\mathcal{L}}(N)=\frac{A}{N^{\alpha}}+E$。 主要发现如下:
- 随着模型规模增大,对于重述数据(HQ/QA),33%的合成数据混合比例略优于67%,这与数据扩展的趋势相反,表明更大的模型对高比例合成数据的“容忍度”可能更低。
- 对于TXBK数据,33%的混合比例始终优于67%,但其相对于纯CC数据的优势会随着模型增大而减小。
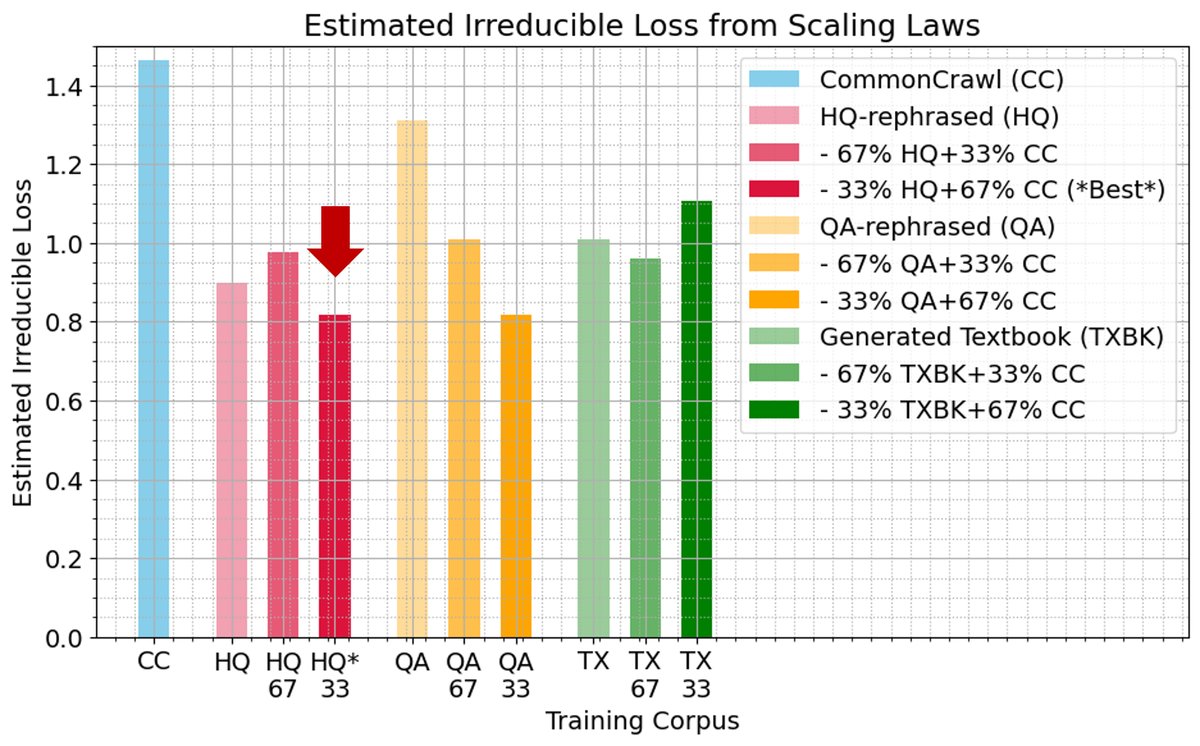
计算扩展与不可约损失
通过拟合联合扩展定律 $\hat{\mathcal{L}}(N,D)=\frac{A}{N^{\alpha}}+\frac{B}{D^{\beta}}+E$,本文估算了各种数据混合下的理论最低损失( irreducible loss, E)。
- 33% HQ混合表现最佳:33% HQ重述数据与67% CC的混合,其不可约损失$E$在所有数据集中是最低的,甚至低于纯CC数据。这一经验证据有力地挑战了“模型崩溃”理论中关于任何合成数据引入终将损害性能的预测。
- 纯合成数据风险:与之相对,纯QA重述数据和纯CC数据的不可约损失是最高的,表明了数据源选择对模型潜力的深远影响。
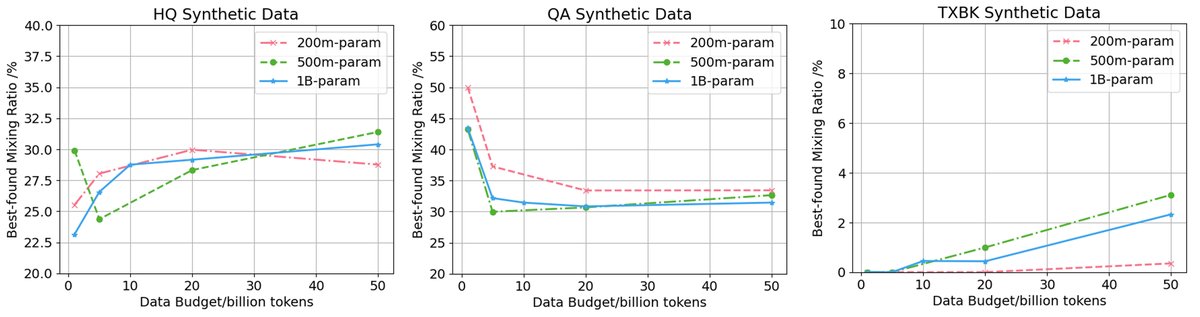
进一步研究
最佳混合比例
通过更精细的网格搜索发现:
- 对于HQ和QA重述数据,在不同的模型和数据规模下,最佳混合比例都低于50%,并似乎向约30%收敛。
- 对于TXBK教科书数据,其收益主要在较大规模下显现,且最佳比例通常低于重述数据。
生成器能力影响
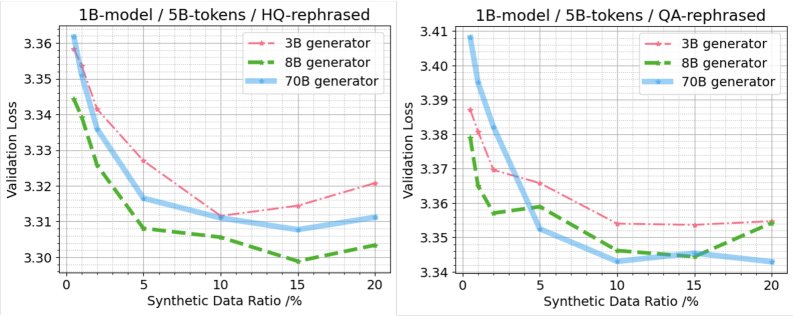
一个反直觉的发现是,更大、更强的生成器模型不一定能产出更好的预训练数据。
- 存在能力门槛:使用Llama-3 8B模型作为生成器,其产出的合成数据优于3B模型。
- 收益递减甚至为负:然而,使用70B模型作为生成器,其产出的HQ和QA数据在下游模型上的表现并不优于8B模型,在某些情况下甚至更差。这表明,单纯提升生成器规模并非最优策略,可能存在其他因素如输出多样性、指令遵循保真度等在起作用。
低层统计学解释
对数据进行unigram频率分析发现:
- 模型性能并非简单地由训练数据与测试数据的分布相似性(如KL散度)决定。纯CC数据在词汇覆盖和分布上与测试集最接近,但性能并非最佳。
- 所有数据源都存在分布“盲点”,即某些在测试集中常见的token在训练集中稀疏或缺失,导致高损失。混合数据源有助于弥补这些盲点,解释了为何混合数据通常表现更优。
- 最佳性能的获得是一个复杂的多样性-质量权衡过程,而非简单地最小化分布距离。
总结
本文的系统性研究证实,在预训练中战略性地使用合成数据是有效且有益的。约30%的高质量重述数据与自然数据混合,可将训练速度提升5-10倍,并有望达到比纯自然数据更低的最终损失。这一发现对“模型崩溃”理论提出了挑战,表明在单轮训练中,重述类合成数据在可预见的规模内不会导致性能退化。然而,纯生成式教科书数据则显示出符合“模型崩溃”预测的模式。最终,合成数据的有效性是高度有条件的,取决于其类型、混合策略,并且“越大越好”的生成器模型假设并不成立。