DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.15110v1
-
作者: Xin Dong; Min-Hung Chen; Kwang-Ting Cheng; Jan Kautz; Hongxu Yin; Shih-Yang Liu; Ximing Lu; Pavlo Molchanov; Yejin Choi; Yu-Chiang Frank Wang; 等12人
-
发布机构: HKUST; NVIDIA
TL;DR
本文提出了一种名为 DLER 的强化学习训练配方,通过改进优化技术(而非设计复杂的长度惩罚函数)来解决模型输出过长的问题,在将响应长度缩短超过70%的同时,还能超越基线模型的准确率,实现了顶尖的准确率-效率权衡。
关键定义
- DLER (Doing Length pEnalty Right):一个旨在激励模型生成“每个Token更具智能”的输出的综合训练配方。它并非一个新算法,而是将四种关键技术结合:1) 简单的截断长度惩罚(超过长度预算则奖励为零);2) 批次级奖励归一化(Batch-wise reward normalization);3) 更高的策略更新裁剪阈值;4) 动态采样。
- Difficulty-Aware DLER (DA-DLER):DLER 的一个难度感知扩展版本。它根据模型在特定问题上的表现(正确率)动态调整截断长度,对简单问题使用更短的长度限制,对难题则放宽限制,以进一步提升效率。
- Update-selective weight merging:一种在强化学习训练数据稀缺时使用的更新选择性权重合并策略。该方法将经过 DLER 训练的简洁模型与原始基线模型的权重进行合并,旨在恢复因数据不足可能导致的准确性下降,同时保留大部分的长度缩减效果。
相关工作
当前的推理语言模型(如 OpenAI-o1, DeepSeek-R1)通过生成冗长的思维链(Chain of Thought, CoT)取得了强大的性能,但这导致了过高的Token使用量、延迟和在简单问题上的输出冗余。为了提升“每Token的智能”,即在保证准确率的同时最大化效率,研究者们探索了多种方法,包括提示工程、监督微调和强化学习(RL)。
在这些方法中,基于RL的方法被认为是最有原则性的途径,它们通常在奖励函数中引入长度惩罚。然而,尽管现有方法显著减少了推理长度,但它们常常导致准确率下降,尤其是在不同难度的任务上表现不一。此前的研究普遍认为,准确率的下降是由于长度惩罚函数设计不佳,因此致力于设计更复杂的惩罚机制。
本文挑战了这一主流观点,旨在解决的核心问题是:在使用简单的长度惩罚(如截断)时,由次优的强化学习优化技术导致的准确率下降问题。本文假设,性能瓶颈不在于惩罚函数本身,而在于优化过程。
本文方法
本文的核心思想是,通过改进强化学习的优化过程,而非设计复杂的惩ें罚函数,来解决在使用长度惩罚时遇到的准确率下降问题。作者首先回归到最简单的长度惩罚——截断(truncation),即对超过预设长度的响应奖励直接置零。通过分析,作者识别出标准 RL 优化(如 GRPO)在这种设置下面临的三大挑战,并提出了相应的解决方案,最终整合成 DLER 配方。
挑战与解决方案
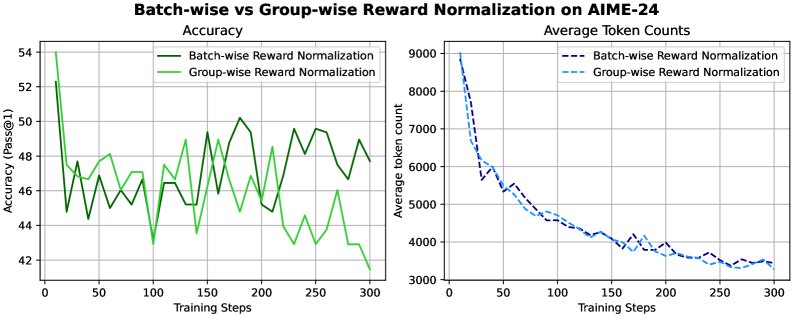
1. 高奖励方差与有偏的优势估计
问题:截断惩罚导致奖励信号出现大量零值,极大地增加了奖励的方差。在使用如 GRPO 这类基于提示级别(prompt-wise)进行优势估计的算法时,高方差会引入显著的偏差,导致训练不稳定和性能下降。 解决方案:采用批次级奖励归一化 (Batch-wise reward normalization)。通过在整个批次(batch)而非单个提示的生成组内计算均值和标准差来归一化优势,可以有效平滑由截断引入的奖励噪声,从而获得更稳定和无偏的优势估计。其优势计算公式变为:
\[A_{i,t}^{\mathrm{norm}} = \frac{A_{i,t} - \mathrm{mean}_{\mathrm{batch}}(A_{i,t})}{\mathrm{std}_{\mathrm{batch}}(A_{i,t})}\]其中 $A_{i,t} = R’_{i} - \mathrm{mean}({R’_{i}}_{i=1}^{G})$。
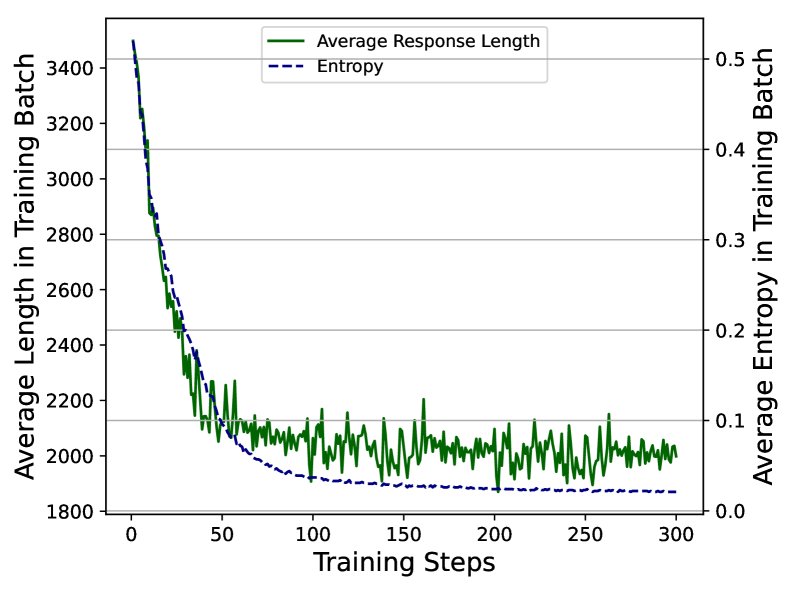
2. 熵崩溃限制了探索
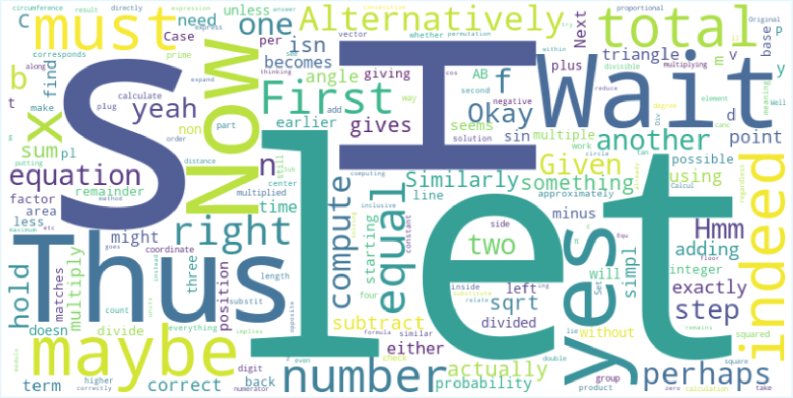
问题:在训练过程中,模型的输出分布熵会急剧下降,即“熵崩溃”。这导致模型过早地收敛到一小组相似的响应上,限制了对多样化推理路径的探索。分析发现,这个问题与PPO类算法中的重要性采样比例裁剪(clipping)有关,许多具有探索性的、高熵、低概率的Token(如 “Hmm”, “Alternatively”, “thus” 等)的梯度因被裁剪而无法更新。
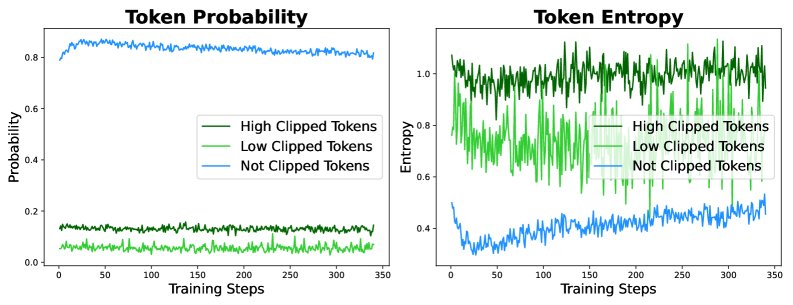
解决方案:采用更高的上界裁剪阈值。通过将裁剪的上界 $\epsilon_{high}$ 设置得比下界更大,可以保留这些关键探索性Token的梯度,鼓励模型在训练中进行更多样化的行为探索,从而缓解熵崩溃问题。
3. 长度惩罚导致训练信号稀疏
问题:长度惩罚导致了两种极端情况,都对训练不利:
- 全零奖励:对于难题,模型生成的所有响应都可能因超长而被截断,导致该提示的所有奖励均为零,模型无法从中学习如何改进。
- 全正奖励:对于简单题,模型很容易在长度预算内给出正确答案,导致所有响应都获得正奖励。这会使模型过拟合于生成过短的响应,而未充分利用长度预算去探索更优的解法。
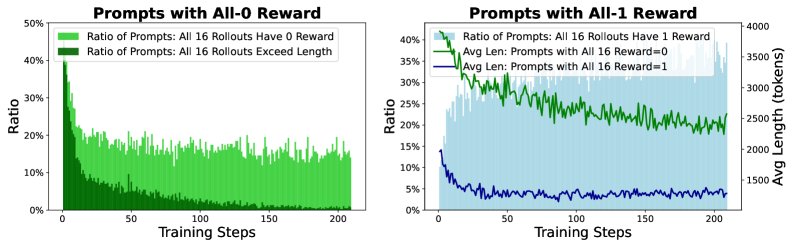
解决方案:采用动态采样 (Dynamic sampling)。在构建每个训练批次时,过滤掉那些所有响应奖励全为零或全为正的提示,并重新采样,直到批次中包含有价值的(即奖励有正有负)训练信号。这种方法形成了一种隐式的课程学习,随着训练的进行,模型能力增强,能够处理更难的、最初无法解决的问题。
DLER 训练配方
DLER (Doing Length pEnalty Right) 正是上述三种解决方案与简单截断惩罚的结合体。它通过系统性地解决优化过程中的偏差、探索和信号稀疏问题,使得模型能够在长度受限的情况下有效学习,最终在大幅缩短输出的同时保持甚至提升准确率。
Difficulty-Aware DLER (DA-DLER)
为了进一步提升效率,本文提出了DA-DLER。该方法根据模型对问题的掌握程度(通过采样响应的正确率来衡量)动态调整截断长度。对于模型已经能够可靠解决的“简单”问题,施加更严格的长度限制;对于“困难”问题,则给予更宽松的长度预算。这种自适应策略能更精细地压榨冗余,实现更高的效率。
实验结论
主要结果
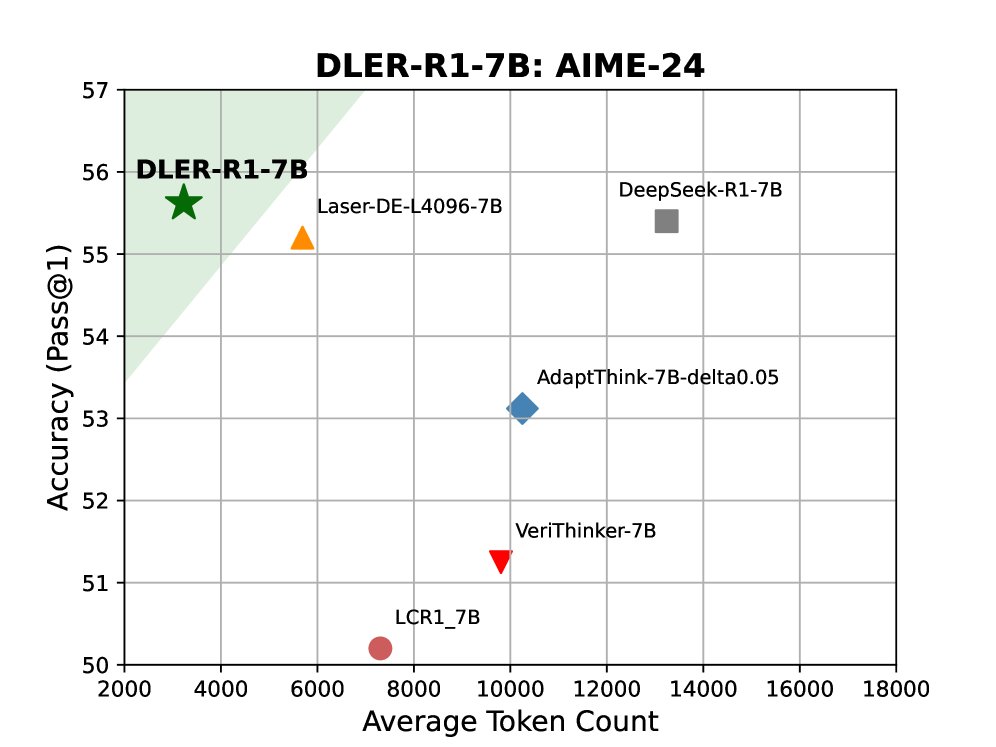
实验在 DeepSeek-R1-1.5B/7B 模型上进行,并与 Laser、AdaptThink 等多种先进的推理压缩方法进行比较。结果表明,DLER 在所有基准测试中均取得了最先进的准确率-效率权衡。
| Model | MATH (acc) | AIME-24 (acc) | AMC (acc) | Minerva (acc) | Olympiad (acc) | Avg. Len | Len. $\downarrow$ |
|---|---|---|---|---|---|---|---|
| 1.5B Models | |||||||
| DeepSeek-R1-1.5B | 86.41 | 31.87 | 80.00 | 45.42 | 46.21 | 10459 | - |
| Laser-DE-L4096-1.5B (ours) [] | 85.27 | 30.62 | 78.89 | 43.68 | 46.21 | 3786 | 64% |
| DLER-R1-1.5B (ours) | 86.95 | 34.38 | 80.00 | 45.42 | 48.31 | 2466 | 76% |
| DA-DLER-R1-1.5B (ours) | 86.68 | 33.75 | 79.44 | 44.97 | 48.31 | 2106 | 80% |
| 7B Models | |||||||
| DeepSeek-R1-7B | 93.37 | 54.38 | 81.67 | 56.55 | 65.17 | 7725 | - |
| Laser-DE-L4096-7B (ours) [] | 92.83 | 55.00 | 81.67 | 57.00 | 66.21 | 3183 | 59% |
| DLER-R1-7B (ours) | 94.21 | 55.62 | 84.41 | 57.90 | 68.28 | 2405 | 69% |
| DA-DLER-R1-7B (ours) | 93.94 | 55.00 | 83.33 | 57.45 | 67.24 | 2127 | 72% |
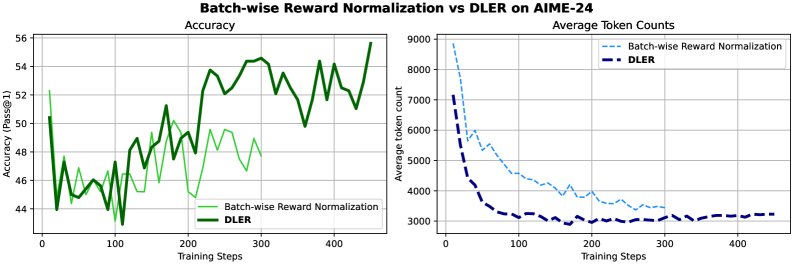
- DLER:在 1.5B 和 7B 规模上,DLER 模型不仅将平均响应长度分别减少了 76% 和 69%,还在所有评估基准上超越了原始基线模型的准确率,全面优于以往的方法。
- DA-DLER:在 DLER 的基础上,DA-DLER 进一步将 1.5B 和 7B 模型的长度分别额外压缩了 15% 和 12%,且准确率几乎没有损失,展示了自适应策略的潜力。
测试时扩展性与效率
DLER 不仅在训练效率上表现出色,在测试时也展现出巨大优势。由于响应长度大幅缩短,模型可以并行生成多个候选答案(并行思考),在相同的“思考时间”内获得远超基线模型的准确率。
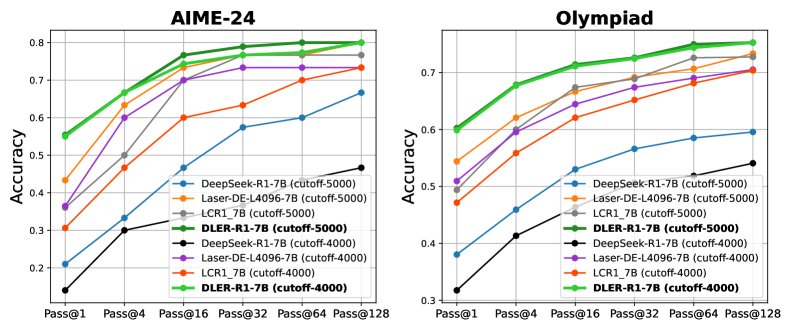
- 延迟优势:在单 H100 GPU 上,DLER-R1-7B 生成单个响应的平均时间从基线的 93.43 秒降至 23.73 秒,速度提升近 4 倍。
- 准确率-时间权衡:为了达到 83.33% 的准确率,DLER-R1-7B(并行生成256个响应)仅需 85.43 秒,而基线模型(并行16个响应)需要 221.22 秒。这意味着 DLER 能在少用 62% 的时间下达到更高的准确率。
优化配方的重要性
实验还证明了本文的核心论点:优化配方比惩罚函数设计更重要。当将 DLER 的优化配方应用于其他已发表的复杂长度惩罚函数(如 Cosine, Laser-DE 等)时,所有模型的性能都得到了显著提升,并共同定义了一个新的、更优的准确率-长度帕累托前沿。这表明,无论采用何种惩罚函数,DLER 提供的优化方案都能解锁其潜力,实现更好的效果。
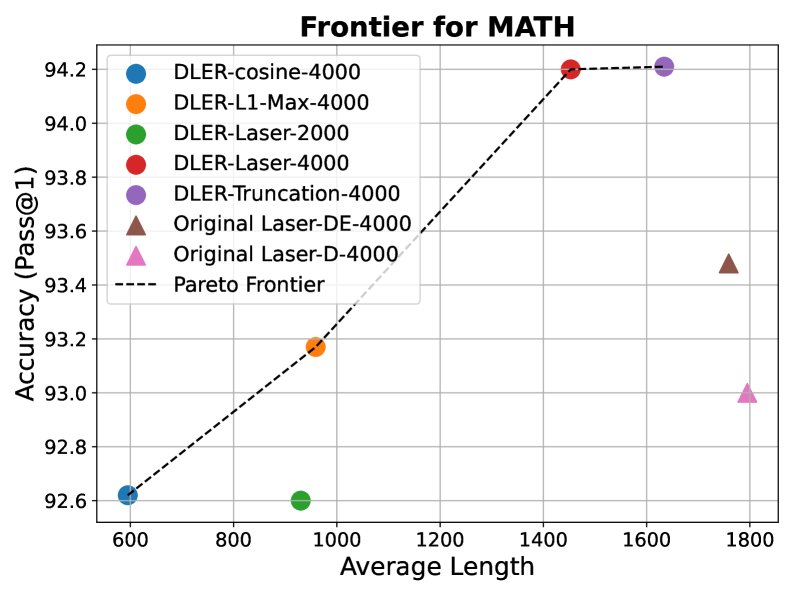
最终结论
本文的发现揭示了一个关键点:在通过强化学习提升大模型推理效率时,真正的瓶颈是优化算法本身,而不是惩罚函数的设计。通过 DLER 这一精心设计的优化配方,即使使用最简单的截断惩罚,也能实现最先进的准确率-效率权衡,为构建更实用、更高效的推理模型提供了新的思路和强大的工具。