DocReward: A Document Reward Model for Structuring and Stylizing
-
ArXiv URL: http://arxiv.org/abs/2510.11391v1
-
作者: Si-Qing Chen; Jiayu Ding; Lei Cui; Tao Ge; Tengchao Lv; Yilin Jia; Yupan Huang; Bowen Cao; Xun Wang; Junpeng Liu; 等17人
-
发布机构: Microsoft; The Chinese University of Hong Kong; UCAS; University of Michigan; XJTU
TL;DR
本文提出了一种名为 DocReward 的文档奖励模型,它通过在一个包含117K对文档的大规模数据集上学习,专门用于评估文档的结构和风格专业性,并在该任务上显著优于 GPT-5 等强大的基线模型。
关键定义
本文提出或使用的核心概念包括:
- DocReward: 本文提出的核心模型,一个文档奖励模型 (Document Reward Model),专门用于评估文档的结构和风格专业性,而非文本内容的质量。
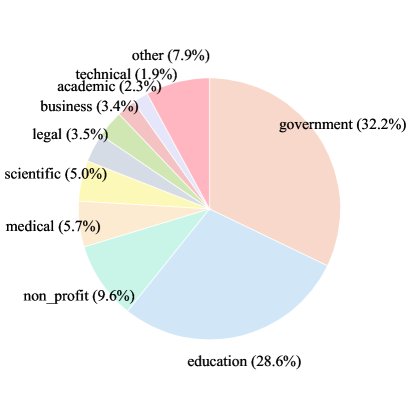
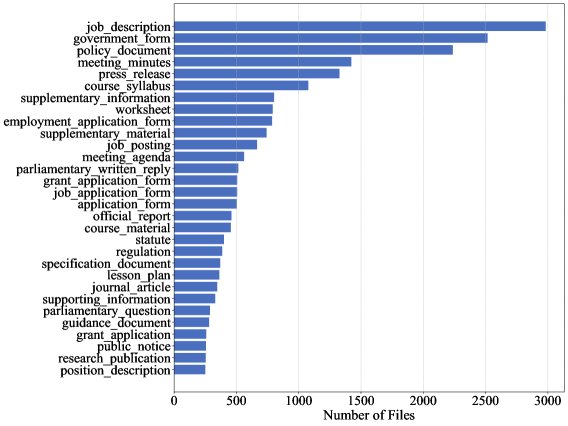
- DocStruct-117K: 为训练 DocReward 而构建的多领域数据集。该数据集包含 117,000 个文档对,覆盖32个领域和267种文档类型。每个文档对中的两个文档内容完全相同,但在结构和风格的专业性上存在明确的高下之分。
- 文本质量无关性 (Textual-quality-agnosticism): DocReward 的一个关键特性,指模型在评估时忽略文本内容本身的优劣,仅关注在给定文本内容的情况下,文档的结构和风格表现如何。这通过使用内容相同但形式不同的文档对进行训练来实现。
- 文档结构与风格专业性: 本文对评估目标的具体定义,包括:
- 结构 (Structure): 合理使用空白、适当的页边距、清晰的章节分隔、良好的文本对齐、足够的段落间距、正确的缩进、包含页眉页脚以及内容的逻辑连贯组织。
- 风格 (Style): 恰当的字体选择(类型、大小、颜色、可读性)、清晰的标题样式、强调(粗体、斜体)的有效使用、项目符号、编号以及格式的一致性。
相关工作
目前,在智能体工作流 (agentic workflows) 中,自动化专业文档生成是一个重要方向。然而,现有研究主要集中在提升文本内容的质量上,而忽略了对可读性和专业性至关重要的视觉结构与风格。
领域内的关键瓶颈在于,缺乏一个合适的奖励模型来指导智能体生成在结构和风格上更专业的文档。虽然已有针对图形设计、UI界面或单张图片的美学评估模型,但它们不适用于多页文档;而传统的文档AI模型(如LayoutLM)主要关注从文档中提取信息,而非评估其排版质量。
因此,本文旨在解决的核心问题是:如何量化评估文档的结构与风格专业性,并创建一个能有效指导文档生成智能体的奖励模型。
本文方法
本文提出了 DocReward,一个专注于评估文档结构与风格专业性的奖励模型。其核心在于构建了一个高质量的偏好数据集 \(DocStruct-117K\),并基于此训练模型进行评分。
数据集构建 (DocStruct-117K)
为了让模型学会与文本内容无关的专业性评估,本文设计了一个精巧的数据集构建流程:
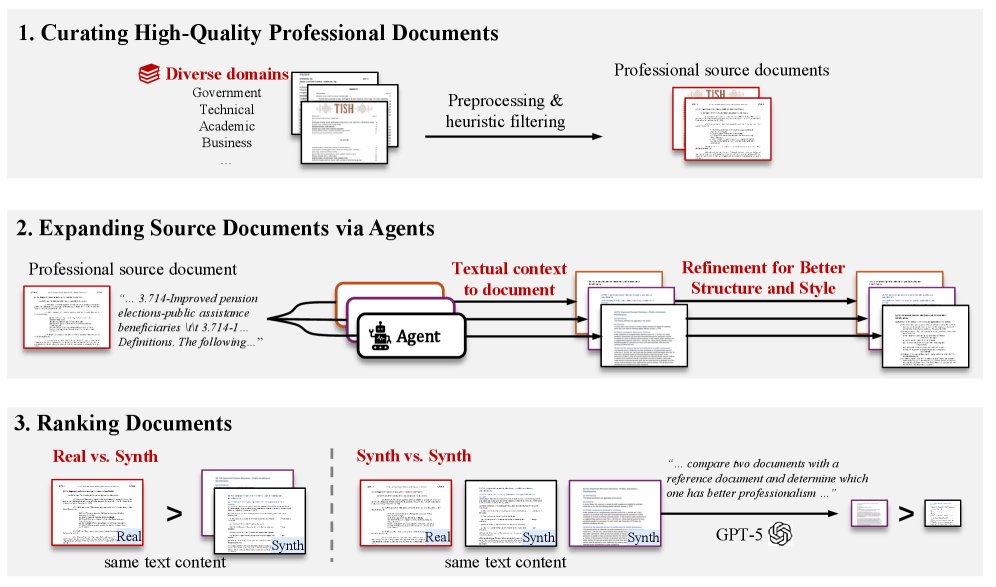
- 收集高质量源文档: 首先,从 GovDocs1、NapierOne 和 CommonCrawl 等来源收集了大量人类创作的高质量专业文档(如政府报告、商业提案、学术论文等)。经过筛选,保留了结构和风格上佳的范例。
-
生成多样化的对应文档: 提取源文档的纯文本内容,然后使用多种大型语言模型(如GPT-4o, GPT-5等)驱动的智能体,从零开始重新生成 DOCX 文档。这个过程模拟了从纯文本生成专业文档的真实场景,产生了大量结构和风格各异但内容相同的文档版本。此外,还设计了一种“改进智能体”,通过参考原始文档来优化已生成的文档。
-
标注偏好对: 将内容相同的文档进行配对,并标注优劣关系(winner/loser)。标注规则如下:
- 人工 vs. 生成: 如果一个文档是人工创作的原始专业文档,而另一个是智能体生成的,那么原始文档总是被标记为“优胜者 (winner)”。
- 生成 vs. 生成: 如果两个文档都是智能体生成的,则使用 GPT-5 作为代理标注者。通过向 GPT-5 提供原始专业文档作为参考,让其判断两个生成文档中哪一个更接近参考标准。
通过此流程,最终构建了 \(DocStruct-117K\) 数据集,包含 117,108 个文档对。
| 领域 | 文档类型 | 文档数 | 平均页数 | 文档对总数 | 人工 vs. 生成 | 生成 vs. 生成 |
|---|---|---|---|---|---|---|
| 32 | 267 | 69,137 | 3.2 | 117,108 | 36,664 | 80,444 |
模型结构与优化
-
模型结构: 本文采用 Qwen-2.5-VL 作为基础模型,因为它原生支持多图像输入,适合处理多页文档。文档的每一页都被渲染成一张图片输入模型。在模型之上增加一个回归头,用于输出一个代表专业性的标量分数。
-
优化目标: 训练过程采用 Bradley-Terry (BT) 损失函数。对于每一个偏好对 $(D^w, D^l)$,其中 $D^w$ 是优胜者,$D^l$ 是失败者,模型的目标是最大化两者分数之差。损失函数如下:
其中 $\mathcal{R}_{\theta}$ 是奖励模型,$\sigma$ 是 sigmoid 函数。该损失函数会惩罚模型给失败者打分高于优胜者的情况。
创新点
- 任务的独特性: 首次将文档评估的重点从“文本内容”转向“结构与风格”,填补了现有研究的空白。
- 数据驱动的方法: 通过构建大规模、内容一致、形式多样的偏好数据集 \(DocStruct-117K\),使模型能够以数据驱动的方式学习到专业的排版规范,实现了“文本质量无关性”。
- Pointwise评分模型: 最终训练出的 DocReward 是一个 pointwise 模型,即为单个文档打分。这避免了 pairwise 比较模型中常见的“位置偏见”(即模型倾向于选择呈现在第二个位置的选项)问题,评估结果更稳定可靠。
实验结论
本文通过内部和外部评估,全面验证了 DocReward 的有效性。
内部评估:准确性超越强基线
在一个由人类专家标注的测试集上,DocReward 的表现远超包括 GPT-5 在内的所有基线模型。
| 模型类型 | 模型 | Real vs. Synth (准确率%) | Synth vs. Synth (准确率%) | 总体 (准确率%) |
|---|---|---|---|---|
| Pairwise | ||||
| GPT-4o | 58.91 | 66.43 | 63.22 | |
| Claude Sonnet 4 | 57.86 | 69.02 | 64.26 | |
| GPT-5 | 64.78 | 72.32 | 69.10 | |
| Pointwise | ||||
| GPT-4o | 50.99 | 64.21 | 58.56 | |
| Claude Sonnet 4 | 48.02 | 66.79 | 58.77 | |
| GPT-5 | 64.85 | 73.43 | 69.77 | |
| DocReward-3B (本文) | 72.77 | 97.42 | 86.89 | |
| DocReward-7B (本文) | 78.22 | 97.42 | 89.22 |
- 卓越性能: DocReward-7B 的总体准确率达到 89.22%,比最强的闭源基线 GPT-5 (69.77%) 高出近 20个百分点。
- 场景优势: 在区分“人工专业文档”与“AI生成文档”时,DocReward 几乎完美(97.42% 准确率),表明它对专业标准有深刻的理解。
- 避免偏见: 实验发现,像 GPT-4o 这样的 pairwise 基线模型存在明显的位置偏见,而 pointwise 的 DocReward 则无此问题。
| 奖励模型 | 偏好位置1次数 | 偏好位置2次数 |
|---|---|---|
| GPT-4o | 202 | 271 |
| Claude Sonnet 4 | 189 | 284 |
| GPT-5 | 240 | 233 |
外部评估:有效指导文档生成
为了验证 DocReward 的实用价值,本文进行了一项外部评估:让一个文档生成智能体生成多个候选文档,然后分别使用 Random、GPT-5 和 DocReward 作为奖励模型来挑选最佳版本。结果由人类裁判进行最终评判。
| 奖励模型 | 胜率 (%) | 败率 (%) | 平局率 (%) |
|---|---|---|---|
| Random | 24.6 | 66.2 | 9.2 |
| GPT-5 | 37.7 | 40.0 | 22.3 |
| DocReward (本文) | 60.8 | 16.9 | 22.3 |
结果显示,使用 DocReward 挑选的文档获得了 60.8% 的胜率,远高于 GPT-5 (37.7%)。这证明 DocReward 的奖励信号与人类对结构和风格的偏好高度一致,能够有效指导生成智能体产出更受人类欢迎的文档。
可解释性分析
通过案例分析和注意力图可视化,可以发现 DocReward 确实在关注正确的信号。
-
案例分析: 对于同一内容的不同排版,DocReward 给出的分数与人类直觉相符。布局混乱、对齐不佳的文档得分低,而结构清晰、重点突出的文档得分高。



-
注意力图: 可视化结果显示,模型在做决策时,其注意力更多地集中在标题、编号、页眉页脚、项目符号、表格线和页边距等结构性元素上,而非具体的文本内容。



总结
实验结果有力地证明,DocReward 在评估文档的结构和风格专业性方面优于现有通用大模型,并且能作为一个有效的奖励模型,切实提高自动化文档生成的最终质量。