Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
-
ArXiv URL: http://arxiv.org/abs/2504.13837v2
-
作者: Zhiqi Chen; Andrew Zhao; Yang Yue; Gao Huang; Rui Lu; Shiji Song; Zhaokai Wang
-
发布机构: Shanghai Jiao Tong University; Tsinghua University
TL;DR
通过系统性地使用大\(k\)值的\(pass@k\)指标进行评估,本文发现当前的带可验证奖励的强化学习(RLVR)方法并未赋予大语言模型超越其基础模型的新推理能力,而仅仅是提升了对基础模型已有能力的采样效率,甚至可能缩小了模型的推理范围。
关键定义
- 带可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR): 一种训练语言模型的方法,其中模型根据自动计算的奖励信号进行优化。这些奖励是确定性的、可验证的(例如,数学题答案是否正确,代码是否通过单元测试),从而允许在没有人工标注的情况下进行大规模的强化学习训练。
- pass@k: 一种评估模型能力的指标。针对一个问题,从模型中采样 \(k\) 个输出。如果其中至少有一个输出是正确的,则认为模型“通过”了该问题(\(pass@k\)值为1),否则为0。在本文中,大 \(k\) 值的 \(pass@k\) 被用来评估模型推理能力的边界 (boundary) 或上限,即模型在足够多的尝试下能解决的问题范围。
- 推理能力边界 (Reasoning Capability Boundary): 指一个模型在理想情况下(如通过大量采样)能够解决的问题集合的范围。本文使用大 \(k\) 值的 \(pass@k\) 作为衡量这一边界的代理指标。
- 采样效率差距 ($\Delta_{SE}$): 本文提出的一个度量指标,定义为RLVR训练后模型的 \(pass@1\) 与其基础模型在大 \(k\) 值下的 \(pass@k\) (本文用k=256) 之间的差异。该指标用于量化RL算法在多大程度上利用了基础模型所设定的能力上限。
相关工作
当前,以带可验证奖励的强化学习(RLVR)为核心的技术,如OpenAI-o1和DeepSeek-R1,在提升大语言模型(LLM)的数学和编程等复杂推理能力方面取得了巨大成功。学界和业界普遍认为,RLVR能够像传统强化学习在游戏(如AlphaGo)中一样,通过自我探索和改进,帮助LLM发现全新的推理模式,从而超越其原始基础模型的能力。
然而,这种信念缺乏严格的实证检验。当前RLVR方法的真正效果仍不清晰。本文旨在解决一个根本性问题:当前的RLVR方法究竟是真正地激发了模型学习到全新的推理能力,还是仅仅优化了对基础模型中已存在的推理路径的利用效率?
本文方法
本文并未提出一个新的模型,而是设计了一套严谨的分析框架来深入剖斥现有RLVR方法对LLM推理能力的影响。其核心是通过对比RLVR训练后的模型与其对应的基础模型在推理能力边界上的差异,来回答引言中提出的核心问题。
核心评估框架:以大k值的pass@k衡量推理边界
传统的评估指标(如greedy decoding或\(pass@1\))衡量的是模型的平均表现,但这可能会低估模型的真实潜力。一个模型可能在几次尝试内失败,但只要有能力在更多次尝试中生成正确解,就说明该问题在其能力边界之内。
为了更准确地评估这一边界,本文采用\(pass@k\)指标,并考察\(k\)值较大(如\(k=256\)或更高)时的表现。如果RLVR能激发新能力,那么RLVR训练后的模型在大\(k\)值下的\(pass@k\)应该能超越基础模型,解决基础模型无法解决的新问题。
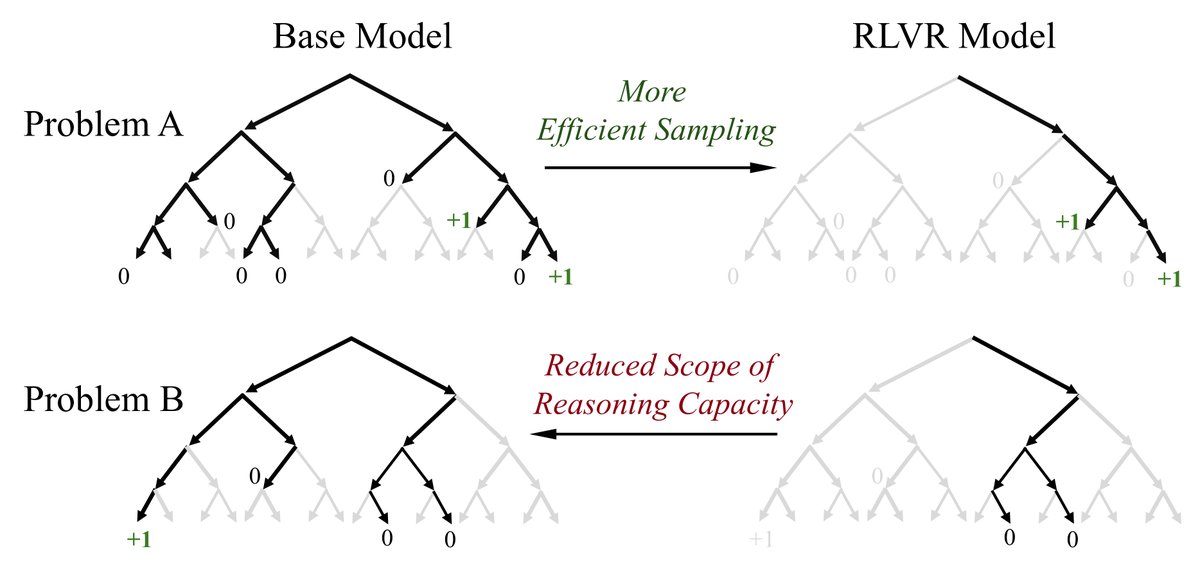
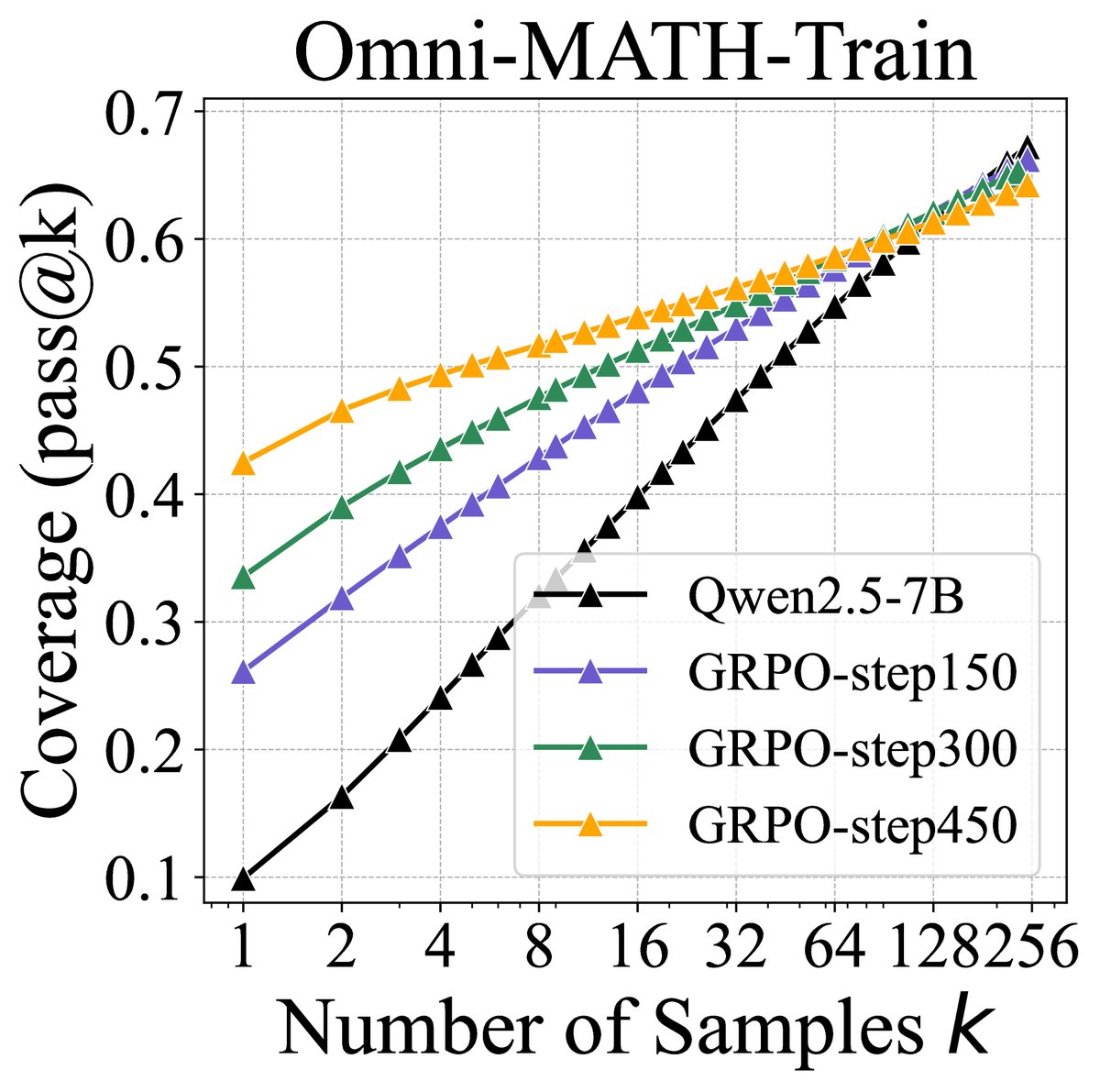 图1:(左)当前RLVR对LLM推理能力影响的示意图。灰色路径表示模型不太可能采样的路径,黑色表示可能采样的路径,绿色表示正确的、有正向奖励的路径。本文核心发现是RLVR模型中的所有推理路径(如问题A)都已存在于基础模型中。RLVR通过调整分布提高了正确路径的采样效率,但代价是推理范围的缩小:对于另一些问题(如问题B),基础模型能找到正确路径,而RLVR模型却不能。(右)随着RLVR训练的进行,模型的平均性能(\(pass@1\))提升,但可解决问题的覆盖率(\(pass@256\))下降,表明推理边界在缩小。
图1:(左)当前RLVR对LLM推理能力影响的示意图。灰色路径表示模型不太可能采样的路径,黑色表示可能采样的路径,绿色表示正确的、有正向奖励的路径。本文核心发现是RLVR模型中的所有推理路径(如问题A)都已存在于基础模型中。RLVR通过调整分布提高了正确路径的采样效率,但代价是推理范围的缩小:对于另一些问题(如问题B),基础模型能找到正确路径,而RLVR模型却不能。(右)随着RLVR训练的进行,模型的平均性能(\(pass@1\))提升,但可解决问题的覆盖率(\(pass@256\))下降,表明推理边界在缩小。
创新点
本文的方法论创新在于:
- 范式转变:将评估重点从“平均性能” (\(pass@1\)) 转移到“能力边界” (\(pass@k\) for large \(k\)),从而能够解耦模型的“采样效率”和“固有能力”。
- 系统性质疑:通过这一新范式,对当前领域关于RLVR能“创造新能力”的主流信念提出了强有力的、基于数据的质疑。
- 深度诊断工具:结合困惑度分析和可解决问题集分析,提供了一套诊断工具,用于判断模型能力的提升是源于学习新知识还是优化旧知识。
优点
该分析框架具有以下优点:
- 严谨性:能清晰地揭示RLVR的真实作用机制,避免被表面的平均性能提升所误导。
- 通用性:可广泛应用于不同模型、不同任务和不同RL算法的评估,本文的实验覆盖了数学、编码和视觉推理三大领域,证明了其通用性。
- 启发性:研究结果为未来RL方法的发展指明了方向——即需要关注如何真正扩展模型的能力边界,而非仅仅在现有能力上进行优化。
实验结论
本文通过在数学、代码生成和视觉推理三大领域的广泛实验,系统地评估了RLVR对LLM推理能力边界的影响。实验设置总览如下表所示。
表1:评估RLVR对LLM推理边界影响的实验设置
| 任务 | 起始模型 | RL框架 | RL算法 | 基准测试 |
|---|---|---|---|---|
| 数学 | LLaMA-3.1-8B, Qwen2.5-7B/14B/32B-Base, Qwen2.5-Math-7B | SimpleRLZoo, Oat-Zero, DAPO | GRPO | GSM8K, MATH500, Minerva, Olympiad, AIME24, AMC23 |
| 代码生成 | Qwen2.5-7B-Instruct, DeepSeek-R1-Distill-Qwen-14B | Code-R1, DeepCoder | GRPO | LiveCodeBench, HumanEval+ |
| 视觉推理 | Qwen2.5-VL-7B | EasyR1 | GRPO | MathVista, MathVision |
| 深度分析 | Qwen2.5-7B-Base, Qwen2.5-7B-Instruct, DeepSeek-R1-Distill-Qwen-7B | VeRL | PPO, GRPO, Reinforce++, RLOO, ReMax, DAPO | Omni-Math-Rule, MATH500 |
RLVR模型的推理边界反而比基础模型更窄
在所有任务和模型上,实验揭示了一个一致且令人惊讶的模式:
- 在\(k\)值较小(如\(k=1\))时,RLVR训练后的模型表现优于其基础模型,这与普遍观察到的RLVR提升模型平均性能的结论一致。
- 然而,随着\(k\)值的增大,基础模型的\(pass@k\)曲线持续上升并最终超越了RLVR模型。
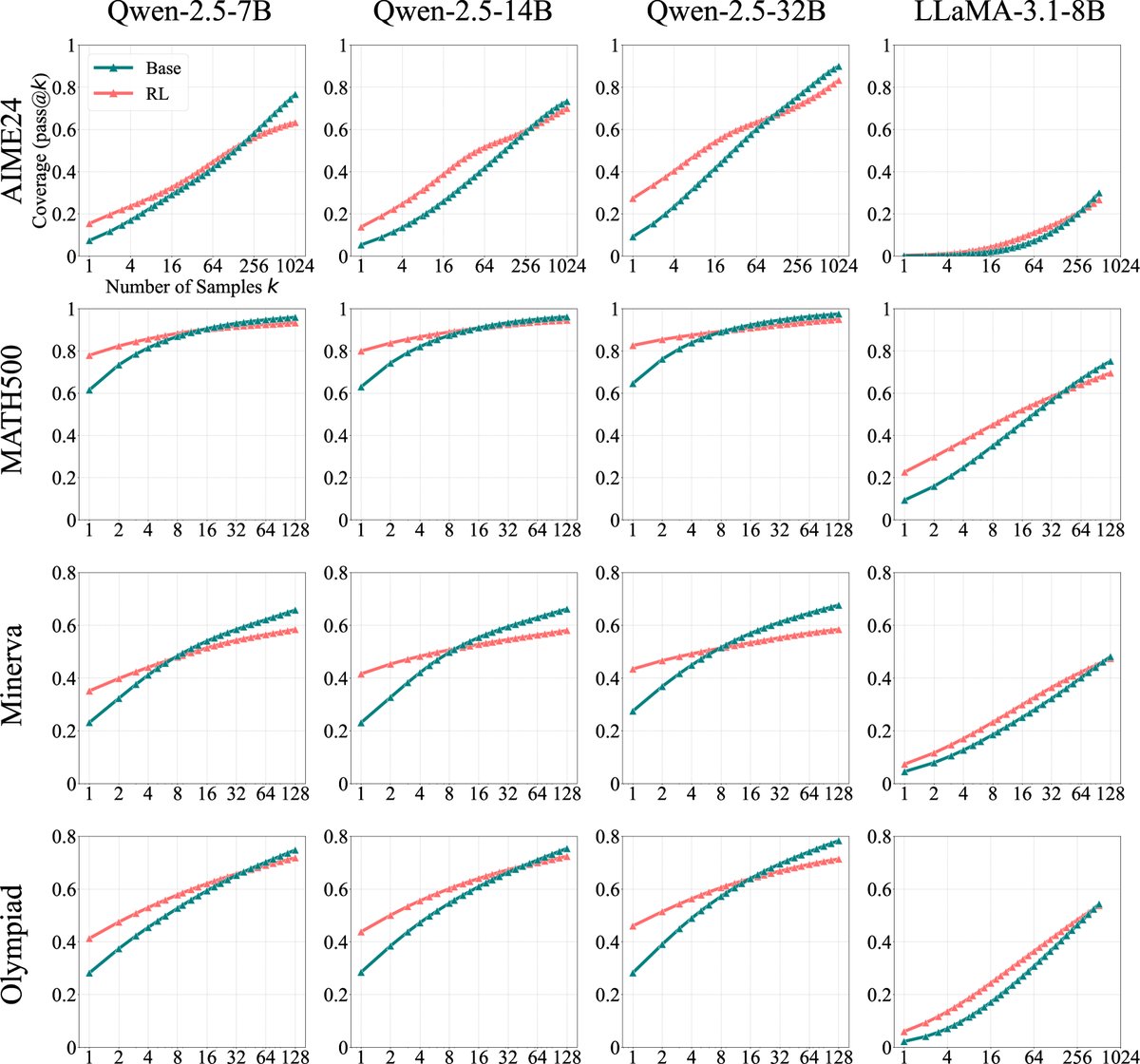 图2:在多个数学基准上,基础模型及其RLVR训练后模型的\(pass@k\)曲线。当\(k\)值较小时,RL模型表现更好;但当\(k\)增大至几十或几百时,基础模型稳定地反超RL模型。
图2:在多个数学基准上,基础模型及其RLVR训练后模型的\(pass@k\)曲线。当\(k\)值较小时,RL模型表现更好;但当\(k\)增大至几十或几百时,基础模型稳定地反超RL模型。
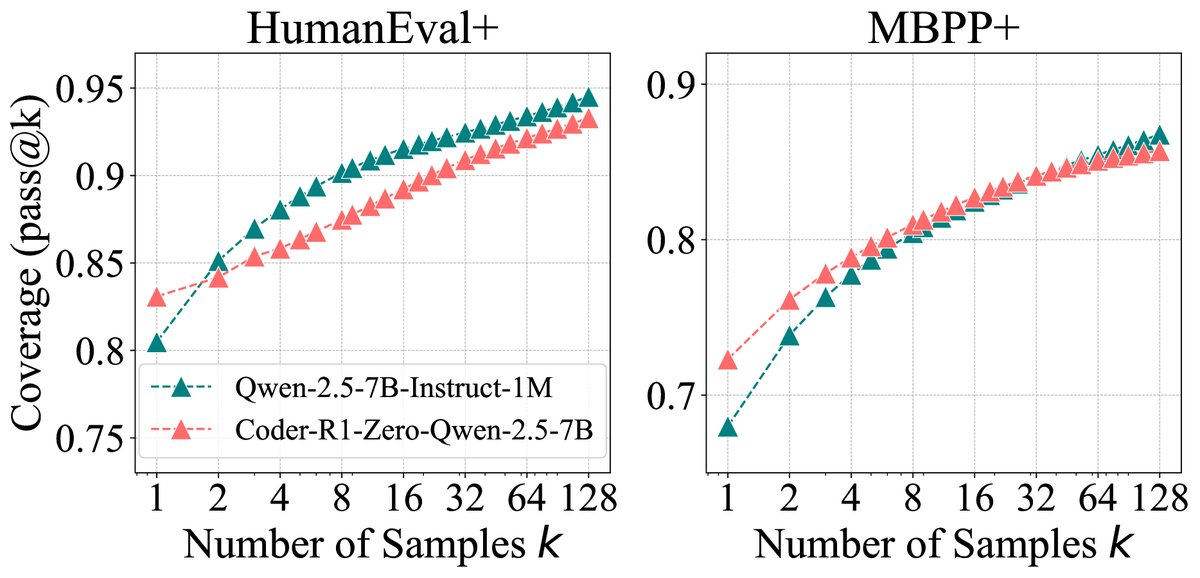
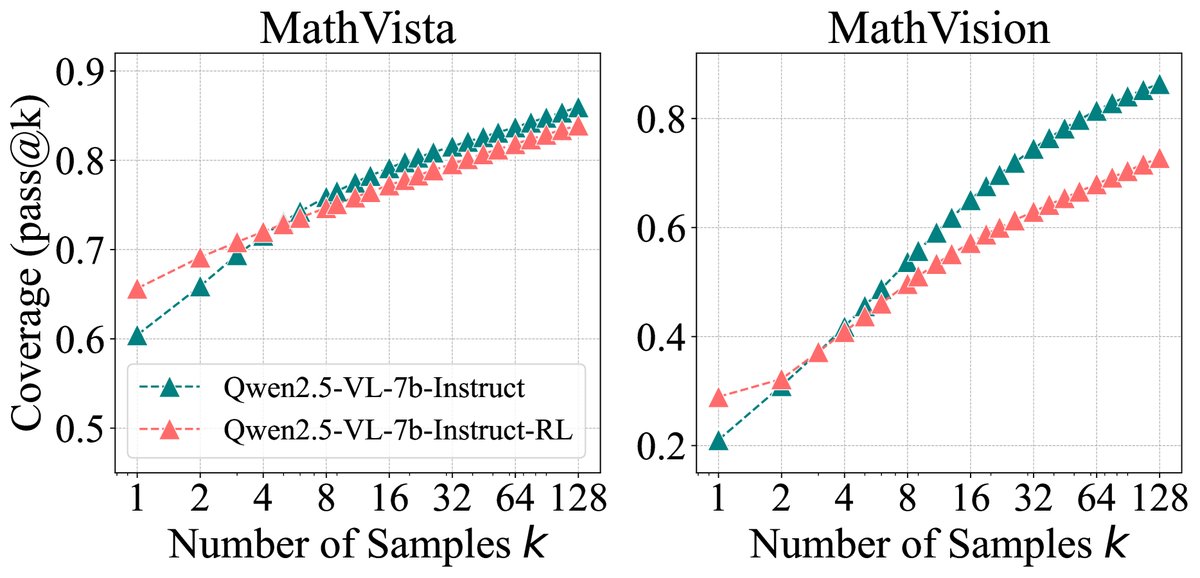 图4:基础模型与RLVR模型的\(pass@k\)曲线对比。(左)代码生成任务;(右)视觉推理任务。结果与数学任务一致。
图4:基础模型与RLVR模型的\(pass@k\)曲线对比。(左)代码生成任务;(右)视觉推理任务。结果与数学任务一致。
这一结果有力地表明,当前RLVR训练并未拓展模型的能力边界,甚至在某种程度上缩小了它。RLVR模型解决的问题集几乎是基础模型可解决问题集的子集。
RLVR利用的推理路径已存在于基础模型中
为了探究边界缩小的原因,本文进行了更深入的分析:
- 准确率分布分析:RLVR训练将模型在某些问题上的求解准确率推向了100%,但代价是让另一些原本有较低概率求解的问题变得完全无法求解(准确率降为0)。这解释了为何平均分(\(pass@1\))提高,而能力边界(\(pass@256\))却下降。
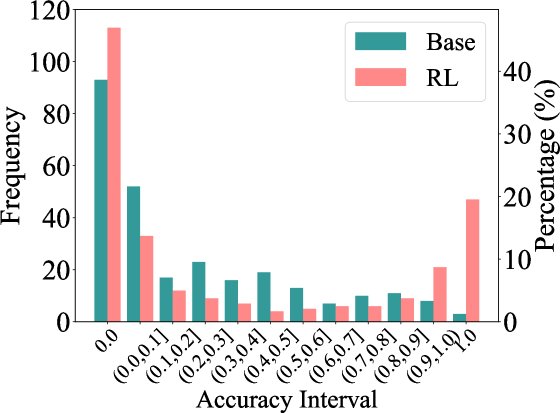 图5:Qwen2.5-7B在Minerva数据集上的准确率直方图。RLVR训练后,高准确率(接近1.0)的问题增多,但零准确率的问题也增多了。
图5:Qwen2.5-7B在Minerva数据集上的准确率直方图。RLVR训练后,高准确率(接近1.0)的问题增多,但零准确率的问题也增多了。
- 困惑度(Perplexity)分析:通过计算RLVR模型生成的推理路径在基础模型下的困惑度,发现这些路径的困惑度非常低,与基础模型自身高频生成的路径分布一致。这说明RLVR模型“发现”的推理路径,实际上是基础模型本就倾向于生成的路径。
<img src=”/images/2504.13837v2/x8.jpg” alt=”Refer to “Figure 6: Perplexity distribution of responses. The conditioning problem $x$ is omitted in the figure.”” style=”width:85%; max-width:450px; margin:auto; display:block;”> 图6:响应的困惑度分布。\(Base(RL)\)表示用基础模型评估RL模型生成的响应。其分布与基础模型自身生成的高概率响应(\(Base(Base)\)的左侧部分)高度重合,表明RL模型的输出在基础模型的分布之内。
RLVR与蒸馏的本质区别
与RLVR不同,通过知识蒸馏(distillation)从更强大的教师模型中学习,可以真正扩展学生模型的能力边界。实验表明,蒸馏后的模型在所有\(k\)值上都显著优于其基础模型,因为它引入了基础模型本身不具备的新推理模式。
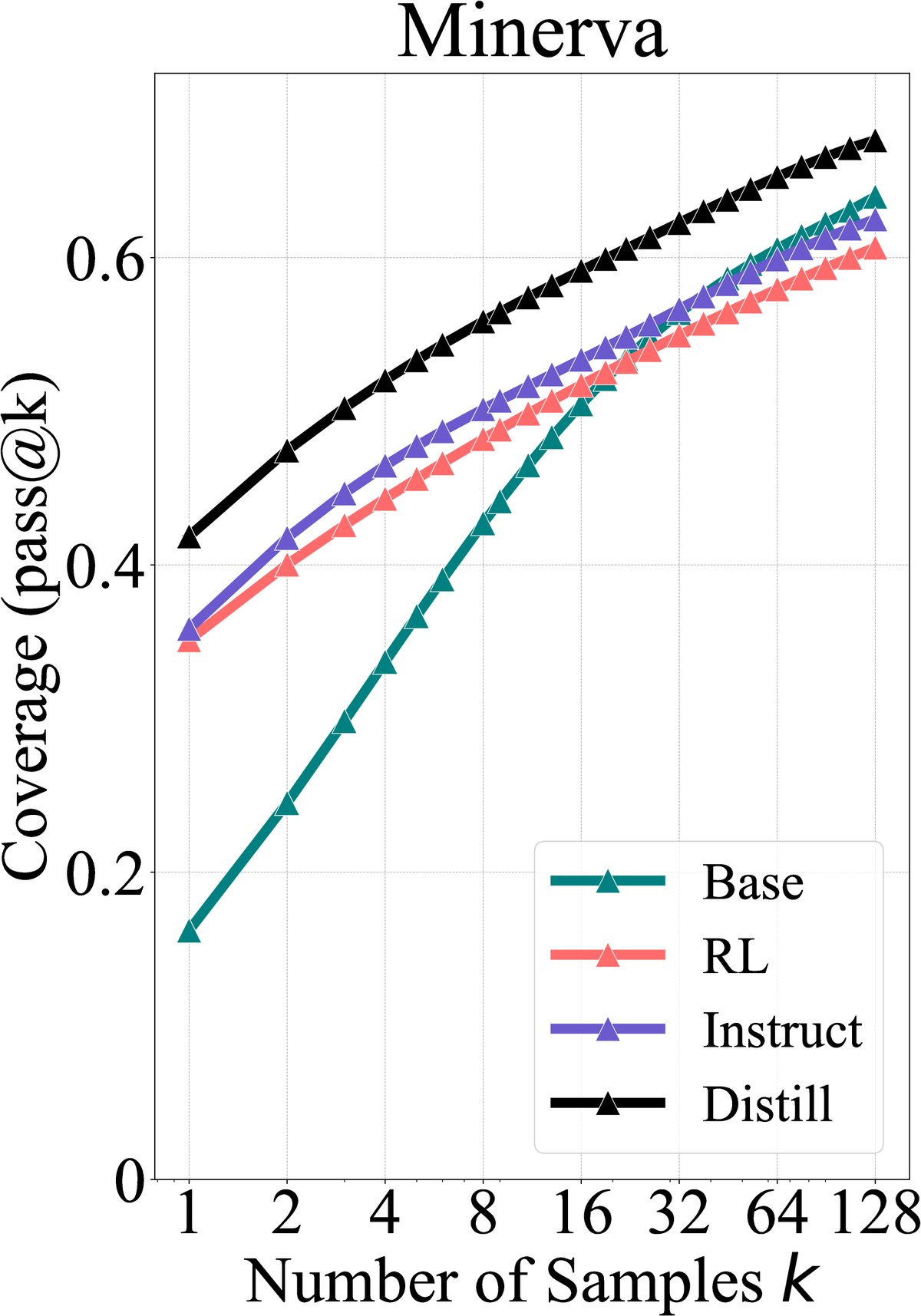 图7:基础模型、指令微调模型、RLVR模型和蒸馏模型的覆盖范围对比。只有蒸馏模型(蓝色)的\(pass@k\)曲线全面超越了基础模型(绿色),实现了能力边界的扩展。
图7:基础模型、指令微调模型、RLVR模型和蒸馏模型的覆盖范围对比。只有蒸馏模型(蓝色)的\(pass@k\)曲线全面超越了基础模型(绿色),实现了能力边界的扩展。
不同RL算法表现相似且远未达到最优
本文提出的采样效率差距($\Delta_{SE}$)指标显示,PPO、GRPO等六种主流RLVR算法在提升采样效率方面的表现相近,差异微小,并且都远未达到基础模型的能力上限。这表明问题可能出在RLVR这一范式本身,而非具体算法实现。
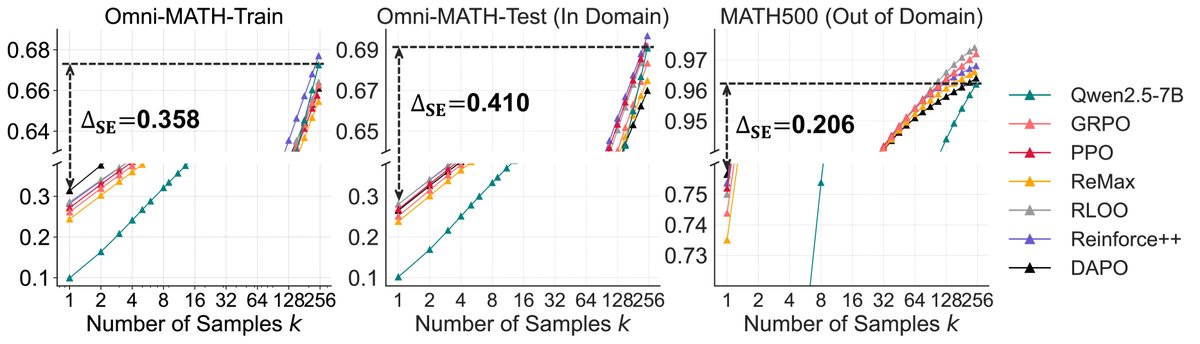 图8:不同RL算法的性能对比。尽管\(pass@1\)略有差异,但所有算法训练后模型的\(pass@256\)都低于基础模型(虚线),且采样效率差距($\Delta_{SE}$)都很大,表明它们远未充分利用基础模型的潜力。
图8:不同RL算法的性能对比。尽管\(pass@1\)略有差异,但所有算法训练后模型的\(pass@256\)都低于基础模型(虚线),且采样效率差距($\Delta_{SE}$)都很大,表明它们远未充分利用基础模型的潜力。
总结
本文的结论是,当前主流的RLVR方法并未实现通过探索和自我改进来激发LLM产生新推理能力的潜力。它的实际作用更像一个“放大器”,通过强化奖励信号来提升对基础模型已有能力的采样效率,但这个过程伴随着对多样化探索的抑制,最终导致模型推理边界的收缩。
这些发现揭示了当前RLVR范式与实现持续自我进化的通用智能体之间的差距,并强调了未来研究需要探索新的RL范式,例如结合持续扩展模型规模、改进探索策略以及引入多轮智能体-环境交互,以真正释放强化学习在LLM中的潜力。