Effective context engineering for AI agents
-
ArXiv URL: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
-
作者:
TL;DR
本文提出了“上下文工程” (Context Engineering) 的概念,主张将 AI 智能体开发的重点从编写静态提示词(prompt)转向动态地策划和管理输入给模型的全部信息(即上下文),从而在模型有限的注意力预算下,实现更可靠、更高效的智能体行为。
关键定义
本文的核心是围绕“上下文工程”展开的,其关键定义如下:
- 上下文 (Context): 指在从大语言模型(LLM)进行采样时所包含的所有 Token 的集合,包括系统指令、工具、外部数据、消息历史等。
- 上下文工程 (Context Engineering): 指在 LLM 推理过程中,为策划和维护最优 Token 集合(即信息)而采用的一系列策略。其核心是优化这些 Token 的效用,同时应对 LLM 的内在限制,以持续实现预期结果。它被视为提示工程 (Prompt Engineering) 的自然演进。
- 上下文腐烂 (Context Rot): 指随着上下文窗口中 Token 数量的增加,模型准确回忆其中信息的能力随之下降的现象。这使得上下文成为一种边际收益递减的有限资源。
- 注意力预算 (Attention Budget): 一个形象的比喻,用以描述 LLM 在解析大量上下文时有限的“工作记忆”或“注意力”容量。引入的每一个新 Token 都会消耗一部分预算,因此需要仔细策划上下文内容。
相关工作
目前,应用 AI 领域长期关注的焦点是提示工程,即如何为 LLM 编写和组织指令以获得最佳结果。这种方法在处理单轮分类或文本生成等离散任务时非常有效。
然而,随着研究转向开发更强大、能够在更长时间跨度内进行多轮推理的智能体,一个关键瓶颈日益凸显:LLM 的上下文窗口是有限的。当一个智能体在循环中运行时,会产生越来越多可能相关的信息。若将所有信息不加选择地塞入上下文,会导致“上下文腐烂”问题,即模型的性能(如信息检索精度和远距离推理能力)会因上下文过长而下降。这种性能下降源于 Transformer 架构的内在限制(\($n^2\)$ 的注意力关系)和训练数据中长序列样本较少的事实。
因此,本文旨在解决的核心问题是:如何有效地管理和策划不断演变的信息,从中挑选出最有价值的部分放入有限的上下文窗口,以构建能够在长时程任务中保持连贯性和高效性的 AI 智能体?
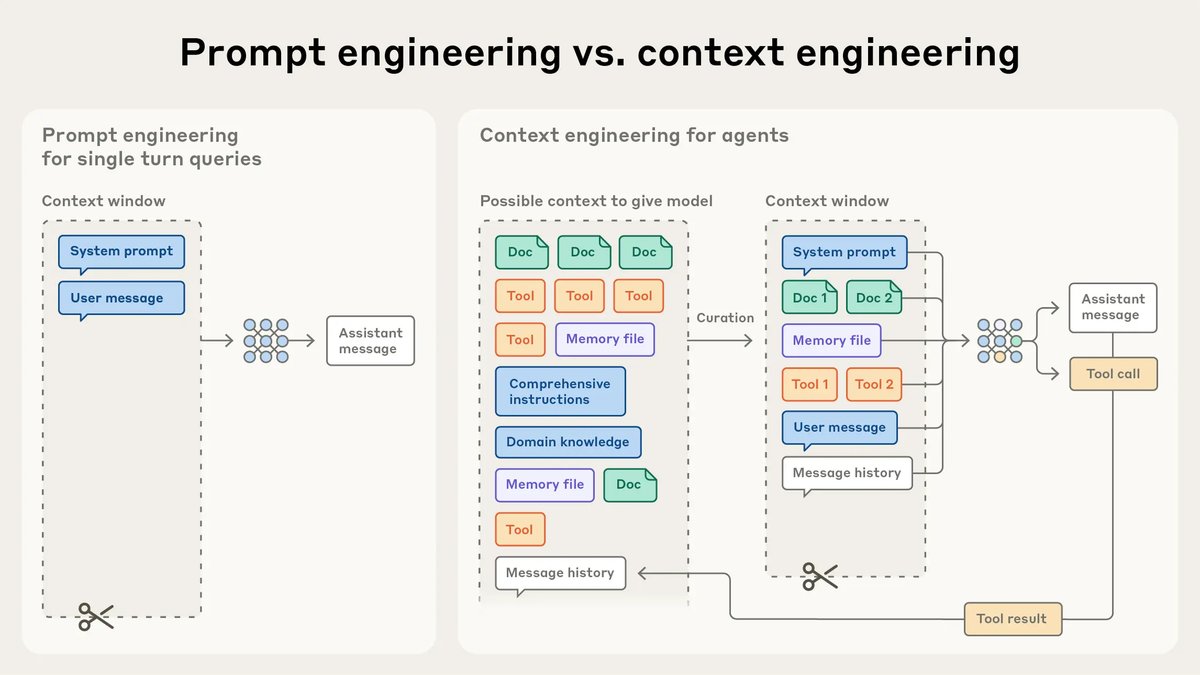
本文方法
本文将“上下文工程”的核心原则定义为:找到能够最大化预期结果概率的、最小且信噪比最高的一组 Token。围绕此原则,本文从静态上下文构成和动态上下文管理两个维度,提出了一套完整的方法论。
静态上下文的构成
静态上下文是指在推理开始前设定的相对固定的部分,优化这些部分是上下文工程的基础。
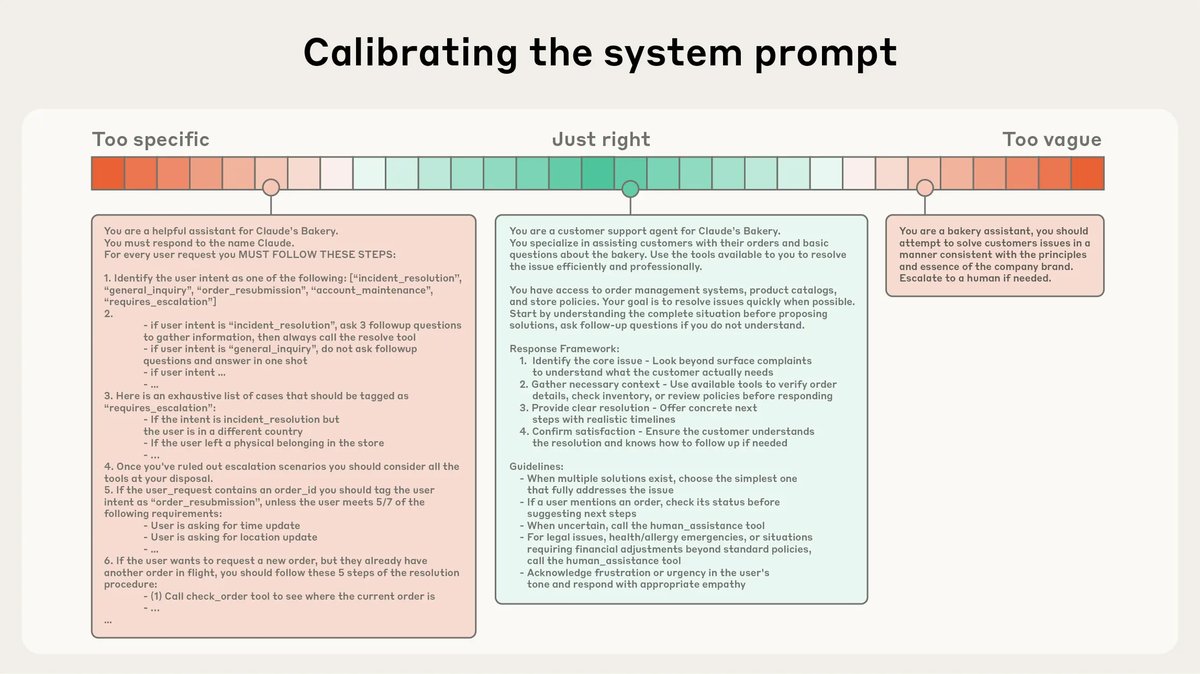
- 系统提示 (System Prompts):应使用清晰、简单、直接的语言。关键在于找到“合适的高度” (right altitude):既要避免过于具体、逻辑僵化的硬编码指令(这会使系统脆弱且难以维护),也要避免过于模糊、缺乏具体指导的空泛描述。推荐使用 XML 标签或 Markdown 标题(如 \(<instructions>\), \(## Tool guidance\))将提示词划分为不同部分,以增强结构性。目标是提供能够充分勾勒预期行为的最小信息集。
-
工具 (Tools):工具定义了智能体与环境交互的契约。好的工具设计应促进效率,包括返回 Token 高效的信息和鼓励智能体采取高效的行为。工具应像设计良好的代码库中的函数一样,功能自洽、鲁棒且用途明确。一个常见的失败模式是工具集功能臃肿或存在功能重叠,导致智能体在决策时产生混淆。
-
示例 (Examples):提供示例(即少样本提示)是公认的最佳实践。但应避免堆砌大量边缘案例,而应精心策划一组多样化、具有代表性的规范示例,因为对 LLM 而言,好的示例“胜过千言万语”。
动态上下文检索与智能体搜索
对于更高级的智能体,上下文管理是动态的。
-
“即时”上下文策略 (Just-in-Time Context):传统的做法是在推理前通过嵌入检索(RAG)预先加载所有相关数据。本文提倡一种更智能的“即时”策略,即智能体在运行时使用工具,根据需要动态地将数据加载到上下文中。智能体只维护轻量级的标识符(如文件路径、查询语句、URL),并自主决定何时、何地加载何种信息。这种方法模拟了人类利用文件系统、书签等外部索引系统来按需检索信息的认知过程。
- 优点:
- 存储高效:无需将海量数据对象一次性载入上下文。
- 利用元数据:文件名、文件夹结构、时间戳等元数据为智能体提供了丰富的隐式信号。
- 渐进式信息披露 (Progressive Disclosure):智能体通过探索逐步构建对环境的理解,只在工作记忆中保留必要信息。
- 混合策略: 在实践中,可以将预检索和即时探索相结合。例如,前置加载一些高频或关键信息,同时赋予智能体自主探索和检索更多细节的能力。
面向长时程任务的上下文工程技术
当任务时间跨度超过单个上下文窗口的容量时(如大型代码库迁移、综合性研究项目),必须采用专门的技术来解决上下文限制。
-
压缩 (Compaction):当对话历史接近上下文窗口上限时,让模型对现有内容进行总结和压缩,然后用这个摘要开启一个新的上下文窗口。这能有效保持智能体的行为连贯性。压缩的关键在于平衡信息召回率和摘要的精确度。一种简单安全的压缩形式是工具结果清理,即清除历史记录中旧的工具调用及其原始结果,因为智能体通常不需要再次查看原始输出。
-
结构化笔记 (Structured Note-taking):也称为智能体记忆 (Agentic Memory)。该技术让智能体定期将关键信息、决策、待办事项等以结构化形式(如 \(NOTES.md\) 文件)写入到上下文窗口之外的持久化存储中。在需要时,智能体可以重新读取这些笔记来恢复上下文。这种简单的模式极大地增强了智能体在复杂任务中的长期记忆和状态跟踪能力。例如,玩《宝可梦》的 Claude 智能体通过记录笔记,能够跨越数小时的游戏时间保持策略连贯性。
-
子智能体架构 (Sub-agent Architectures):将一个庞大的任务分解,由一个主智能体负责高层规划和协调,并将具体的子任务分配给多个专门的子智能体。每个子智能体在自己独立的、干净的上下文窗口中完成深度技术工作或信息搜集,然后只向主智能体返回一个精简的、几千 Token 的摘要。这种“分而治之”的策略实现了关注点分离,避免了主智能体被海量细节淹没,显著提升了在复杂研究任务上的表现。
下表总结了不同长时程技术的适用场景:
| 技术 | 描述 | 最佳适用场景 |
|---|---|---|
| 压缩 (Compaction) | 总结并重置上下文,保留核心信息。 | 需要大量来回交互、保持对话流畅性的任务。 |
| 结构化笔记 (Note-taking) | 智能体在外部文件中记录和读取状态。 | 具有明确里程碑、需要迭代开发的任务。 |
| 子智能体架构 (Multi-agent) | 主智能体协调多个专注的子智能体。 | 复杂的并行研究和分析任务。 |
实验结论
本文虽未提供传统的定量实验数据,但通过其在构建实际系统(如 \(Claude Code\)、多智能体研究系统、玩《宝可梦》的智能体)中的应用,验证了上下文工程的有效性。
- 主要优势验证:
- 实现长时程任务: \(压缩\)、\(结构化笔记\)和\(子智能体架构\)等技术被证明是解决上下文窗口限制、使智能体能够执行数小时连续工作的有效手段。例如,\(Claude Code\) 利用压缩和即时文件访问来处理大型代码库;玩《宝可梦》的智能体通过笔记实现了跨越数千个游戏步骤的策略一致性。
- 提升复杂任务性能:在复杂的科研任务中,采用\(子智能体架构\)的系统比单一智能体系统表现出“显著的提升”。
- 提高效率与鲁棒性:“即时”上下文检索策略让智能体能像人类一样高效地处理海量数据,而无需将所有数据都加载到内存中,从而避免了上下文过载。
- 场景表现:
- 表现最佳: 这些方法在需要跨越 LLM 单次上下文窗口限制的长时程、多步骤、信息密集型任务中表现最为出色,例如复杂的软件工程、深度研究分析和需要长期记忆的游戏策略。
- 权衡与考量: 本文也指出了其中的权衡。例如,“即时”探索比预计算检索要慢,并且需要精心设计的工具和启发式规则来引导智能体,否则可能浪费上下文。
- 最终结论: 上下文工程代表了利用 LLM 构建应用的根本性转变。随着模型能力的提升,工程挑战不再仅仅是编写完美的提示词,而是要 thoughtfully 地在智能体推理的每一步,精心策划进入其有限注意力预算的信息。将上下文视为一种宝贵且有限的资源,是构建可靠、高效智能体的核心原则。虽然具体技术会不断演进,但这一指导思想将长期适用。