Efficient Streaming Language Models with Attention Sinks
-
ArXiv URL: http://arxiv.org/abs/2309.17453v4
-
作者: Yuandong Tian; Guangxuan Xiao; Beidi Chen; Mike Lewis; Song Han
-
发布机构: Carnegie Mellon University; Massachusetts Institute of Technology; Meta AI; NVIDIA
TL;DR
本文提出了一种名为 StreamingLLM 的高效框架,通过保留少量初始 Token 作为“注意力池 (Attention Sinks)”来稳定注意力分布,从而使预训练好的大语言模型无需微调即可处理无限长的流式输入。
关键定义
本文提出了一个核心概念来解释其发现的现象:
- 注意力池 (Attention Sink):指在自回归语言模型中,一小部分初始位置的 Token 会获得不成比例的大量注意力分数,即使这些 Token 在语义上并不重要。这种现象的产生是因为注意力机制中的 Softmax 操作要求所有注意力分数之和为1,模型倾向于将“多余”的注意力分配给一些固定的位置,而初始 Token 因为在自回归训练中对所有后续 Token 可见,最容易被训练成这样的“池子”,以稳定整个注意力分布。移除这些初始 Token 会导致注意力分布剧烈变化,模型性能崩溃。
相关工作
当前在长文本处理领域的研究主要集中在三个方向:长度外推、扩展上下文窗口和提升长文本利用率。
现有方法存在明显的瓶颈:
- 长度外推能力有限:虽然如旋转位置编码 (Rotary Position Embeddings, RoPE) 和 ALiBi 等相对位置编码方法被提出用于增强模型的长度外推能力,但当测试文本长度远超训练长度时,这些模型性能仍然会下降,无法实现无限长度的处理。
- 上下文窗口终究有限:通过如 FlashAttention 等系统优化或对模型进行微调,可以扩展模型的上下文窗口(例如从 4k 到 32k),但这仅仅是扩展到了一个更大的有限长度,并没有解决需要处理无限长输入的流式应用(如多轮对话)的根本问题。
因此,当前没有任何一个主流的 LLM 能够直接且高效地部署在需要处理无限长文本的流式应用中。本文旨在解决这一具体问题,即如何在不牺牲性能和效率的前提下,让预训练LLM能够处理无限长的输入。
本文方法
注意力池:窗口注意力的失败根源
传统的窗口注意力 (Window Attention) 方法虽然高效,但性能很差。本文通过实验发现,其性能崩溃的关键节点在于初始 Token 的键值(KV)缓存被丢弃时。
 图3:不同LLM在20K长文本上的语言建模困惑度(Perplexity)。可以观察到:(1) 密集注意力的性能在输入超过预训练长度后下降。(2) 窗口注意力的性能在输入超过缓存大小、初始Token被丢弃后急剧恶化。(3) StreamingLLM表现稳定,其困惑度与滑动窗口重计算基线相当。
图3:不同LLM在20K长文本上的语言建模困惑度(Perplexity)。可以观察到:(1) 密集注意力的性能在输入超过预训练长度后下降。(2) 窗口注意力的性能在输入超过缓存大小、初始Token被丢弃后急剧恶化。(3) StreamingLLM表现稳定,其困惑度与滑动窗口重计算基线相当。
通过可视化注意力图谱,作者发现,LLM(如 Llama-2)的许多注意力头会持续地将大量注意力分数分配给最初的几个 Token,即使这些 Token 语义上并不重要。作者将这种现象命名为注意力池 (Attention Sink)。
其产生原因在于 Softmax 函数要求注意力权重之和为1。即使当前查询与上下文中的许多 Token 都不相关,模型也必须将这些“无处安放”的注意力分数分配到某个地方。由于自回归的训练方式,初始 Token 对后续所有 Token 都是可见的,因此它们最容易被训练成承接这些多余注意力的“池子”,从而稳定整体注意力分布。
实验证明,这种重要性与位置有关,而非语义。即使将最初的4个 Token 替换为无意义的换行符,只要保留它们,模型的性能就能恢复。
表1: 窗口注意力在长文本上表现不佳。当我们将最初的四个 Token 与最近的1020个 Token 一起重新引入时,困惑度得以恢复。用换行符”\n”替换原始的四个初始 Token(4”\n”+1020)也能达到相当的困惑度恢复效果。缓存配置x+y表示添加x个初始 Token 和y个最近的 Token。
| Llama-2-13B | PPL ($\downarrow$) |
|---|---|
| 0 + 1024 (窗口) | 5158.07 |
| 4 + 1020 | 5.40 |
| 4”\n”+1020 | 5.60 |
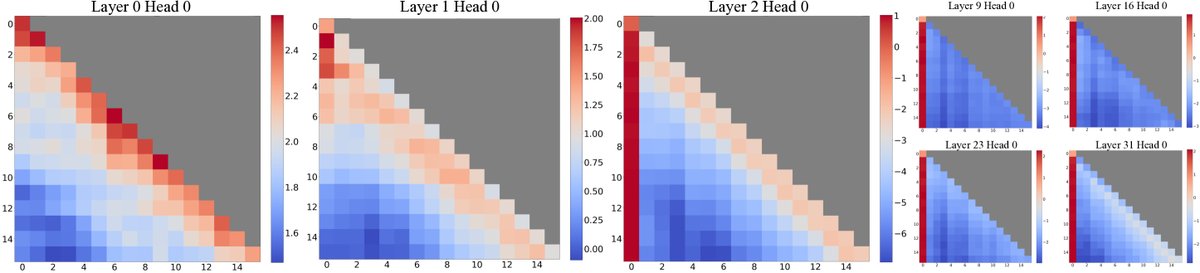 图2:Llama-2-7B在256个16词句子上的平均注意力对数(logits)可视化。观察发现:(1) 最底两层(layer 0, 1)注意力呈现“局部”模式,关注最近的 Token。(2) 在更高层,模型在所有层和头上都严重关注初始 Token。
图2:Llama-2-7B在256个16词句子上的平均注意力对数(logits)可视化。观察发现:(1) 最底两层(layer 0, 1)注意力呈现“局部”模式,关注最近的 Token。(2) 在更高层,模型在所有层和头上都严重关注初始 Token。
StreamingLLM:保留注意力池的滚动缓存
基于注意力池的发现,本文提出了 StreamingLLM 框架。其核心思想非常简单:在滚动的 KV 缓存中,除了保留最近的一部分 Token,始终保留最初的几个 Token(如4个)作为注意力池。
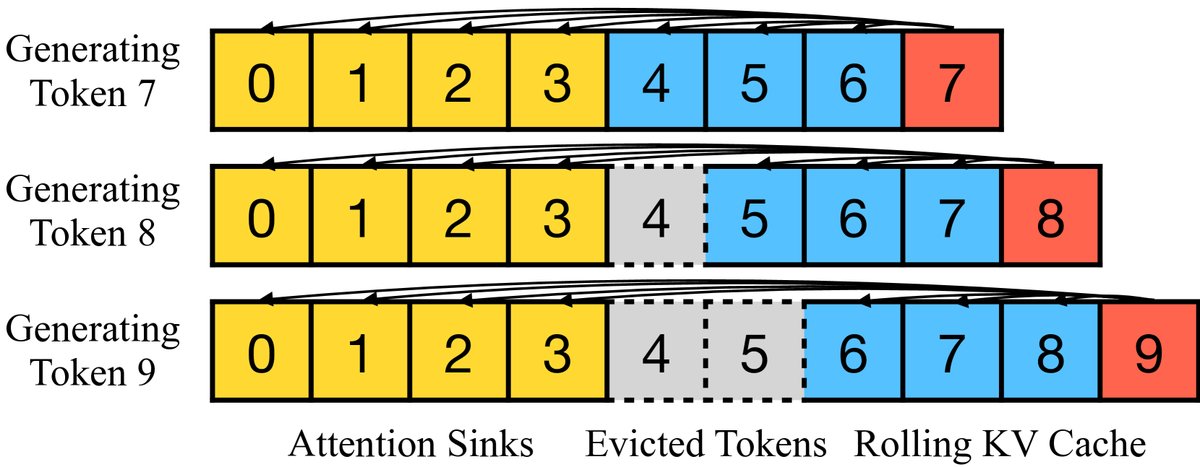 图4:StreamingLLM 的 KV 缓存结构。它包含两部分:用于稳定注意力计算的注意力池(几个初始Token),以及用于语言建模的滚动KV缓存(最近的Token)。
图4:StreamingLLM 的 KV 缓存结构。它包含两部分:用于稳定注意力计算的注意力池(几个初始Token),以及用于语言建模的滚动KV缓存(最近的Token)。
这种方法的关键技术细节在于位置编码的处理。StreamingLLM 在计算相对位置时,是根据 Token 在当前缓存中的相对位置,而不是其在原始文本中的绝对位置。例如,一个缓存中包含原始位置为 \([0, 1, 2, 3]\) 的注意力池和 \([100, 101, 102]\) 的最近 Token,那么在计算注意力时,它们在缓存中的位置会被当作 \([0, 1, 2, 3, 4, 5, 6]\) 来处理。这使得模型能够在其预训练的注意力窗口长度内有效工作,即使处理的文本总长度已经远超该范围。
通过预训练优化:引入专用的注意力池 Token
本文进一步推断,现有模型之所以需要多个(如4个)初始 Token 作为注意力池,是因为在预训练阶段没有一个统一固定的起始 Token。
因此,本文提出了一个改进的预训练策略:在所有训练样本的开头,加入一个可学习的专用“池 Token (Sink Token)”。实验通过从头训练1.6亿参数的模型证明,这种方法非常有效:
- Vanilla 模型:需要保留4个初始 Token 才能在流式推理中保持低困惑度。
- Sink Token 模型:仅需保留该专用的 Sink Token,即可实现同样稳定甚至略优的流式推理性能。
表3:不同预训练策略的流式推理性能对比。Vanilla模型需要多个初始Token才能稳定。引入可学习的Sink Token的模型仅需保留该Token本身即可。缓存配置x+y表示x个初始Token和y个最近Token。
| 缓存配置 | 0+1024 | 1+1023 | 2+1022 | 4+1020 |
|---|---|---|---|---|
| Vanilla | 27.87 | 18.49 | 18.05 | 18.05 |
| Zero Sink | 29214 | 19.90 | 18.27 | 18.01 |
| Learnable Sink | 1235 | 18.01 | 18.01 | 18.02 |
这一发现为未来训练更适合流式部署的 LLM 提供了明确的指导。
实验结论
本文通过在 Llama-2、MPT、Falcon 和 Pythia 等多种模型家族上进行的大量实验,验证了 StreamingLLM 的有效性。
- 长文本稳定性:StreamingLLM 能够稳定处理长达400万个 Token 的文本,其困惑度保持稳定,与速度缓慢但性能强大的“滑动窗口重计算”基线相当。而传统的密集注意力和窗口注意力方法则在文本变长后性能崩溃。
 图5:StreamingLLM 在处理400万 Token 超长文本时的困惑度表现,覆盖了多种模型家族和规模。困惑度全程保持稳定。
图5:StreamingLLM 在处理400万 Token 超长文本时的困惑度表现,覆盖了多种模型家族和规模。困惑度全程保持稳定。
- 效率优势:与唯一可行的基线(滑动窗口重计算)相比,StreamingLLM 在保持相似内存占用的同时,实现了巨大的速度提升,最高可达 22.2 倍。这是因为它避免了在每个解码步骤中重新计算整个窗口的注意力。
 图10:StreamingLLM 与滑动窗口重计算基线在每 Token 解码延迟和内存使用上的对比。StreamingLLM 实现了高达 22.2 倍的加速。
图10:StreamingLLM 与滑动窗口重计算基线在每 Token 解码延迟和内存使用上的对比。StreamingLLM 实现了高达 22.2 倍的加速。
- 真实世界应用:在流式问答任务(StreamEval)中,StreamingLLM 能够持续正确回答与近期上下文相关的问题,而其他方法则因内存溢出或性能崩溃而失败。
- 注意力池的验证:
- 数量:对于现有模型,保留4个初始 Token 作为注意力池通常就足够了,更多 Token 带来的收益递减(见下表)。
- 专用池 Token:预训练时加入一个可学习的 Sink Token,不仅不会损害模型在标准任务上的性能,还能让流式部署更简单高效(仅需保留这一个 Token)。
表2:不同数量的初始 Token 对 StreamingLLM 性能的影响。通常4个初始 Token 就足以恢复模型性能。
| 缓存配置 | 0+4096 | 1+4095 | 2+4094 | 4+4092 | 8+4088 |
|---|---|---|---|---|---|
| Llama-2-7B PPL | 3359.95 | 11.88 | 10.51 | 9.59 | 9.54 |
- 局限性:实验发现,简单地增加 StreamingLLM 中“最近 Token”的缓存大小,并不总能带来性能提升,有时甚至会导致困惑度略微上升。这表明模型可能没有充分利用其接收到的所有上下文信息。
最终结论:StreamingLLM 是一个简单、高效且无需微调的框架,它首次解决了将现有 LLM 部署于无限长文本流式应用中的难题,为其实际应用(如长时间对话机器人)扫清了关键障碍。