Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
-
ArXiv URL: http://arxiv.org/abs/2510.19338v2
-
作者: Chen Liang; Feng Zhu; Yibo Cao; Peng Jiao; Jingyu Hu; Mingyang Zhang; Yixuan Sun; Yankun Ren; Jun Zhou; Yao Zhao; 等26人
TL;DR
本文提出了一种名为 Ring-linear 的高效混合注意力架构,通过将线性注意力(Linear Attention)与标准的 Softmax 注意力相结合,在显著降低长上下文推理的 I/O 和计算成本的同时,保持了强大的模型性能。
关键定义
- 混合线性注意力架构 (Hybrid Linear Attention Architecture):本文的核心设计,是一种将两种注意力机制结合的模型结构。它并非完全采用线性注意力或 Softmax 注意力,而是在模型中交替使用多个线性注意力层和一个 Softmax 注意力(具体为 GQA)层,从而在效率和模型表达能力之间取得平衡。
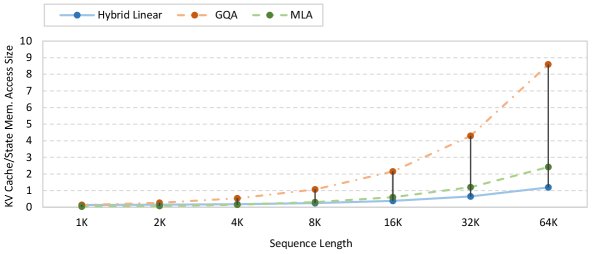
- 线性注意力 (Linear Attention):一种计算复杂度与序列长度成线性关系 ($O(nd^2)$) 的注意力机制。其关键优势在于,推理过程中所需的键值缓存 (KV cache) 大小是恒定的 ($O(d^2)$),与序列长度无关,因此在处理长文本时极为高效。
- 层组 (Layer Group):Ring-linear 模型的基本构建单元。每个层组由 $M$ 个线性注意力模块和一个分组查询注意力(Grouped Query Attention, GQA)模块组成。$M$ 的取值(即线性与 Softmax 注意力的比例)是决定模型效率与性能平衡的关键超参数。
相关工作
近年来,通过增加解码Token数量(Test-Time Scaling)来提升大型语言模型(LLM)能力已成为趋势,这使得模型对长上下文的支持变得至关重要,尤其是在智能体(Agent)系统和代码生成等应用中。然而,传统的注意力机制(如 MHA, GQA)存在一个核心瓶颈:其计算复杂度和 KV 缓存大小随序列长度的增长而迅速增加(计算复杂度为 $O(n^2)$),这给长文本处理带来了巨大的 I/O 和计算压力。
为了解决这一问题,研究界提出了多种线性注意力方法(如 Retnet, Mamba 等),它们将计算复杂度降至线性级别 ($O(nd^2)$),显著提升了效率。然而,这些方法也存在局限性:
- 纯线性注意力模型在工业级的大规模应用中,其性能通常不及标准的 Softmax 注意力模型。
- 线性注意力的效率优势仅在非常长的序列(如 >8K)下才变得明显,但在主流的预训练长度(4K-8K)下,其效率提升有限。
因此,本文旨在解决的核心问题是:如何设计一个既能利用线性注意力的效率,又能保持 Softmax 注意力强大性能的混合架构,并对其进行深度优化,使其在训练和推理上都经济高效。
本文方法
Ring-linear 系列模型的核心在于其创新的混合架构和系统级的计算优化,旨在实现长上下文场景下的高效率与高性能。
基本架构
Ring-linear 的整体架构由 $N$ 个层组堆叠而成。每个层组包含 $M$ 个线性注意力模块和 1 个 GQA(Softmax 注意力的一种变体)模块。这种设计旨在通过 GQA 层保留模型的关键表达能力,同时利用大量的线性注意力层来降低整体计算成本。
此外,该模型集成了高度稀疏的专家混合(Mixture-of-Experts, MoE)架构(激活率仅为 1/32),并采用了包括无辅助损失的路由策略、多Token预测 (MTP)、QK-Norm 和部分旋转位置编码 (Partial-RoPE) 在内的多种先进技术。
目前已开源两个模型:
- Ring-mini-linear-2.0:总参数量 160亿,激活参数量 9.57亿。
- Ring-flash-linear-2.0:总参数量 1040亿,激活参数量 61亿。
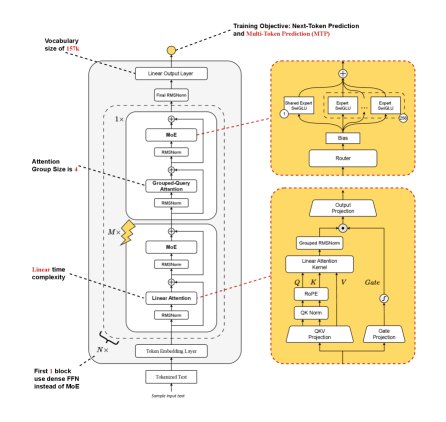
详细的架构参数如下表所示:
| 模型系列 | 总层数 | 头数量 | 头维度 | 中间层尺寸 | 词表大小 | MoE专家数 | 激活专家数 |
|---|---|---|---|---|---|---|---|
| Ring-mini-linear-2.0 | 40 | 32 | 128 | 14336 | 151851 | 32 | 1 |
| Ring-flash-linear-2.0 | 80 | 48 | 128 | 36864 | 151851 | 32 | 1 |
创新点:混合线性注意力
创新本质
本文的本质创新在于找到了线性注意力与 Softmax 注意力之间的最佳“混合比例”,而非简单地替换。纯线性注意力虽然高效,但在某些任务(如检索)上表现不佳。而混合架构不仅保留了效率,其性能甚至在某些方面超越了纯 Softmax 架构。
实现方式
本文采用的线性注意力机制(类似于 Lightning Attention)通过一个递归形式进行计算,其核心优势在于状态矩阵 $\textbf{k}\textbf{v}_{t}$ 的大小是恒定的 ($d \times d$),不随序列长度 $t$ 增长。 第 $t$ 个 token 的输出 $\textbf{o}_{t}$ 可以递归地表示为:
\[\begin{split}\textbf{k}\textbf{v}_{0}&=0\in\mathbb{R}^{d\times d},_\\ \textbf{k}\textbf{v}_{t}&=\lambda\textbf{k}\textbf{v}_{t-1}+\textbf{k}_{t}^{\text{T}}\textbf{v}_{t},_\\ \textbf{o}_{t}&=\textbf{q}_{t}(\textbf{k}\textbf{v}_{t}),_\\ \end{split}\]其中 $\lambda$ 是一个固定的衰减系数。
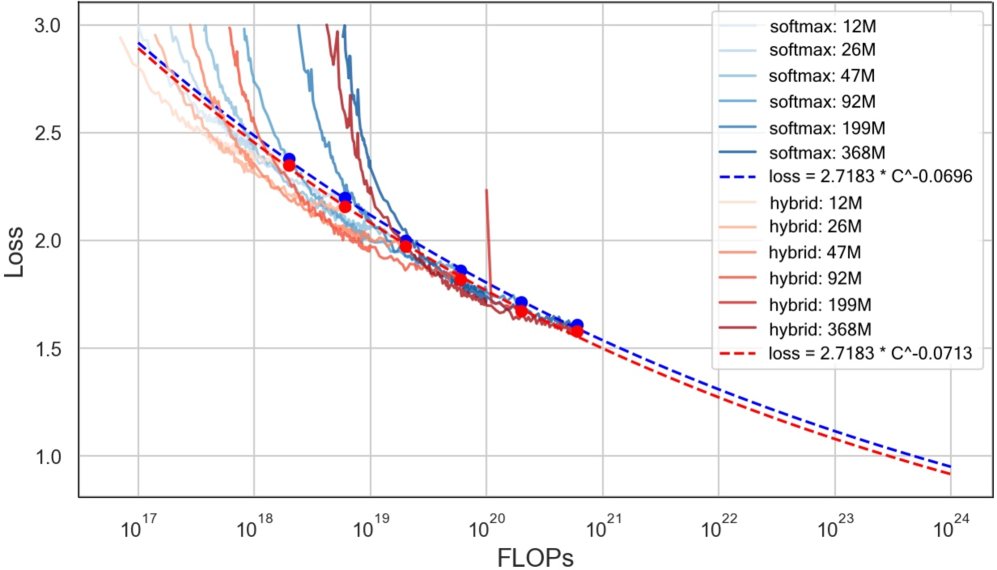
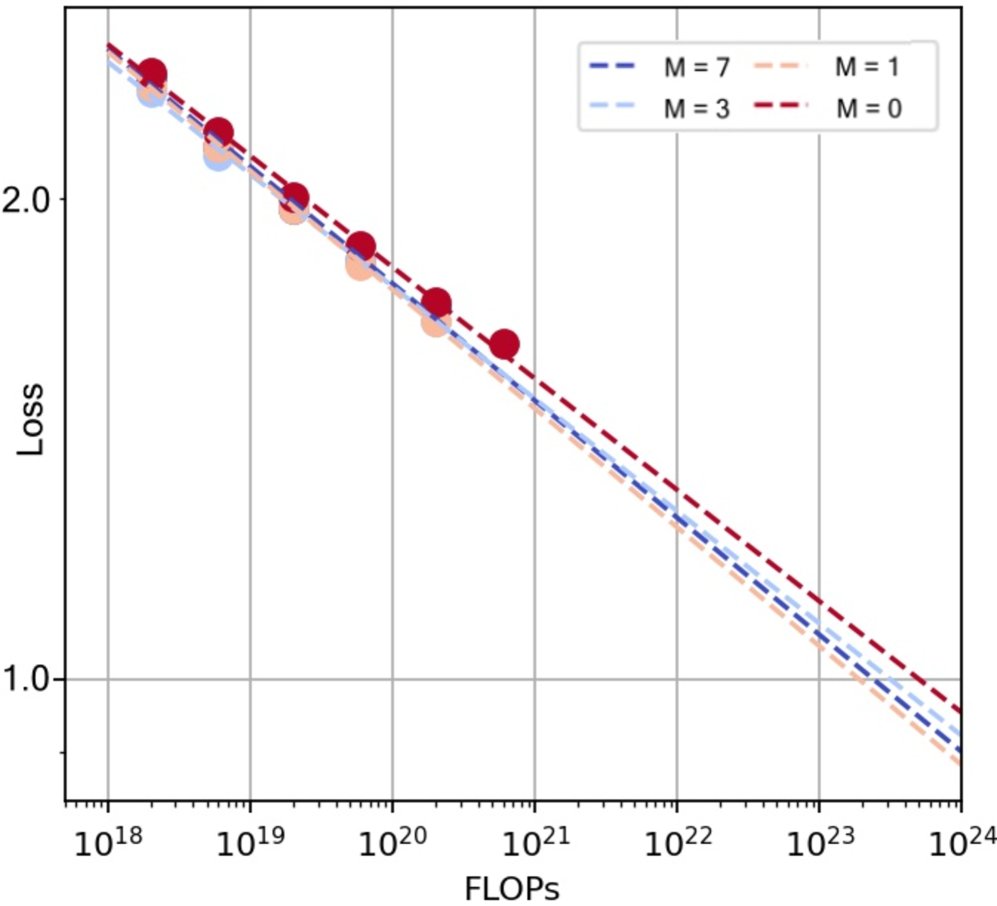
混合比例的确定
通过大规模的 Scaling Law 实验,本文发现混合架构的性能稳定优于纯 Softmax 架构。并且,随着计算预算的增加,采用更大比例线性注意力(即更大的 $M$ 值,如 $M=7$)的配置表现更优。最终,Ring-flash-linear-2.0 采用了 $M=7$(7个线性层+1个GQA层),Ring-mini-linear-2.0 采用了 $M=4$。
优点:关键架构设计与优化
为了最大化性能和效率,本文进行了一系列精细的架构设计和端到端的计算优化。
1. 关键架构设计
- Grouped RMSNorm:在张量并行场景下,为避免层内各GPU间的通信开销,对 RMSNorm 进行分组本地化计算。
- 部分RoPE:仅对 Q 和 K 的一半维度应用 RoPE,实验证明可有效降低训练损失。
- 头级别衰减 (Head-wise Decay):为线性注意力中的不同头设置基于幂律的衰减率,相比线性衰减率,此举显著降低了训练损失并提升了下游任务性能。
2. 计算优化
本文从训练和推理两个方面实施了全面的性能优化,核心在于大量的 GPU 算子(Kernel)融合。
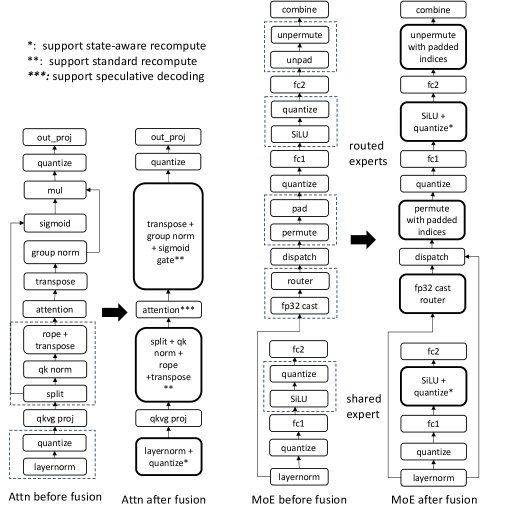
- GPU 算子融合:将多个独立操作(如门控机制、MoE 路由、QK 归一化等)融合成单个算子,大幅减少了 GPU 显存读写和计算延迟,从而提升了训练和推理吞吐量。
- FP8 训练优化:
- 量化融合:将 FP8 的量化操作与前续的激活函数(如 SiLU)等算子融合,避免了中间结果的显存读写,减少了 I/O 瓶颈。
- 细粒度重计算:在梯度重计算时,根据反向传播的需求,精细地控制前向计算的输出(例如,只输出转置后的量化矩阵),避免了冗余计算。
- 推理优化:开发了支持 SGLang 和 vLLM 等主流推理框架的优化线性注意力算子,并首次实现了支持树状注意力掩码(tree mask)的线性注意力算子,为混合架构模型启用推测解码(speculative decoding)提供了可能。
训练策略
模型采用“持续预训练 + 后训练”的策略。
- 持续预训练 (Continued Pre-Training):从性能强大的 dense 模型(Ling-base-2.0)初始化,将部分注意力层转换为线性注意力,然后进行持续训练以恢复并扩展模型能力,包括将上下文窗口从 4K 逐步扩展到 128K。
- 后训练 (Post-Training):包括监督微调(SFT)和强化学习(RL)。特别地,在 RL 阶段,本文发现并解决了训练与推理框架实现不一致(如 RMSNorm, RoPE 的细微差别)导致 RL 训练崩溃的问题,通过系统性对齐实现了长期稳定的 RL 训练。
实验结论
实验结果有力地证明了 Ring-linear 架构在效率和性能上的双重优势。
训练与推理效率
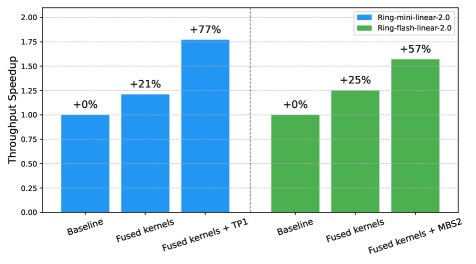
- 训练效率:得益于算子融合和 FP8 优化,与基线相比,Ring-mini-linear-2.0 的训练吞吐量提升了 77%,Ring-flash-linear-2.0 提升了 57%。
- 推理效率:
- Prefill 阶段:当上下文长度超过 8K 时,Ring-linear 模型的吞吐量开始超越其他模型,在 128K 上下文时,其吞吐量是 dense 模型的 8倍以上。
- Decode 阶段:当生成长度超过 4K 时,Ring-linear 模型的优势显现,在 64K 上下文时,吞吐量是 dense 模型的 10倍以上。与同样采用混合架构的 Qwen3-Next 相比,Ring-flash-linear-2.0 表现出更高的效率。
Ring-mini-linear-2.0 vs Baselines 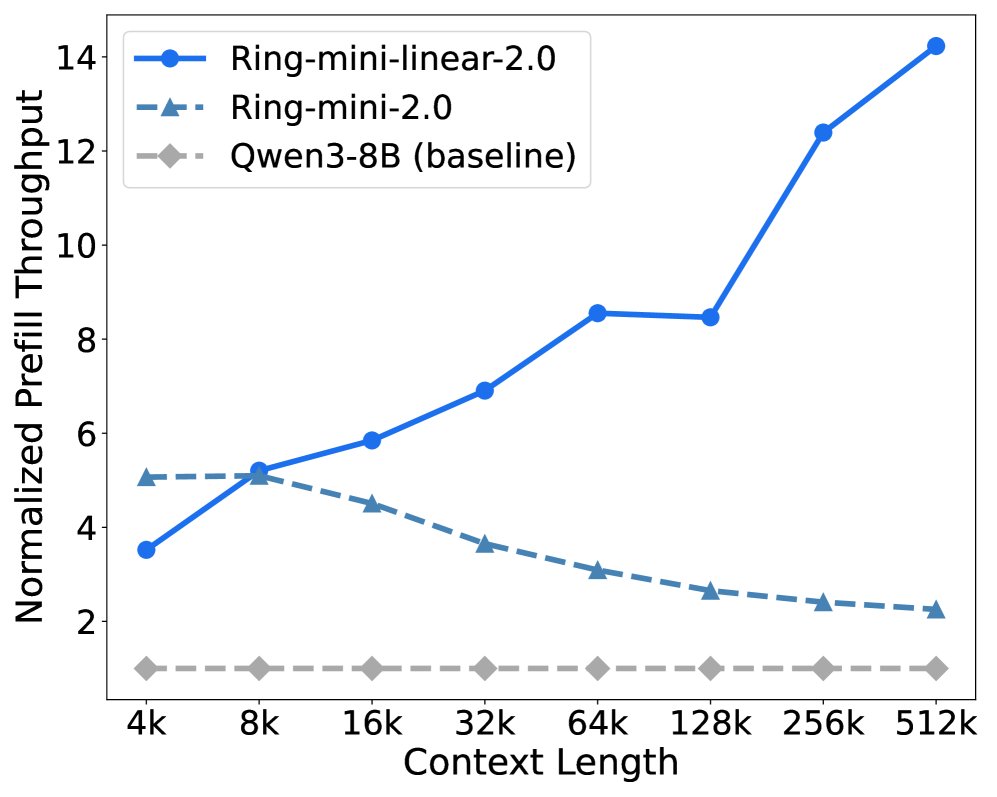
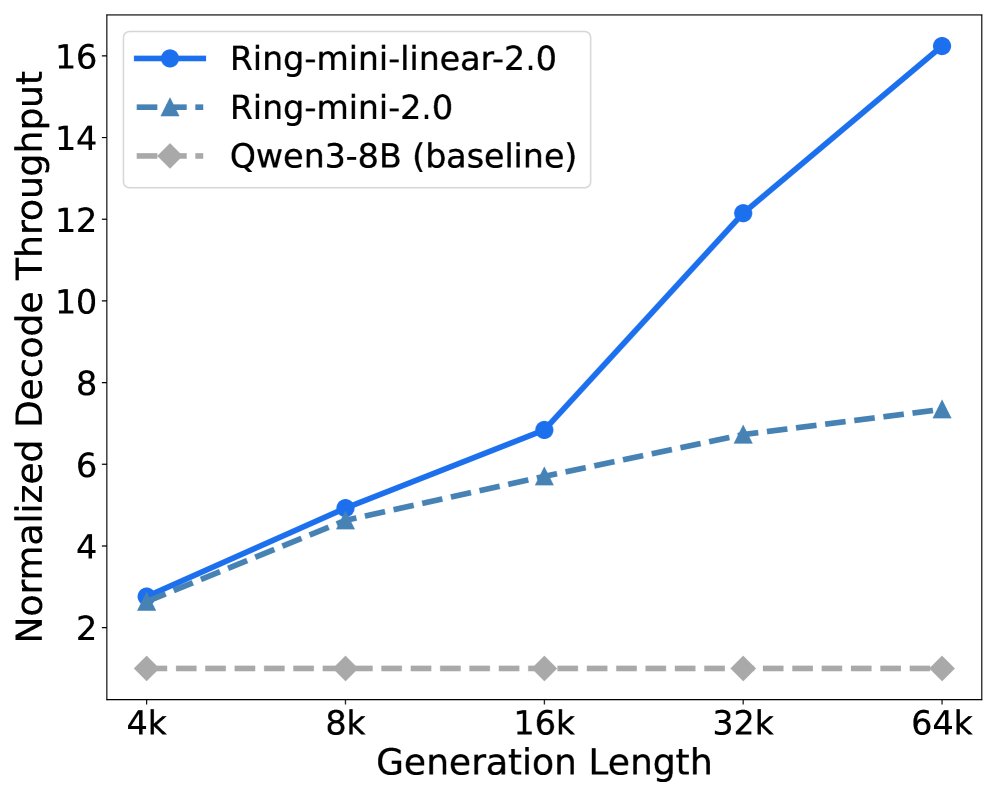
Ring-flash-linear-2.0 vs Baselines 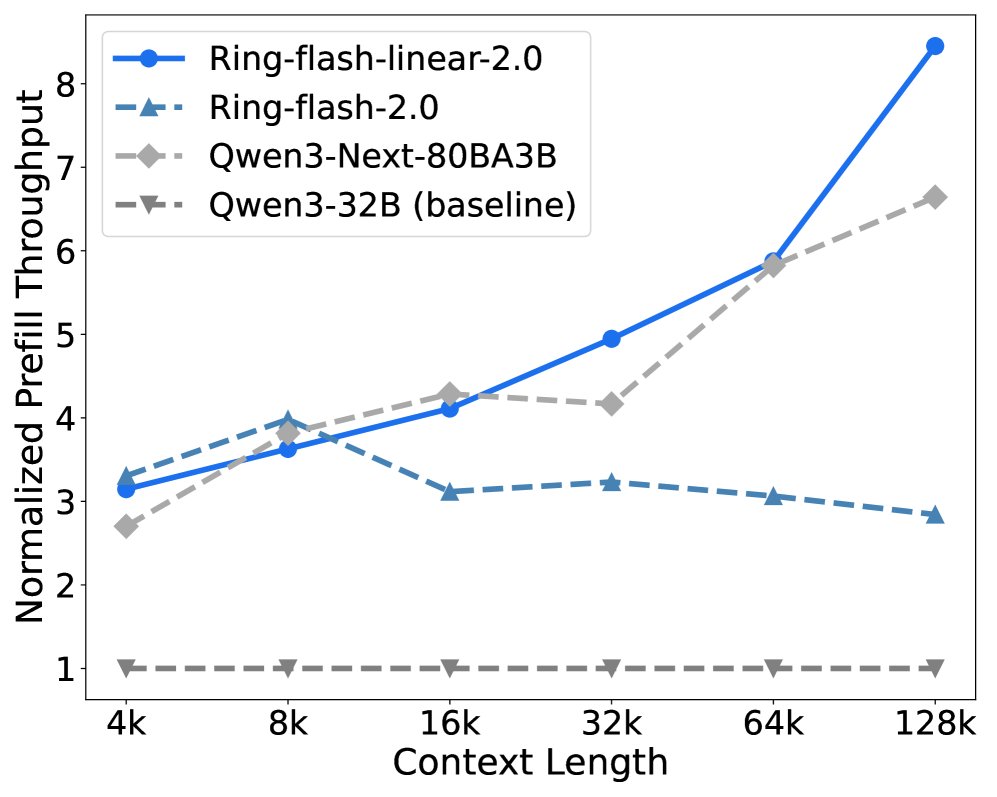
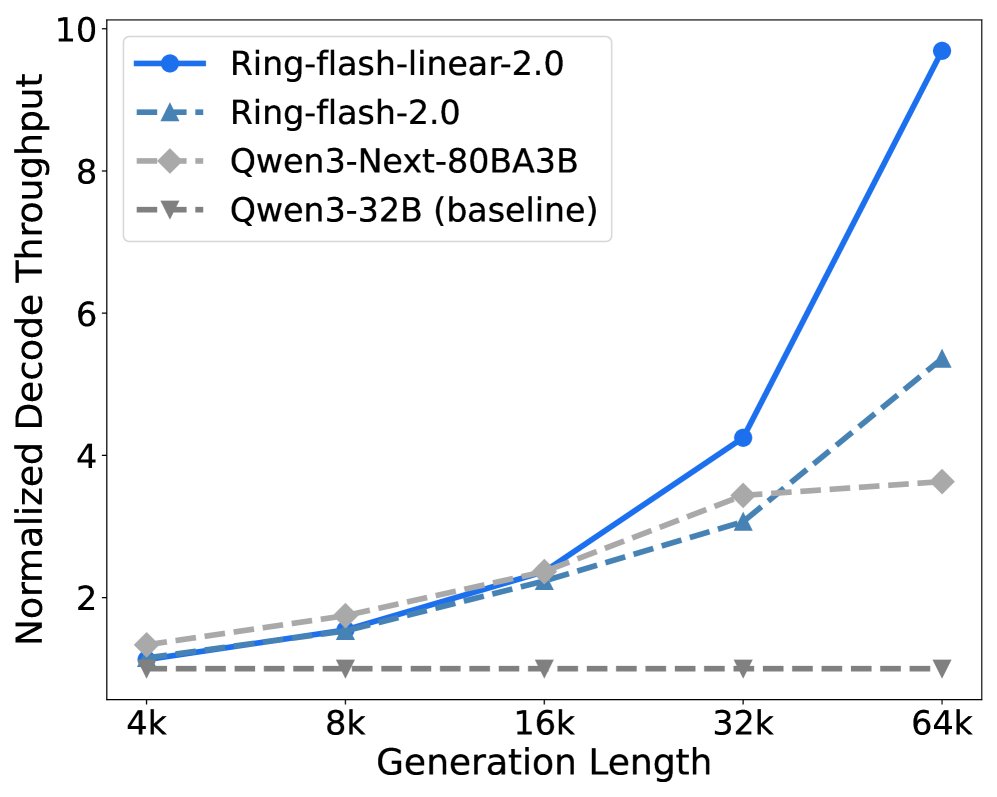
模型性能
- 通过持续预训练,Ring-linear 基础模型在编码、数学、推理、知识和自然语言理解等多个维度上,恢复了原始 dense 模型 98% 以上的性能,仅在推理和专业知识方面有轻微下降,这可能是持续训练中知识遗忘所致。
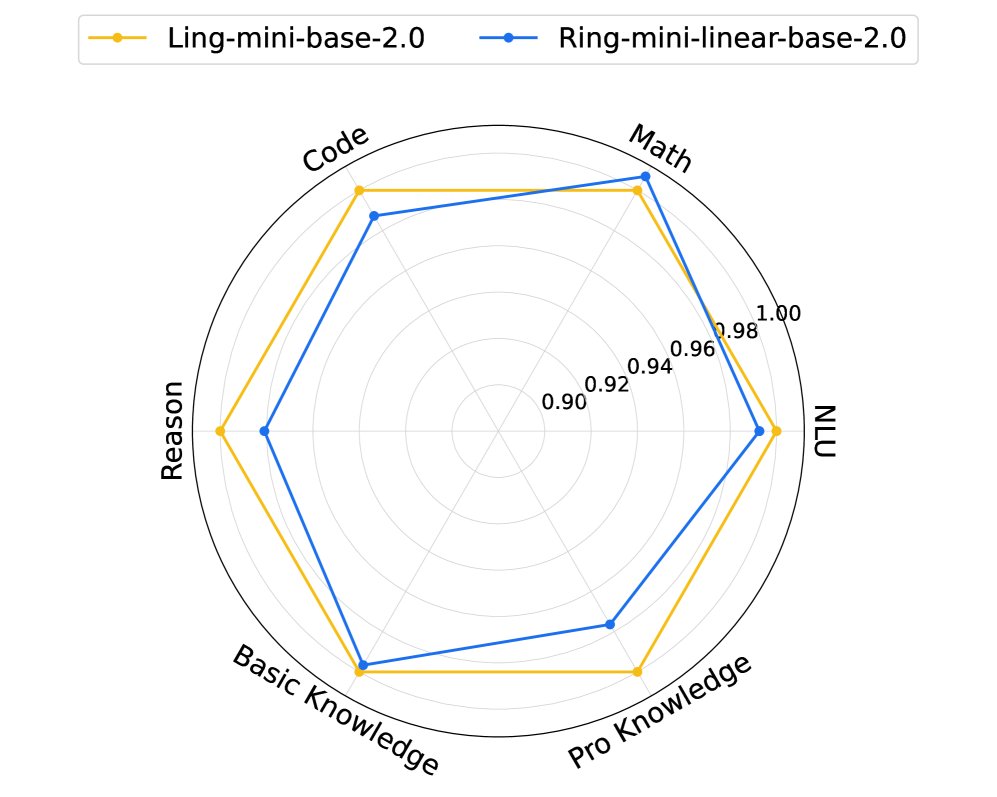
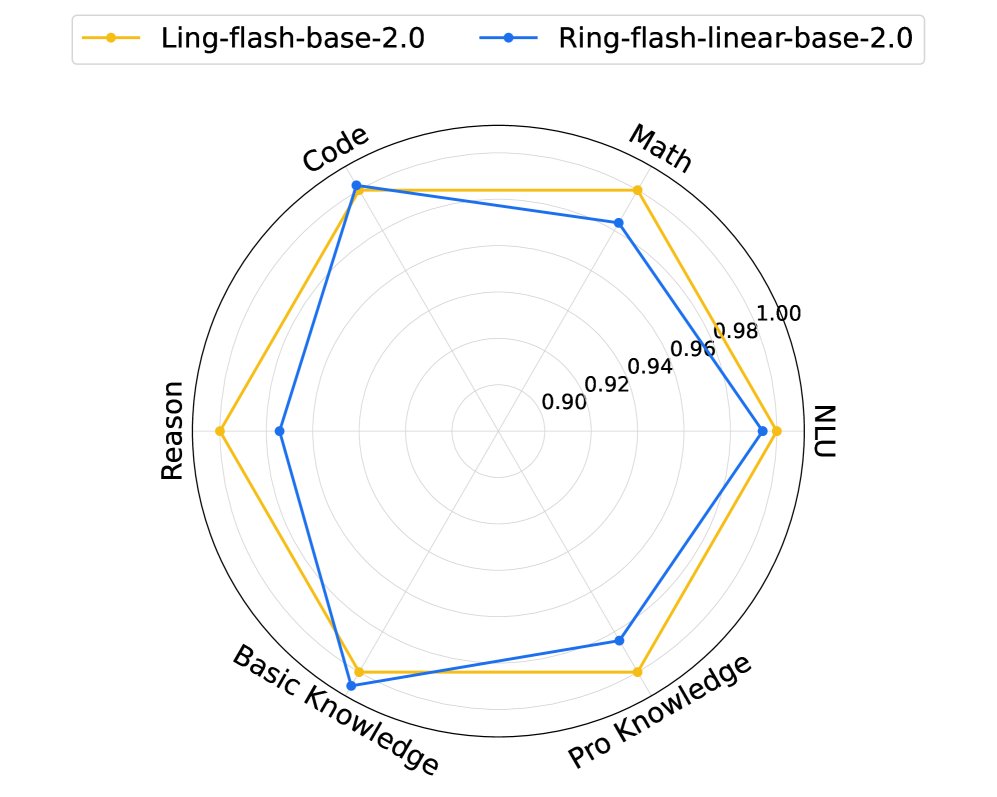
总结
本文成功设计并实现了一个名为 Ring-linear 的混合注意力架构,它巧妙地结合了线性注意力的效率和 Softmax 注意力的性能。通过系统性的架构探索和端到端的计算优化,该模型在长上下文推理场景下展现出数量级的效率提升,推理成本相较于 dense 模型降低至 1/10,同时在各项基准测试中保持了 SOTA 性能。此外,本文在解决 RL 训练稳定性方面的发现也为该领域提供了宝贵的实践经验。