Executable Counterfactuals: Improving LLMs’ Causal Reasoning Through Code
-
ArXiv URL: http://arxiv.org/abs/2510.01539v1
-
作者: Chenhao Tan; Amit Sharma; Hao Peng; Qirun Dai; Aniket Vashishtha; Hongyuan Mei
-
发布机构: Microsoft Research India; TTIC; The University of Chicago; University of Illinois Urbana-Champaign
TL;DR
本文提出了一个名为“可执行反事实 (Executable Counterfactuals)”的框架,通过生成需要溯因、干预和预测三个步骤的编程和数学问题,系统地评估和提升大语言模型的反事实推理能力,并实验证明强化学习(RL)比监督微调(SFT)更能实现这种能力的泛化。
关键定义
- 反事实推理 (Counterfactual Reasoning): 本文遵循 Pearl 的定义,将其视为一个包含三个核心认知技能的过程:
- 溯因 (Abduction):根据已知的行为和观察到的结果,推断系统中存在的潜在、未被观察到的状态或变量。
- 干预 (Intervention):在推断出的潜在状态基础上,对系统中的某个变量进行假设性的修改。
- 预测 (Prediction):根据干预后的新状态,计算并预测其可能产生的结果。
- 干预推理 (Interventional Reasoning): 对应于 Pearl 因果阶梯的第二层。它指在所有变量都已知、没有潜在混杂因素的情况下,改变某个输入并预测结果。本文强调,许多现有基准错误地将这种简化的推理形式等同于更复杂的反事实推理。
- 可执行反事实 (Executable Counterfactuals): 本文提出的核心框架。它利用代码或数学问题作为一种可控、可执行的环境来研究反事实推理。由于代码的输出可以被精确计算,这为评估模型的推理能力和为强化学习提供可验证的奖励信号创造了条件。
- 基于可验证奖励的强化学习 (RL from Verifiable Reward, RLVR): 本文采用的一种训练方法。它不依赖于详细的推理过程标注,而是仅根据最终输出的正确性(即可验证的奖励信号)来优化模型策略。实验证明,该方法在教授可泛化的反事实推理技能方面非常有效。
相关工作
目前,反事实推理被公认为是大型语言模型(LLMs)的一个显著弱点。然而,现有的评估方法存在两大瓶颈:
- 任务过于简化:许多基准虽然在语言上看似是反事实问题,但实际上由于提供了所有信息(即没有潜在变量),任务被简化为干预推理。模型只需改变输入并进行一次新的前向推理即可解决,无需进行“溯因”这一核心步骤。这导致对模型真实能力的高估。
- 任务脱离实际:一些基于合成因果图的基准虽然理论上很严谨,但与现实世界的问题solving场景相去甚远,并且可能需要专门的因果推理知识(如do-calculus),使得难以准确定位模型失败的根源。
针对上述问题,本文旨在创建一个新的评估和训练框架,它能够:
- 明确区分反事实推理与干预推理,强制模型必须执行“溯因-干预-预测”的完整认知过程。
- 提供可扩展、可验证且复杂度可控的测试环境,以便对模型的推理能力进行细粒度分析,并为模型改进提供有效的训练数据。
本文方法
本文的核心思想是利用可执行的代码和数学问题,构建一个需要完整反事实推理链条才能解决的任务环境。
可执行反事实:代码
该框架通过基于模板的方法生成结构多样且逻辑可控的 Python 函数,以此作为反事实问题的载体。
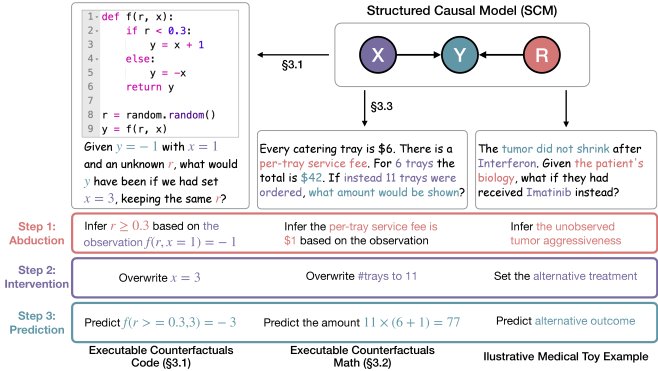
方法本质 一个典型的任务如下:给定一个函数 \(f(r, x)\),其中 \(r\) 是一个模型未知的随机潜在变量。模型会观察到一次运行结果,例如 \(f(r, x=1)\) 的输出是-1。然后,模型被提问:“如果当初 \(x\) 的值是3,结果会是什么?” 要正确回答,模型必须:
- 溯因:根据观察到的输出 \(-1\),反推出潜在变量 \(r\) 的可能取值范围。
- 干预:保持推断出的 \(r\) 不变,将输入 \(x\) 的值修改为 \(3\)。
- 预测:执行 \(f(r_inferred, x=3)\) 并计算出最终结果。
创新点
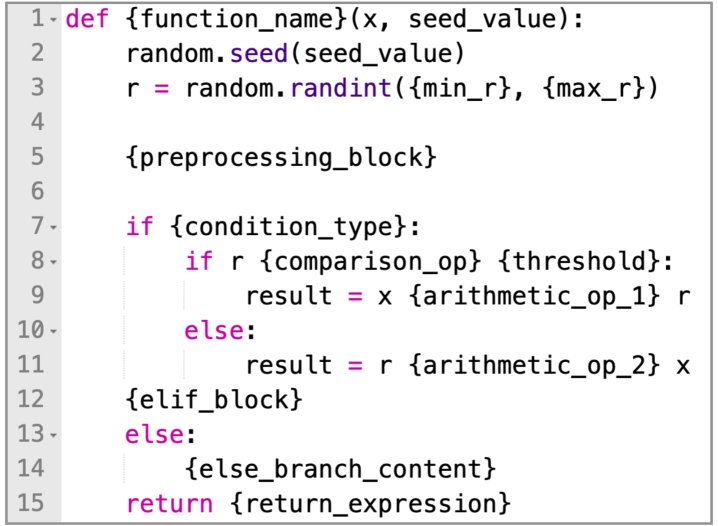
- 模板化生成:通过一个嵌套的模板系统生成代码。该系统包含三层占位符:函数样板、定义程序逻辑的核心代码块(如 \(if-else\))、以及决定具体行为的运算符和数值。这种方法能以少量模板生成大量结构和语义上都存在差异的函数,保证了数据的多样性和评估的全面性。
| 模板中用于生成训练集if-else函数的实例 |
|---|
 |
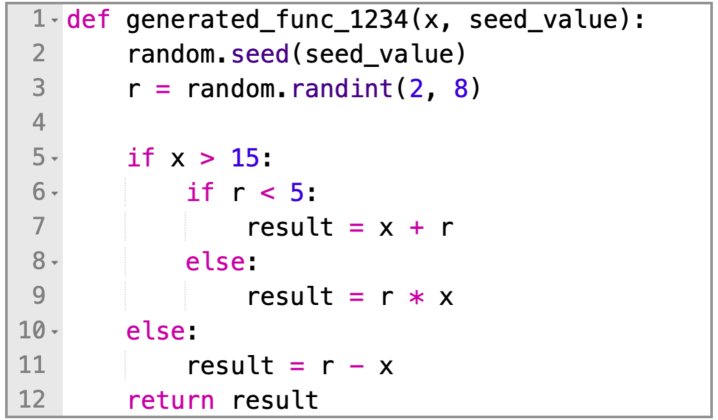
| 从上述模板生成的代码函数 |
|---|
 |
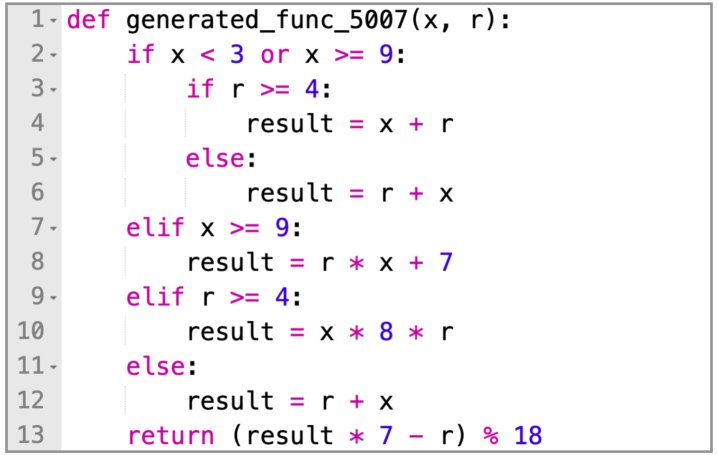
| 从同一模板生成的另一个结构不同的代码函数 |
|---|
 |
- 受控的OOD评估:通过设计训练集中未出现过的代码结构(如 \(while\) 循环、更深的嵌套、多个隐藏变量)来构建分布外(Out-of-Distribution, OOD)测试集,从而严格评估模型的泛化能力。
- 模拟真实世界的不确定性:在函数返回值中引入取模(modulo)运算,使得多个不同的潜在变量 \(r\) 值可以对应同一个观测输出。这迫使模型需要考虑所有可能性,更贴近现实场景。
可执行反事实:数学
为了测试模型能否将从代码中学到的推理技能泛化到自然语言领域,本文还构建了一个反事实数学问题数据集。这些问题类似于 GSM-8K 风格的应用题,但在问题描述中巧妙地隐藏了一个关键变量(如一笔未言明的服务费、每件商品的额外成本等)。模型必须首先根据题目给出的总数等信息,通过溯因推理找出这个隐藏变量的值,然后才能回答关于假设情境的问题。
实验结论
LLM在反事实推理上表现薄弱
实验比较了多种先进LLM在本文框架下的反事实任务与其对应的干预任务上的表现。结果显示,即便是推理能力很强的模型(如 Qwen-32B),在能够轻松解决干预任务(已知隐藏变量)的同时,在反事实任务上的表现却大幅下滑(通常下降超过一半)。这证明了当前LLM的瓶颈确实在于“溯因”这一环节。

基于蒸馏的SFT泛化能力差
使用来自强教师模型(DeepSeek-Distilled-Qwen-32B)的思维链(CoT)对Qwen系列模型进行监督微调(SFT)。
- 在分布内(ID)表现良好:SFT显著提升了模型在与训练数据结构相似的任务上的性能。
- 在分布外(OOD)表现糟糕:当任务的底层逻辑(如出现 \(while\) 循环)或领域(从代码到数学)发生变化时,SFT带来的性能提升迅速消失,甚至出现负面影响。这表明SFT只是“记住”了特定模式,并未学会可泛化的推理技能。
| 在分布内(ID)和分布外(OOD)反事实编码任务上的评估结果。由于每个问题可能包含多个答案,本文报告了F1和精确匹配(EM)得分(单位为百分比)。 |
|---|
RLVR能够引导出可泛化的反事实推理技能
使用基于可验证奖励的强化学习(RLVR)方法,仅利用最终答案是否正确作为奖励信号进行训练。
- 一致且显著的提升:RLVR在所有ID和OOD任务上都取得了显著且一致的性能提升,无论模型规模如何。
- 强大的泛化能力:最重要的是,仅在代码任务上训练的模型,其反事实推理能力成功泛化到了结构完全不同的代码(如\(while\)循环和多隐藏变量)以及自然语言数学问题上。一个7B的RLVR模型在编码任务上的表现甚至超过了32B的基线模型。
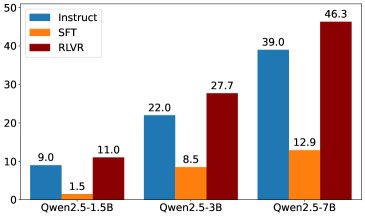
推理轨迹的行为分析
通过LLM-as-a-judge分析模型的推理过程,发现:
- 模型规模的悖论:增大模型规模可以提升计算的准确性(\(Execution\)),但并不能提升遵循“溯因-干预-预测”正确策略的能力(\(Planning\))。大模型倾向于用更复杂的计算绕过标准的溯因步骤。
- SFT vs. RLVR:SFT模型在面对OOD任务时会放弃正确的推理策略,而RLVR模型则能持续稳定地采用正确的策略,即使在全新的任务上也是如此。RLVR的主要错误来源是正确策略下的计算失误,而非策略本身错误。
| 模型生成推理轨迹中的三种典型失败模式示例。 |
|---|
| 失败模式 1:暴力枚举 模型试图暴力列举所有可能的隐藏变量值,而不是通过溯因来缩小范围。 |
| 失败模式 2:随意假设 当问题变得复杂时,模型会放弃推理,直接为隐藏变量假设一个任意值。 |
| 失败模式 3:过度复杂化 模型通过不必要的案例拆分和循环分析使问题复杂化,从而陷入困境。 |

最终结论 本文提出的“可执行反事实”框架成功揭示了当前LLM在反事实推理中的核心短板——溯因能力不足。实验证明,SFT虽然能提升模型在特定模式下的表现,但无法实现泛化;相比之下,RLVR能够引导模型内化通用的反事实推理技能,并成功地将其从代码领域迁移到自然语言领域,为训练更强因果推理智能体提供了一条有前景的路径。