Extracting alignment data in open models
-
ArXiv URL: http://arxiv.org/abs/2510.18554v1
-
作者: Chawin Sitawarin; Christopher A. Choquette-Choo; Xiangming Gu; Ilia Shumailov; Itay Yona; Matthew Jagielski; Federico Barbero; Jamie Hayes
-
发布机构: AI Sequrity Company; Anthropic; Google DeepMind; MentaLeap; National University of Singapore; OpenAI; University of Oxford
TL;DR
本文提出了一种新方法,通过利用聊天模板(chat template)作为前缀诱导模型生成内容,并结合神经嵌入(neural embeddings)来度量语义相似度,从而可以从开放权重的语言模型中高效提取出大量有价值的对齐训练数据。
关键定义
本文提出或沿用了以下几个核心概念:
- 对齐数据 (Alignment Data):一个广义术语,不仅包括用于安全和指令遵循的数据(如监督微调和强化学习数据集),还涵盖了任何用于引导模型行为和增强特定能力(如数学、推理、长上下文理解)的定向数据集合。这类数据通常被视为模型的核心竞争资产。
- 近似语义记忆 (Approximate Semantic Memorisation):本文对传统“记忆”概念的扩展。它不再局限于逐字或近乎逐字的文本匹配,而是指模型复现了训练数据中的模式、模板和语义结构。本文认为,即便文本表面存在差异(如数字不同),但只要语义等价,就应视为一种记忆。
- 神经嵌入分数 (Neural Embedding Score):本文用于衡量近似语义记忆的核心指标。它通过高质量的文本嵌入模型计算两段文本嵌入向量的点积,来衡量它们的语义相似度。本文主张,该分数比传统的字符串匹配算法(如编辑距离)更能捕捉语义等价性。
-
聊天模板 (Chat Template):一种用于格式化对话输入的特定结构,它使用特殊Token(如 $$< user >\(、\)< assistant >$$)来包裹用户、助手或系统的消息。本文攻击方法的关键在于,这些模板通常仅在对齐所发生的后训练(post-training)阶段引入。
相关工作
现有研究已充分证实,大型语言模型会记忆其训练数据的一部分。然而,以往的研究大多关注此现象带来的隐私和法律风险,例如模型泄露个人信息或受版权保护的内容。因此,这些研究主要通过精确或近似的字符串匹配(string matching)来衡量记忆的成功率。
这种依赖字符串匹配的方法存在明显瓶颈:它无法有效评估那些在语义结构上极具价值、但字面内容并非完全相同的生成数据。例如,模型可能生成一个与训练样本结构相同但数字不同的数学题,字符串匹配会判定其相似度很低,但其作为训练数据的价值几乎是等同的。
本文旨在解决一个更微妙但同样重要的问题:模型是否会泄露那些构成其性能优势的“对齐数据”?如果一个模型的竞争优势源于其秘密的训练数据配方,而模型又会记忆并“反刍”这些数据,那么这种竞争优势本身就面临被提取和复制的风险。本文提出一种新方法来衡量和提取这种具有语义价值的对齐数据。
本文方法
本文提出一种简单而有效的对齐数据提取策略,其核心在于利用了聊天模板的特性,并采用神经嵌入来度量相似度。
提取流程
该方法的流程如下图所示,主要包含三个步骤:
- 构建向量数据库:使用一个高质量的嵌入模型(本文使用 \(bge-m3\))对目标模型的整个后训练数据集进行嵌入,构建一个向量搜索引擎。
-
诱导模型生成:利用模型后训练阶段引入的聊天模板特殊Token(例如 $$< user >$$)作为前缀(prefix),重复提示目标模型生成大量样本。 - 相似度匹配与检索:将每个生成的样本进行嵌入,然后在向量数据库中进行搜索,找出语义最相似的原始训练样本及其神经嵌入分数。分数超过预设阈值(本文设为0.95)的样本即被视为成功提取。
创新点
利用聊天模板引导生成
本文的一个关键观察是,聊天模板及其特殊Token仅在后训练阶段被引入。因此,当模型看到这些Token时,会将其与后训练的数据分布关联起来。通过将这些Token作为提示,可以有效引导模型生成与后训练数据集在风格和结构上高度相似的内容。这解释了为何像Magpie(Xu et al., 2024)这样的技术能够生成高质量的合成数据。
| 下表展示了使用完整聊天模板前缀($$< | im_start | >user\n\()比仅使用单个特殊Token(\)< | im_start | >$$)能生成与后训练数据语义更接近的样本,其平均嵌入分数更高。 |
| 前缀 | 平均嵌入分数 | ||
|---|---|---|---|
| $$< | im_start | >$$ | 0.857 |
| $$< | im_start | >user\n$$ | 0.892 |
采用神经嵌入度量相似度
本文最重要的贡献在于论证了神经嵌入是衡量数据提取成功与否的更优指标。传统的字符串匹配方法(如Levenshtein距离)对微小的、不影响语义的文本差异(如数字、措辞)非常敏感,因此会严重低估记忆率。
如下图所示,一个生成样本(左)和一个原始训练样本(右)在语义上几乎完全相同,都是一个关于计算跑步距离的数学应用题。但由于具体的数字和选项不同,其字符串相似度仅为约0.7,而神经嵌入分数则非常高,这更符合人类对于“记忆”的判断。在传统标准下,这个样本不会被计为记忆,但它显然复现了原始数据的模板和价值。
实验表明,与字符串匹配相比,神经嵌入揭示的记忆率要高出至少一个数量级($10\times$)。
实验结论
本文通过对SFT和RL两个场景下的模型进行实验,验证了所提方法的有效性。
SFT数据提取实验 (以OLMo 2为例)
本文以\(OLMo 2\)系列模型为对象,提取其SFT(监督微调)数据。
-
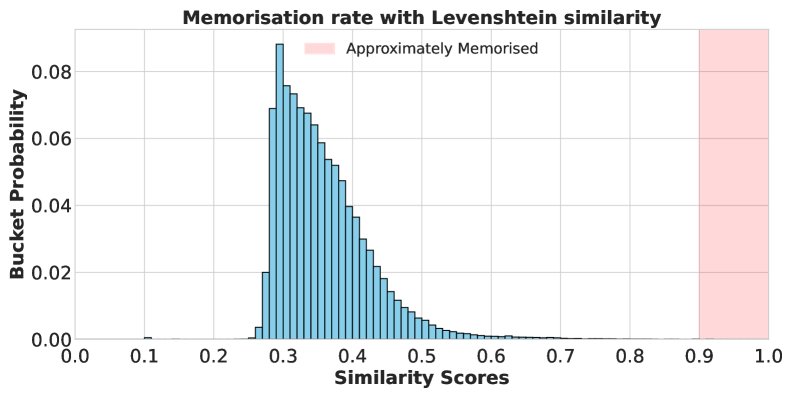
字符串匹配的局限性:下图显示,使用字符串匹配度量(Levenshtein和Indel相似度),在10万个生成样本中,几乎没有样本达到0.9的“近似记忆”阈值。这会导出一个错误的结论,即模型没有发生记忆。
-
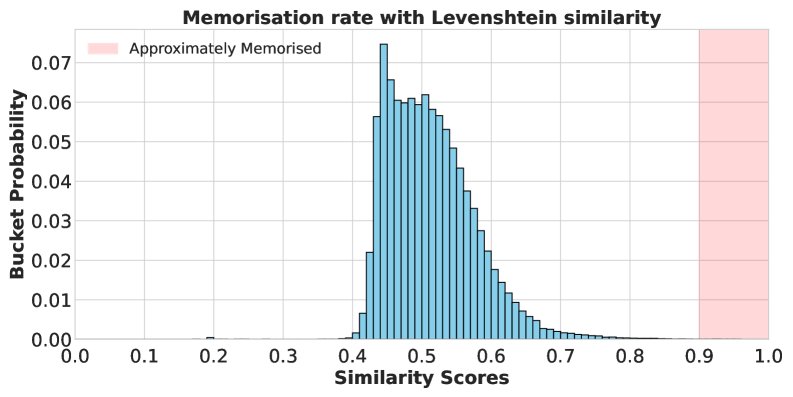
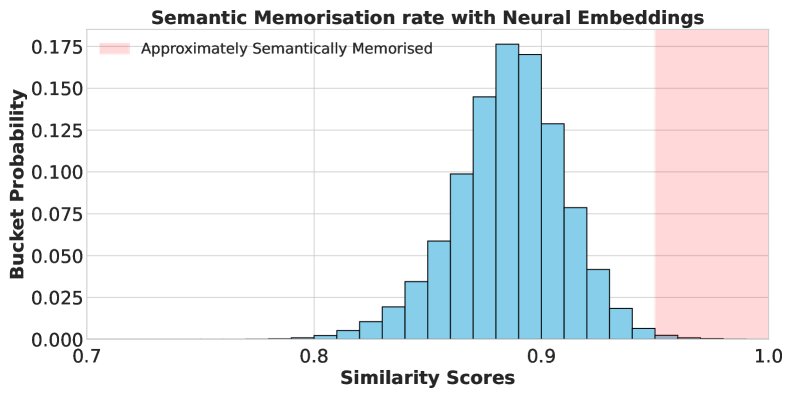
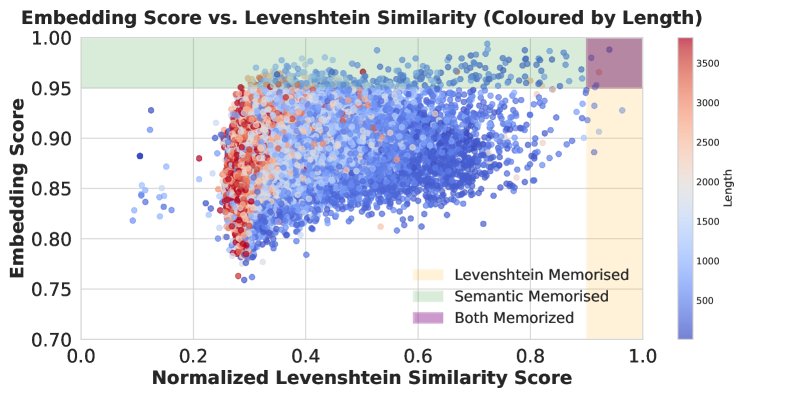
神经嵌入的优越性:相比之下,使用神经嵌入度量时,揭示了显著的记忆率(下图左)。下图右侧的散点图进一步表明,字符串匹配分数与语义相似度关联性很差,并且受到文本长度的严重影响(长文本得分偏低)。
-
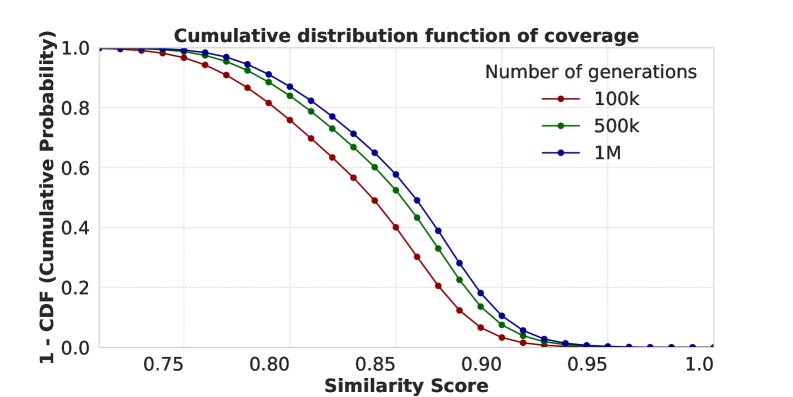
数据覆盖率:通过对100万个生成样本进行分析,发现某些训练样本比其他样本更容易被模型记忆和复现。这可能与这些样本在预训练或中间训练阶段也出现过,或其模式在数据集中频繁重复有关。
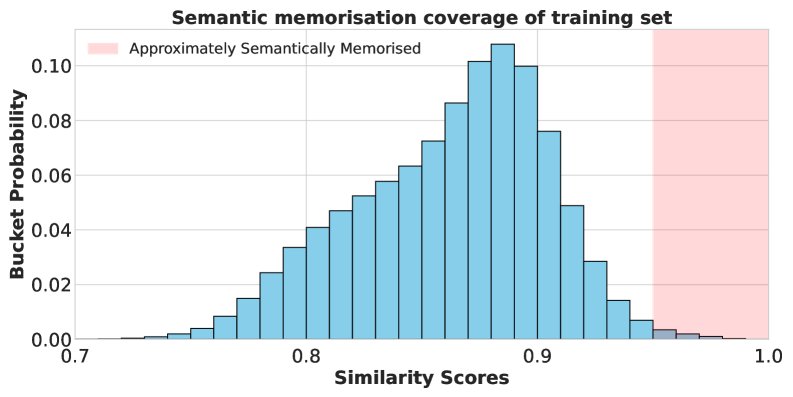
-
直接蒸馏:本文使用从\(OLMo 2 13B\)模型中提取的约93万个合成样本,直接对\(OLMo 2 7B\)的基础模型进行SFT。结果显示,使用合成数据训练的模型在多个基准测试上取得了与使用原始SFT数据集训练的模型相当的性能,证明了提取出的数据具有很高的实用价值。
RL数据提取实验 (以Open-Reasoner-Zero为例)
本文以\(Open-Reasoner-Zero\)模型为对象,提取其RL(强化学习)数据。
-
提取RL数据:令人惊讶的是,本文方法同样能有效提取RL阶段的训练样本(问题和答案),甚至有时是逐字复现。这很反直觉,因为PPO这类RL目标函数并不像SFT那样直接最大化序列似然。下图展示了一个被逐字复现的RL训练样本,模型不仅给出了问题和答案,还生成了思维链。

-
RL诱发记忆:通过比较RL训练前后模型对训练样本的似然变化,发现RL训练显著提升了大量训练样本的出现概率(下图),证实了RL过程确实能诱发记忆。其背后的具体机制尚不明确,是一个有趣的未来研究方向。

-
直接蒸馏:与SFT实验类似,本文从一个7B RL模型中提取了5.7万个合成样本,用其训练\(Qwen2.5 7B\)基础模型。结果(下图)显示,使用合成数据训练的模型在多个数学推理基准上取得了与使用原始RL数据集训练的模型相当的性能。
总结
本文证明了从开放权重的LLM中提取有价值的对齐数据是完全可行的。其核心发现是:
- 方法有效:利用聊天模板作为提示,可以有效诱导模型生成与后训练数据分布相似的内容。
- 度量关键:传统的字符串匹配方法会严重低估数据泄露的真实规模,而神经嵌入能够准确捕捉“近似语义记忆”,是更合适的度量标准。
- 价值巨大:提取出的数据质量很高,可以直接用于训练一个新的基础模型(即模型蒸馏),并使其获得与原始模型相当的部分性能。这揭示了模型蒸馏实际上可能间接等同于在原始数据集上进行训练,对模型资产安全和AI生态产生了深远影响。