FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
-
ArXiv URL: http://arxiv.org/abs/2305.14251v2
-
作者: Kalpesh Krishna; Wen-tau Yih; M. Lewis; Xinxi Lyu; Mohit Iyyer; Luke Zettlemoyer; Hannaneh Hajishirzi; Pang Wei Koh; Sewon Min
-
发布机构: Allen Institute for AI; Meta AI; University of Massachusetts Amherst; University of Washington
TL;DR
本文提出了一种名为 FActScore 的新评估指标,通过将长文本分解为一系列原子事实并计算由可靠知识源支持的事实比例,来精细化地衡量语言模型生成内容的事实准确性,同时还开发了一个自动化模型来低成本、大规模地估算此分数。
关键定义
本文提出了以下核心概念:
-
原子事实 (Atomic Fact):指一个传达单一信息的简短陈述。它是比句子更基本的评估单位,能够对生成内容进行更细粒度的分析,避免了对混合了正确与错误信息的句子进行模糊的二元判断。
-
FActScore: 一个用于评估语言模型事实准确性的分数。它被定义为模型生成的文本中,能被给定知识源 $\mathcal{C}$ 支持的原子事实所占的百分比。对于一个给定的生成文本 $y$,其原子事实集合为 $\mathcal{A}_y$,FActScore 的计算公式为:
\[f(y) = \frac{1}{ \mid \mathcal{A}_y \mid } \sum_{a \in \mathcal{A}_y} \mathbb{I}[a \text{ 被 } \mathcal{C} \text{ 支持}]\]整个模型 $\mathcal{M}$ 的 FActScore 是对所有输入提示 $x$ 的期望值:
\[\text{FActScore}(\mathcal{M}) = \mathbb{E}_{x \in \mathcal{X}}[f(\mathcal{M}_x) \mid \mathcal{M}_x \text{ 未拒答}]\]其中 $\mathbb{I}$ 是指示函数。这个定义将事实性与特定的、可验证的知识源绑定,而不是一个抽象的“全局真理”。
相关工作
当前,评估大型语言模型(LMs)生成的长文本的事实性面临两大瓶颈:
- 粒度问题:生成的内容通常混合了真实和虚假信息,甚至在单一句子内也是如此。传统的二元(真/假)判断过于粗糙,无法准确反映内容的整体质量。
- 成本问题:对每一条信息进行人工核查非常耗时且成本高昂,这限制了大规模、快速评估的可行性。
虽然已有研究关注对话、短答案问答或引用准确性,但缺少一种针对长文本生成的、细粒度的、可扩展的评估方法。
本文旨在解决这一问题,即如何对语言模型生成的长文本进行精确、可量化且可扩展的事实性评估。
本文方法
FActScore 评估框架
FActScore 的核心是基于两个关键思想:
- 以原子事实为单位:将复杂的长文本分解为最基本的信息单元(原子事实),并对每个单元进行独立判断。这允许进行更精细的评估,能够识别并量化部分正确的内容。
- 基于知识源的验证:事实的“真假”是相对于一个给定的、可信的知识源(如维基百科)而言的。一个原子事实是否被认为是“事实”,取决于它是否能在该知识源中找到支持性证据。
 图1:FActScore 概述,它计算由给定知识源支持的原子事实的比例。
图1:FActScore 概述,它计算由给定知识源支持的原子事实的比例。
在本文中,评估框架的具体实施流程如下,以生成人物传记为例,并以维基百科作为知识源:
- 数据收集:向待评估模型(LM$_{\textsc{subj}}$)输入提示(如“告诉我关于<人物>的传记”),获取其生成的长文本。人物>
- 原子事实分解:由人类标注者将生成的文本分解为一系列原子事实。为提高效率,会先用 InstructGPT 初步分解,再由人来修正。
- 事实标注:另一组标注者根据英文维基百科,为每个原子事实标注为以下三类之一:Supported (被支持的)、Not-supported (不被支持的) 或 Irrelevant (不相关的)。
最终,一个模型的 FActScore 是其所有生成文本中“被支持”事实的平均比例。
自动化 FActScore 估算模型
由于人工评估成本高昂(约4美元/篇),本文提出了一个自动化模型来估算 FActScore,以实现大规模评测。该模型同样分为两步:
- 事实分解:使用 InstructGPT 将生成文本自动分解为原子事实。
-
事实验证:使用一个评估模型(LM$_{\textsc{eval}}$)结合检索来自动判断每个原子事实是否被知识源支持。本文探索了以下几种验证方法:
- No-context LM:直接向 LM$_{\textsc{eval}}$ 提问 \(<原子事实> True or False?\),不提供任何上下文。
- Retrieve→LM:首先从知识源(维基百科)中检索与原子事实最相关的段落,然后将“检索到的段落 + 原子事实 + True or False?”作为提示输入 LM$_{\textsc{eval}}$。
- Nonparametric Probability (NP):使用一个非参数化的掩码语言模型来计算原子事实中每个 token 的似然概率,通过阈值判断其真实性。
- Retrieve→LM + NP: 一种集成方法,只有当 Retrieve→LM 和 NP 两种方法都判定为“Supported”时,最终结果才为“Supported”。
创新点
- 细粒度评估:通过将文本分解为原子事实,FActScore 能够量化部分正确性,提供比传统二元判断更精确、更有信息量的分数。
- 可扩展的自动化:开发的自动化估算器结合了信息检索和强大的语言模型,其评估结果与人类评估高度一致(错误率低于2%),使得对大量模型进行低成本、大规模的事实性评测成为可能。
- 务实的事实性定义:将事实性定义为“可被特定知识源所支持”,而非追求一个普适的、难以验证的“绝对真理”,使评估标准更加明确和可操作。
实验结论
人工评估发现
通过对 InstructGPT、ChatGPT 和集成了搜索的 PerplexityAI 进行人工评估,得到了以下发现:
| 模型 | 使用搜索 | 响应率 (%) | 每篇Token数 | 每篇事实数 | FActScore |
|---|---|---|---|---|---|
| InstGPT | ✗ | 99.5 | 110.6 | 26.3 | 42.5 |
| ChatGPT | ✗ | 85.8 | 154.5 | 34.7 | 58.3 |
| PPLAI | ✓ | 90.7 | 151.0 | 40.8 | 71.5 |
表1:人工评估的数据统计与 FActScore 结果。
- SOTA模型仍存在大量事实错误:即便是先进的商业模型,其事实准确性也远非完美。ChatGPT 的 FActScore 仅为 58.3%,而集成了搜索引擎的 PerplexityAI 也只有 71.5%。
- 错误率与实体稀有度和事实位置相关:
- 对于更稀有(在预训练语料中出现频率更低)的人物,所有模型的事实准确性都显著下降。
- 在同一篇生成文本中,越靠后的事实错误率越高,这可能源于信息重要性递减和错误传播。
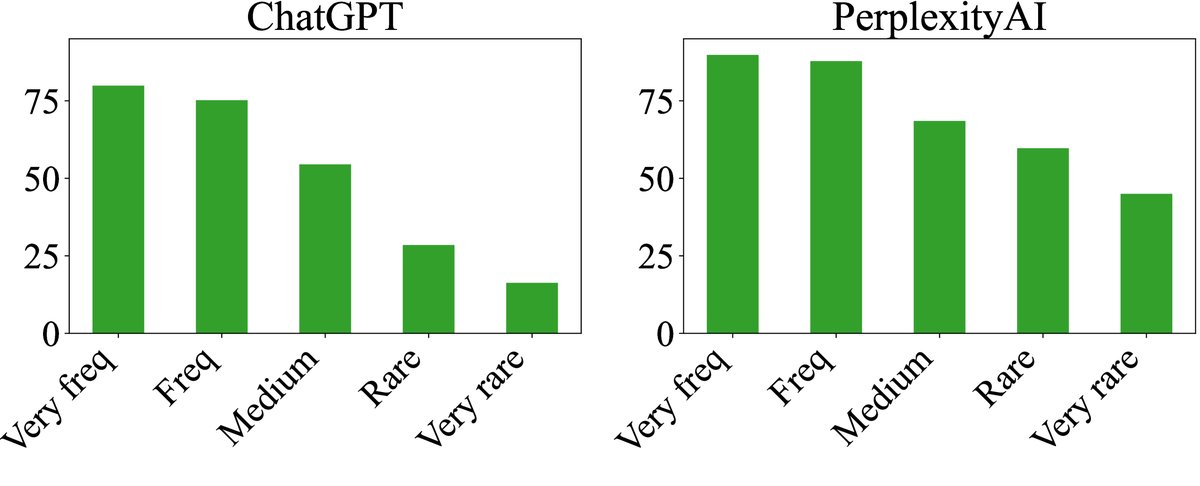
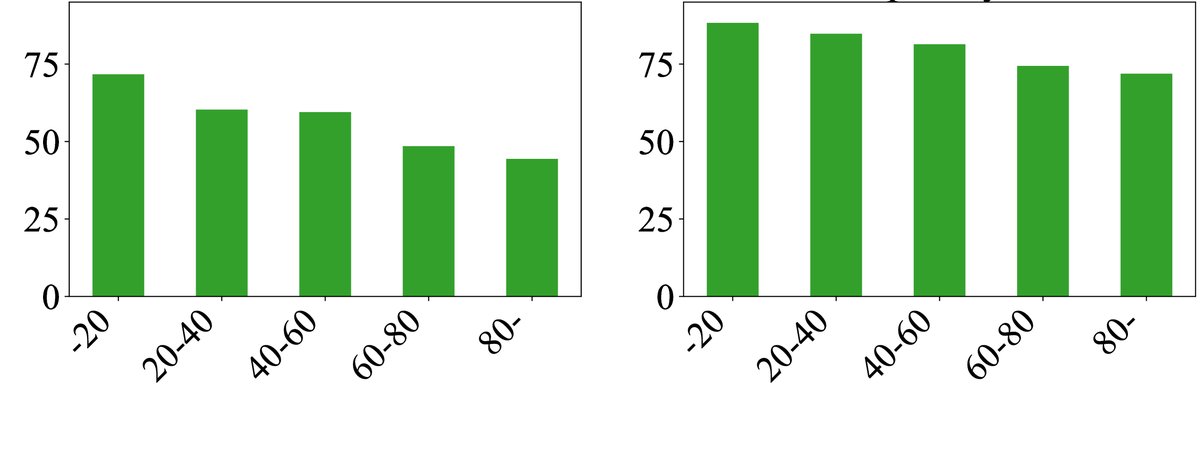 图2:FActScore 随实体稀有度(上)和事实在文本中相对位置(下)的变化。
图2:FActScore 随实体稀有度(上)和事实在文本中相对位置(下)的变化。
- 错误类型分析:对 PerplexityAI 的错误进行分类发现,错误原因多样,包括与维基百科单句或整页内容的矛盾、生成主观性陈述、引用不相关信息,甚至维基百科本身也存在不一致之处。
| 错误类别 | 比例 (%) | 示例 |
|---|---|---|
| 单句矛盾 (词语) | 33.3 | 生成:Glover Teixeira 于 2023年11月25日成为美国公民。 维基:Teixeira 于 2020年11月成为美国公民。 |
| 单句矛盾 (非词语) | 10.0 | 生成:她出演了多部成功电影,如…和 Zero (2018)。 维基:电影 Zero 是 商业失败 的。 |
| 页面级矛盾 | 23.3 | 生成:[Julia Faye] 的著名电影包括… “Cleopatra” (1934)。 评论:在 Julia Faye 的页面上未提及 Cleopatra,反之亦然。 |
| 主观性 | 16.7 | 生成:他作为演员和文化力量的成就,必将证明与他所扮演角色的英雄气概一样。 维基:这是《卫报》文化作家 Steve Rose 的评论,模型直接复制了引文。 |
表2:PerplexityAI 的部分错误类型分析。
自动化评估器性能
| 评估器类型 | 评估 InstructGPT (误差率) | 评估 ChatGPT (误差率) | 评估 PPLAI (误差率) | 排名一致性 |
|---|---|---|---|---|
| Human (Ground Truth) | 42.5 (基准) | 58.3 (基准) | 71.5 (基准) | ✓ |
| Retrieve→LM (NP) | 1.4 | 0.4 | 9.9 | ✓ |
| Retrieve→LM (ChatGPT) | 5.1 | 6.8 | 0.8 | ✓ |
表3:自动化评估器的误差率(ER, 与人类评估分数的差异)和排名一致性。
- 检索至关重要:集成了检索的评估器(Retrieve→LM)性能远超无上下文的评估器。
- 自动化评估器高度准确:最佳的自动化评估器(如使用 Inst-LLAMA+NP 或 ChatGPT 作为验证器)能够非常准确地估算出 FActScore,与人工评估的误差率很低,并且能够正确地对不同模型的表现进行排序。
大规模模型评测
利用自动化估算器,本文对12个当时新发布的LM和人类撰写的传记进行了大规模评测,总计评估了6500份生成文本。
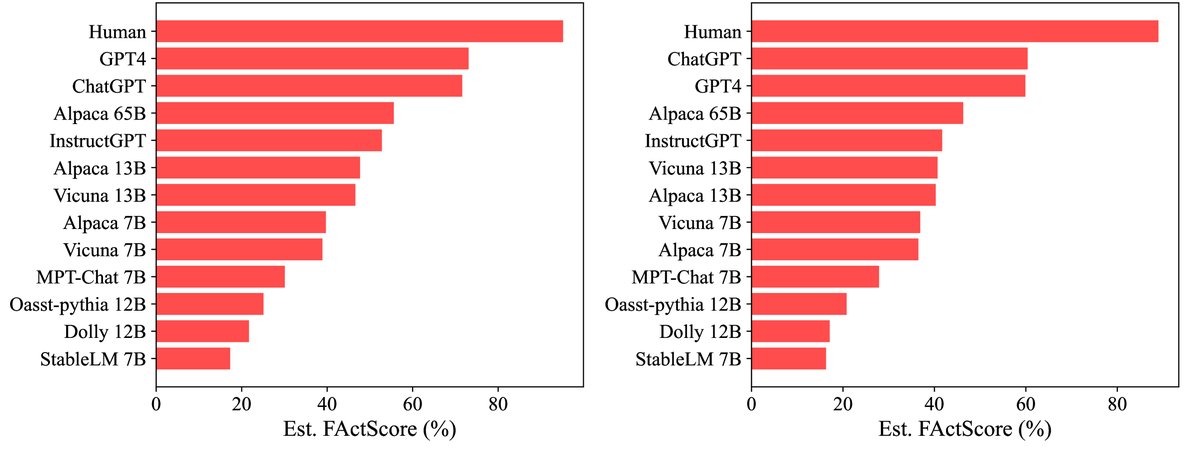 图3:由两种最佳自动化评估器得出的13个主体的 FActScore 排名。
图3:由两种最佳自动化评估器得出的13个主体的 FActScore 排名。
- 所有LM均远逊于人类:在撰写传记这项相对简单的任务上,所有被测LM的事实准确性都显著低于人类撰写的文本。
- GPT-4 和 ChatGPT 领先于开源模型:这两款模型在事实性上表现最佳。GPT-4 在与 ChatGPT 事实性相当的同时,生成了更多的信息且拒答率更低。
- 模型规模效应:在同一模型家族中,规模越大的模型(如 Alpaca 65B > 13B > 7B)通常事实准确性更高。
- 开源模型差距巨大:即使模型大小相近,不同开源模型之间的事实性也存在巨大差异,例如 Vicuna/Alpaca (约40%) 远优于 MPT-Chat (30%) 和 StableLM (17%)。
最终结论
FActScore 提出了一种急需的、细粒度的评估方法,用于量化长文本生成的事实准确性。其配套的自动化估算器既准确又高效,为大规模的模型基准测试提供了可能,并揭示了当前语言模型在事实性方面存在的普遍且显著的局限性。