FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
-
ArXiv URL: http://arxiv.org/abs/2510.22543v1
-
作者: Xin Liu; Min Zhang; Haibin Lin; Juntao Li; Chi Zhang; Yuyang Ding
-
发布机构: ByteDance; Soochow University
TL;DR
本文提出了一种名为缺陷感知策略优化 (FAPO) 的方法,通过训练一个生成式奖励模型(GenRM)来识别并惩罚那些最终答案正确但推理过程有误的“缺陷正样本”,从而在不增加Token预算的情况下,提升大型语言模型在强化学习训练中的推理可靠性、效率和稳定性。
关键定义
- 强化学习与可验证奖励 (Reinforcement Learning with Verifiable Rewards, RLVR): 一种增强大型语言模型(LLM)推理能力的方法范式。在该范式中,模型在具有可验证答案(如数学题)的任务上进行训练,通常使用基于最终答案是否正确的二元奖励信号来优化策略。
- 缺陷正样本 (Flawed-Positive Rollouts): 本文核心概念,指模型生成的一个推理轨迹,其最终答案是正确的,但推理过程中包含逻辑错误,例如答案猜测 (answer-guessing) 或跳跃式推理 (jump-in-reasoning)。
- 缺陷感知策略优化 (Flawed-Aware Policy Optimization, FAPO): 本文提出的核心算法。它是一种策略优化方法,能识别出“缺陷正样本”,并对其施加一个无需参数调整的奖励惩罚,从而引导模型在训练早期利用它们快速进步,在后期则转向更可靠的推理模式。
- 生成式奖励模型 (Generative Reward Model, GenRM): 本文为实现FAPO而设计的一个关键组件。它是一个通过强化学习训练的生成模型,能够对推理过程进行细粒度的评估,不仅能判断是否存在缺陷,还能精确定位错误所在的步骤。
相关工作
当前,利用可验证奖励的强化学习(RLVR)是提升LLM推理能力的前沿方法。这类方法通常在模型探索得到正确答案的推理路径时给予正向奖励。然而,这一范式存在一个核心瓶颈:它无法区分“完全正确的推理”和“通过错误步骤侥幸得到正确答案的推理”(即“缺陷正样本”)。
由于传统的基于结果的奖励机制对这两种情况给予相同的正向奖励,导致模型会学习并内化这些不可靠、不严谨的推理模式,如猜测答案或逻辑跳跃。这不仅限制了模型推理能力的上限,也损害了其可靠性。
本文旨在解决以下具体问题:
- 如何准确、高效地检测出强化学习过程中的“缺陷正样本”?
- 如何设计一种策略优化机制,使其能智能地处理这些“缺陷正样本”? 即在训练早期将其作为有用的“垫脚石”以加速学习,而在后期则抑制它们,推动模型掌握真正可靠的推理能力。
本文方法
本文基于对“缺陷正样本”在强化学习中双重作用(早期有益,后期有害)的洞察,提出了缺陷感知策略优化(FAPO)算法。该算法包含两个核心部分:一是通过训练一个高效的生成式奖励模型(GenRM)来准确检测缺陷正样本;二是在策略优化中对这些样本施加自适应的奖励惩罚。
缺陷正样本检测:训练GenRM
直接使用强大的LLM(如Qwen3-32B)在线检测缺陷正样本计算成本过高。因此,本文提出训练一个更小巧高效的生成式奖励模型(GenRM)。
-
创新点:引入阶梯式RL奖励 为了训练GenRM,本文设计了一个结合结果和过程的复合奖励函数。对于一个待评估的推理过程,GenRM的目标是判断其是否为“缺陷正样本”并定位第一个错误步骤。其奖励函数定义为:
\[R_{\text{FAPO-GenRM}} = R_{\text{Outcome}} + R_{\text{Process}}\]其中,$R_{\text{Outcome}}$ 是基于判断正确与否的二元结果奖励(猜对为+1,猜错为-1)。$R_{\text{Process}}$ 是一个过程奖励,定义为:
\[R_{\text{Process}} = - \frac{ \mid \hat{t}_{\theta} - t^* \mid }{n}\]这里 \($\hat{t}\_{\theta}\)$ 和 \($t^\*\)$ 分别是预测和真实的错误步骤索引,$n$ 是总步数。这个设计具有两大优点:
- 距离敏感的惩罚:$R_{\text{Process}}$ 鼓励模型精确定位错误,预测的位置离真实错误越远,惩罚越重。这有效避免了模型仅靠“猜测”标签(是/否有缺陷)来获取奖励,从而学习到真正的错误识别能力。
- 自然学习进程:在训练初期,模型主要通过提升判断准确率来获得最大的奖励提升(从-1到+1);当判断准确率饱和后,优化重点自然转移到更精细的过程奖励上,实现了从“判别”到“定位”的平滑过渡,无需额外超参数控制。
缺陷正样本惩罚:自适应优化
在利用GenRM检测到缺陷正样本后,FAPO通过一个新颖的奖励机制来调整其在策略优化中的作用。该机制与组相对策略优化(GRPO)相结合。GRPO通过比较一组$G$个rollout的奖励来估计优势函数:
\[\hat{A}_{i,t}=\frac{r_{i}-\text{mean}(\{R_{i}\}_{i=1}^{G})}{\text{std}(\{R_{i}\}_{i=1}^{G})}\]-
创新点:自适应奖励惩罚 FAPO对奖励函数进行了修正:
\[R_{\text{FAPO}}(o,a^* \mid \theta) = R_{\text{RLVR}}(o,a^*) + R_{\Delta}(o,a^* \mid \theta)\]其中,$R_{\text{RLVR}}$ 是标准的+1/-1结果奖励。惩罚项 $R_{\Delta}$ 仅对被GenRM识别为缺陷正样本(FP)的rollout生效:
\[R_{\Delta}(o,a^* \mid \theta) = - \lambda \cdot \mathbf{1}_{\text{FP}}(o \mid \theta)\]$\mathbf{1}_{\text{FP}}$ 是一个指示函数,当rollout $o$ 是缺陷正样本时为1,否则为0。本文默认设置惩罚强度 $\lambda=1$。
-
优点:实现自适应学习轨迹 这个看似简单的惩罚机制,在GRPO框架下产生了动态的优化效果:
- 训练初期(热身阶段):当模型能力较弱,生成的大多是错误答案(奖励为-1)时,一个缺陷正样本的奖励为 \(1-λ=0\)。这虽然低于完美答案(奖励为1),但远高于错误答案。因此,它的相对优势为正,模型会积极学习这些“不完美但正确”的路径,实现快速启动。
- 训练后期(精炼阶段):当模型能力增强,能产生大量完美答案(奖励为1)时,缺陷正样本(奖励为0)的相对优势就会下降,甚至可能变为负值(相比于组内大量的完美答案)。此时,优化目标自动转向生成更可靠的、完全正确的推理路径,从而提升推理质量。
这一机制使得FAPO能够根据模型当前的学习阶段,自动调整对缺陷正样本的利用和抑制,形成一个从“求对”到“求精”的自然演进过程。
实验结论
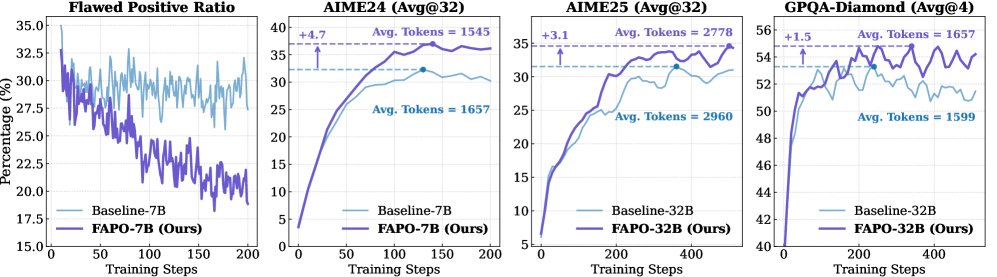
实验在数学推理(AIME24, AIME25)和通用领域推理(GPQA-Diamond)等多个基准上验证了FAPO的有效性。
主要结果
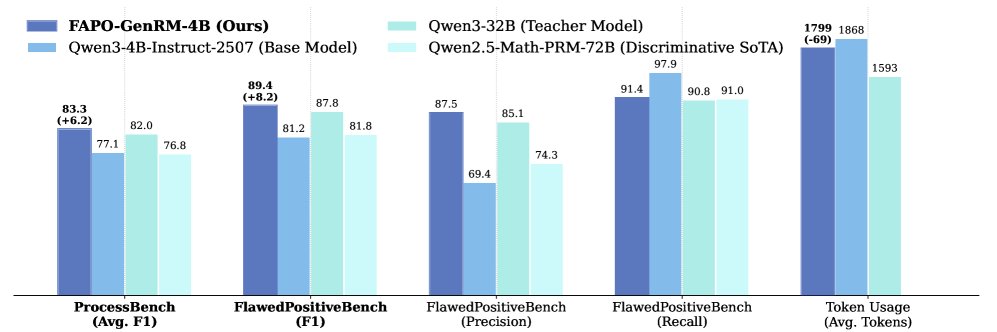
- GenRM性能:本文训练的 \(FAPO-GenRM-4B\) 模型在缺陷正样本检测任务上表现出色。在新建的 \(FlawedPositiveBench\) 和公开的 \(ProcessBench\) 数据集上,其性能不仅远超同尺寸模型,甚至超越了作为其“教师”的、尺寸大得多的 \(Qwen3-32B\) 模型,证明了阶梯式RL奖励设计的有效性。
- 推理性能:
- 正确性提升:集成了FAPO的推理模型在所有测试基准上都显著优于基线(标准RLVR)方法。
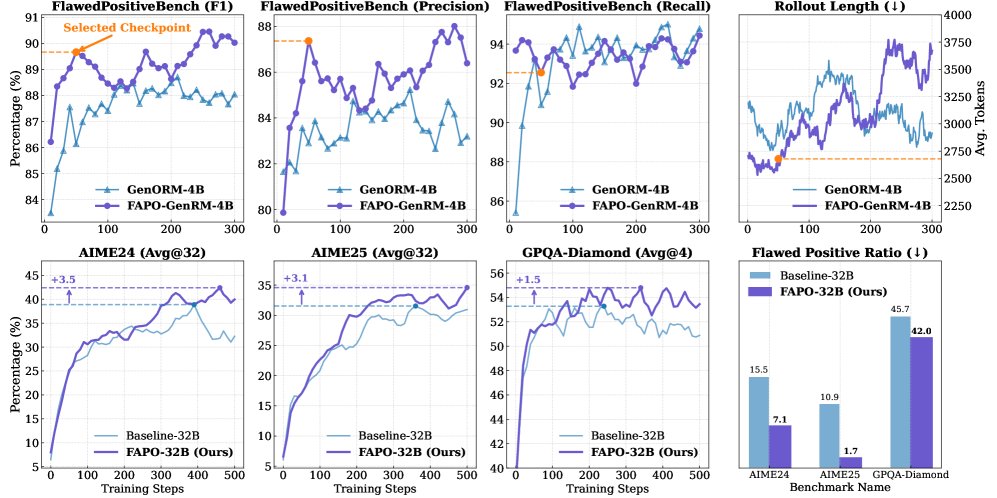
- 可靠性增强:FAPO生成的答案中,缺陷正样本的比例大幅降低。这表明模型学会了更可靠的推理方式,而不仅仅是输出正确答案。
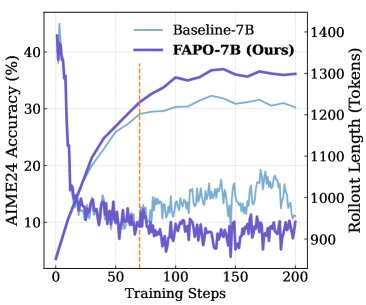
- 稳定性提高:与基线方法相比,FAPO的训练过程更平滑,后期未出现明显的性能衰退现象,显示出更好的训练稳定性。
- 效率不变:所有性能提升都是在不增加生成Token预算(即响应长度)的前提下实现的。
消融研究
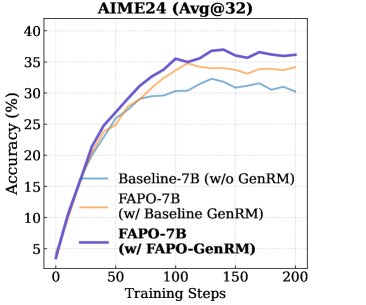
- GenRM的有效性:实验证明,使用性能更强的GenRM(FAPO-GenRM)进行缺陷检测,能直接转化为最终推理任务上更好的性能,凸显了精确检测的关键作用。
- 对自纠正能力的影响:在训练初期,FAPO和基线模型都依赖于较长的、包含自纠正的推理链条。但随着训练进行,FAPO逐渐转向生成更短、更直接的完全正确推理路径,而基线模型则不然。这验证了FAPO能够先利用“自纠正”这类复杂的缺陷正样本进行学习,之后再转向更高效、可靠的推理模式。
总结
FAPO通过一种创新的、对缺陷正样本进行感知和自适应惩罚的机制,成功地解决了传统RLVR方法会强化不可靠推理模式的问题。实验证明,该方法能在不牺牲效率的前提下,系统性地提升LLM在推理任务上的结果正确性、过程可靠性和训练稳定性,为构建更高效、更可信的AI推理系统提供了有效途径。