First Try Matters: Revisiting the Role of Reflection in Reasoning Models
-
ArXiv URL: http://arxiv.org/abs/2510.08308v1
-
作者: Zhanfeng Mo; Yao Xiao; Yue Deng; Wee Sun Lee; Lidong Bing; Liwei Kang
-
发布机构: MiroMind AI; National University of Singapore; Singapore University of Technology and Design
TL;DR
本文通过大规模量化分析揭示,当前推理模型中的“反思”步骤主要起确认作用而非纠错,其性能提升源于首次尝试正确率的提高,并基于此发现提出了一种可大幅提升推理效率的提前终止策略。
关键定义
本文的核心分析建立在对“反思”行为的重新定义和量化之上,沿用并明确了以下关键概念:
- 反思 (Reflection): 在一个推理过程(rollout)中,模型在生成第一个候选答案之后,继续进行的后续所有推理步骤。这一定义将推理过程清晰地划分为“前向推理”(至第一个候选答案)和“反思性推理”(第一个候选答案之后)。
- 确认性反思 (Confirmatory Reflection): 当模型在反思过程中,后续生成的候选答案与之前的答案保持一致或正确性不变时(例如,从正确到正确 T→T,或从同一个错误到同一个错误 F→F (same)),这种反思被视为确认性的。
- 纠正性反思 (Corrective Reflection): 当模型在反思过程中,成功地将一个错误的候选答案修正为正确的答案时(即 F→T 的转变),这种反思被视为纠正性的。
相关工作
当前的先进大型语言模型(LLM),尤其是通过可验证奖励的强化学习(RLVR)训练的推理模型,展现出强大的推理能力。这通常被归因于它们能生成更长的思维链(Chain-of-Thought, CoT)并进行所谓的“反思性推理”——即在得出初步答案后,继续审视、评估和修正自己的推理路径。学界普遍认为,这种反思是模型实现自我纠错、提升最终答案准确率的关键机制。
然而,对于反思的真实作用,现有研究结论不一且缺乏定论。一些研究认为反思机制很复杂且能防止推理崩溃,另一些则认为反思模式通常很肤浅,对结果没有改善。这些研究的关键瓶颈在于缺少对推理模型反思行为的大规模、系统性的量化分析。
本文旨在解决这一核心问题:推理模型中的反思步骤究竟是在进行有效的自我纠错,还是仅仅在确认已有的结论?
本文方法
本文首先设计了一套分析框架来量化反思行为,然后通过受控实验探究反思在训练中的作用,最后基于分析结论提出一种提升推理效率的方法。
反思行为的量化分析
为了系统性地研究反思,本文设计了一种创新的分析方法。
- 方法核心:
- 候选答案提取: 本文提出一个基于LLM的候选答案提取器(LLM-based candidate answer extractor)。该提取器负责解析模型生成的长篇CoT文本,并识别出所有包含候选答案的位置。

- 反思类型划分: 根据提取出的候选答案序列 ${a_1, a_2, …, a_n}$ 及其正确性(True/False),分析相邻两个候选答案之间的转变类型。例如,从错误到正确(F→T)被定义为“纠正性反思”,而从正确到正确(T→T)或从同一错误到同一错误(F→F (same))则被定义为“确认性反思”。
- 候选答案提取: 本文提出一个基于LLM的候选答案提取器(LLM-based candidate answer extractor)。该提取器负责解析模型生成的长篇CoT文本,并识别出所有包含候选答案的位置。
- 创新点:
- 操作化定义与量化: 首次为“反思”提供了一个清晰、可操作的定义(第一个候选答案后的内容),并开发了自动化工具进行大规模量化分析,从而将模糊的“反思”概念转化为可度量的数据。
- 解耦推理阶段: 该方法成功地将推理过程分解为“前向推理”(生成首个答案)和“反思性推理”,使得研究者可以独立评估不同阶段对最终性能的贡献。
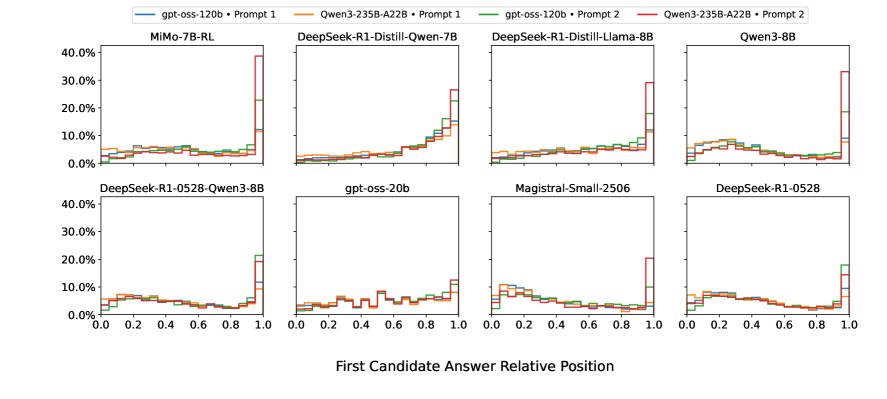
反思在训练中的作用探究
基于上述分析框架,本文通过一系列监督微调(SFT)实验,探究了训练数据中的反思特性如何影响模型性能。
- 方法核心:
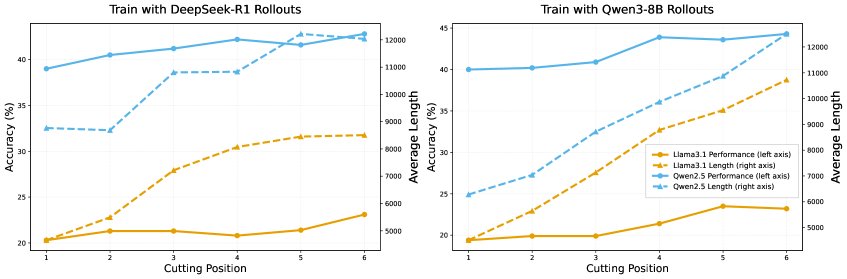
- 控制反思数量: 通过对原始推理数据进行截断和续写,精心构建了多组训练集。这些数据集中的每个样本包含的“反思”数量是受控的(例如,“cut-at-1”数据集中的样本都在第一个候选答案后截断,“cut-at-6”则在第六个后截断),同时保持总训练tokens数量大致相等。
- 控制反思类型: 构建了另一系列训练集,其中包含不同比例的“纠正性反思”(F→T)和“确认性反思”(T→T)的样本。
- 创新点:
- 受控实验设计: 通过精巧的数据集构建策略,本文得以在受控环境中分离并研究反思的“量”(多少)和“质”(是否纠错)对模型学习的影响,这是以往研究未能做到的。
高效推理的提前终止策略
基于“反思主要是确认性的”这一核心发现,本文提出了一种在推理时提升效率的实用方法。
- 方法核心: 提出一种问题感知的自适应提前终止 (Question-aware Adaptive Early-Stopping) 策略。
- 候选答案检测器 (Candidate Answer Detector, CAD): 训练一个小型模型,在推理生成过程中实时监测每一句话是否包含候选答案。
- 问题感知反思控制器 (Question-aware Reflection Controller, QRC): 训练另一个小型分类器,它仅根据问题本身,预测该问题是否可能从更多的反思中受益(即,其原始推理路径中是否包含F→T的纠错过程)。
- 推理流程: 对于一个新问题,首先由QRC判断其“反思价值”。如果价值低,推理过程将在CAD检测到第一个候选答案后立即终止;如果价值高,则允许进行更多轮次的反思(例如,在第三个候选答案后终止),从而动态平衡准确率与token消耗。
- 创新点:
- 分析驱动的优化: 该方法是直接将前文的分析结论转化为实际应用的典范。它没有盲目地削减所有反思,而是通过QRC实现自适应,为可能需要纠错的难题保留了反思预算。
- 优点: 该策略显著减少了不必要的推理token消耗,同时通过自适应控制,最大限度地降低了对模型性能的负面影响,实现了成本与效益的灵活权衡。
实验结论
反思行为分析
- 反思以确认为主,纠错极少: 对8个主流推理模型在5个数学数据集上的分析显示,超过90%的反思是“确认性”的。真正实现纠错(F→T)的反思占比极低,通常小于2%。这表明模型一旦产生一个答案,后续步骤很少会推翻它。
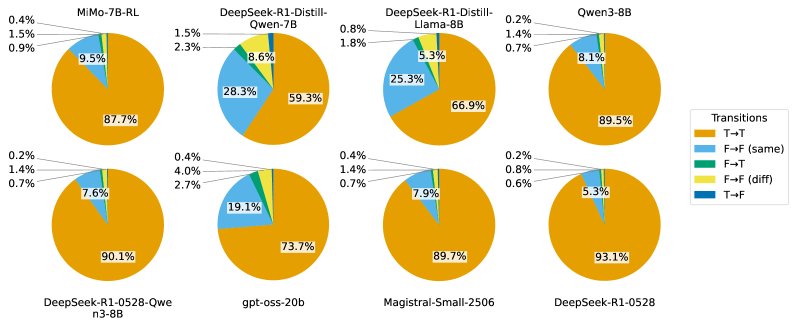
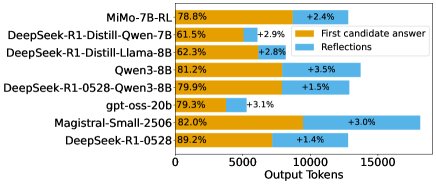
- 性能增益主要源于首次尝试: 尽管反思部分消耗了大量tokens(占总量的16.8%至47.8%),但其带来的准确率提升却非常有限(仅1.4%至3.5%)。最终准确率与第一个候选答案的正确率高度相关,说明“第一次就做对”是性能的关键驱动力。
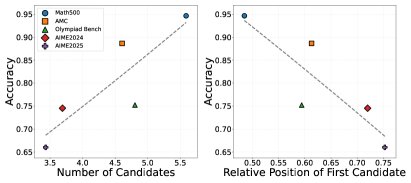
- 反思行为与任务难度错配: 一个反直觉的发现是,在更难的数据集(如AIME)上,模型倾向于花费更多tokens进行前向推理,导致第一个候选答案出现得更晚(反思更少);而在更简单的数据集(如Math500)上,模型反而更早地给出答案并进行更多的反思。这表明当前模型的反思机制并未与任务难度有效对齐。
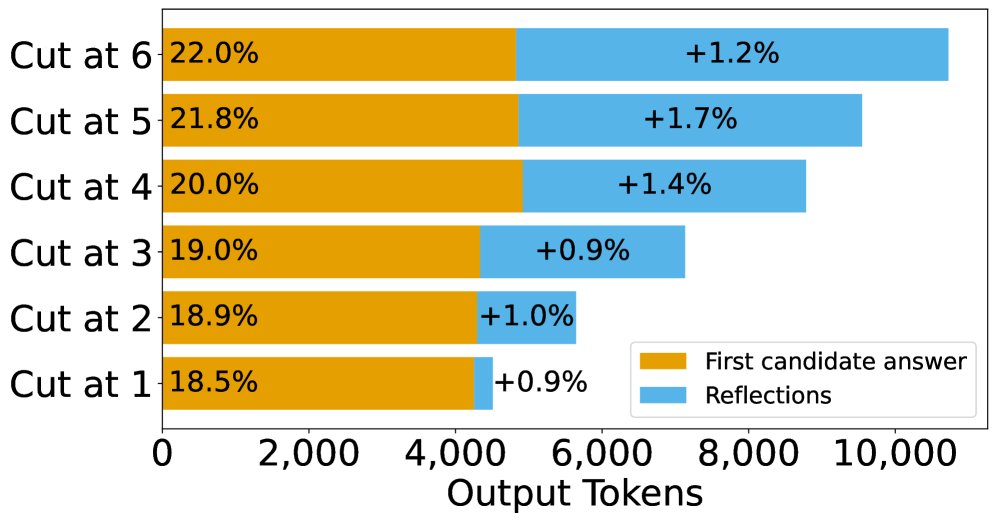
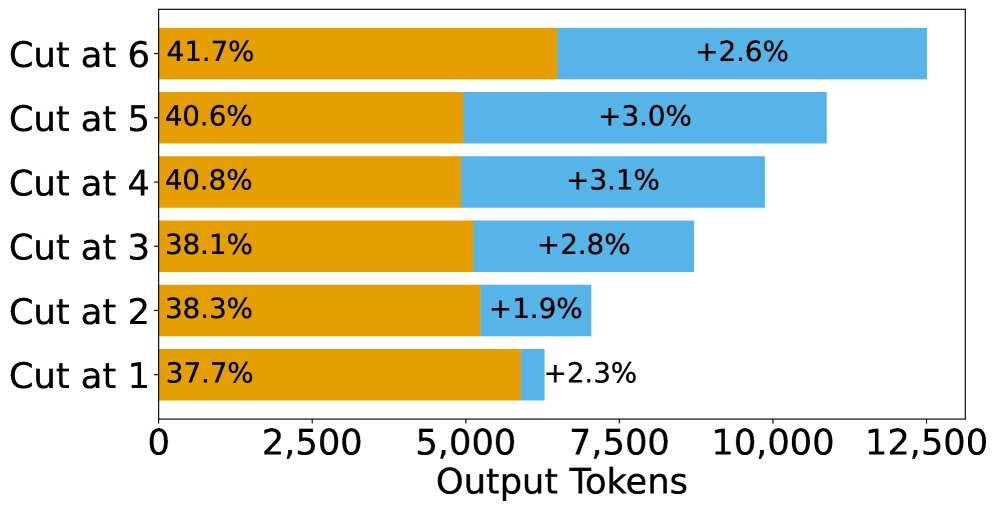
训练实验结论
- 多反思训练能提升性能,但机制是强化首次尝试: 实验表明,使用包含更多反思步骤的数据进行SFT训练,确实能提升模型的最终准确率。然而,剖析性能增益的来源发现,这种提升主要来自“首次尝试正确率”的显著提高(平均提升3.75%),而反思阶段的纠错能力几乎没有变化(仅提升0.3%)。
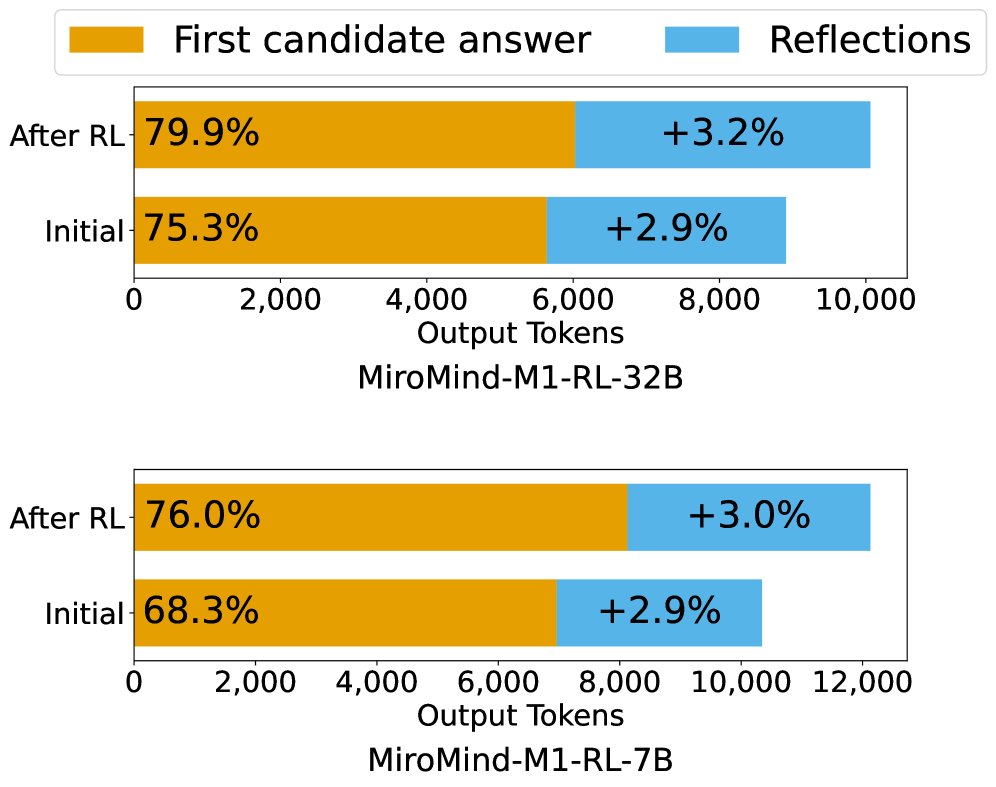
- RL训练遵循同样模式: 对比RL训练前后的模型,发现性能增益同样主要来自首次尝试正确率的提升,而非反思纠错能力的增强。
- 训练纠正性反思样本无效: 向训练数据中增加更多“纠正性反思”(F→T)的样本,并不能显著提升模型的纠错能力或整体性能。这进一步佐证了模型似乎难以从模仿纠错轨迹中学会通用的自我修正能力。
| 模型 | F→T 比例 | 平均 Tokens | 准确率 (%) | P(F→T) (%) |
|---|---|---|---|---|
| Llama3.1-8B-Instruct | 0% | 7618 | 49.3 | 2.1 |
| 25% | 7512 | 48.7 | 2.2 | |
| 50% | 7612 | 49.2 | 2.0 | |
| 75% | 7500 | 48.2 | 1.8 | |
| 100% | 7417 | 47.6 | 1.8 | |
| Qwen2.5-7B-Instruct | 0% | 8391 | 54.4 | 1.9 |
| 25% | 8345 | 54.0 | 2.1 | |
| 50% | 8452 | 53.9 | 2.0 | |
| 75% | 8711 | 55.1 | 1.8 | |
| 100% | 8421 | 53.4 | 1.9 |
最终结论
本文的系统性分析颠覆了“反思即纠错”的普遍看法。研究表明,当前推理模型中的长篇推理,其核心价值在于通过多样化的推理路径展示来增强模型“第一次就做对”的能力,而非在出错后进行有效的自我修正。基于这一洞见,本文提出的问题感知提前终止策略,证明了在几乎不牺牲核心推理能力的前提下,大幅优化推理效率是完全可行的。这为未来推理模型的设计和优化指明了新的方向:与其寄希望于复杂的反思纠错,不如专注于如何提升模型首次推理的准确性和鲁棒性。