GEM: A Gym for Agentic LLMs
-
ArXiv URL: http://arxiv.org/abs/2510.01051v1
-
作者: Chenmien Tan; Bo Liu; Michael Shieh; Hao Zhu; Haotian Xu; Zichen Liu; Xiangxin Zhou; Changyu Chen; Anya Sims; Yee Whye Teh; 等18人
-
发布机构: NUS; Northeastern; OpenRLHF; Oxford; RL2; ROLL; SMU; Sea AI Lab; Stanford; Wee Sun Lee
TL;DR
本文介绍了一个名为GEM(General Experience Maker)的开源环境模拟器,它旨在像传统强化学习领域的OpenAI-Gym一样,为智能体大语言模型(Agentic LLMs)提供一个标准化的训练与评估框架,从而推动研究从静态数据集学习转向基于环境交互的经验学习。
关键定义
- GEM (General Experience Maker): 一个为智能体大语言模型设计的开源环境模拟器。它提供了一个标准化的环境-智能体交互接口、多样化的任务套件、强大的集成工具以及高效的并行执行能力,旨在加速智能体LLM的研究。
- 智能体强化学习的三种视角 (Views of Agentic RL): 本文探讨了在强化学习中处理LLM与环境交互的三种不同方式:
- Token级动作: 将LLM生成的每个token视为一个独立动作。这导致轨迹过长且奖励难以分配。
- 响应级动作 (Response-level action): 将LLM一次生成的完整回复(直到结束符)视为一个动作。这是本文方法所采纳的视角,适用于多轮交互。
- 交互级动作 (Interaction-level action): 将整个多轮交互过程视为单个动作。这虽然能将问题简化为上下文老虎机,从而适用GRPO等算法,但代价是无法使用折扣因子(即\($\gamma=1\)$)且丧失了逐轮奖励的精细信用分配能力。
- REINFORCE with ReBN (Return Batch Normalization): 本文提出的一种简单而有效的基线算法。它在经典REINFORCE算法的基础上,引入了返回批量归一化(ReBN)技术,即在每个批次内对所有时间步的累积奖励(Return)进行归一化。该方法无需学习额外的价值函数,却能稳定策略梯度,并且完全适用于具有逐轮密集奖励和任意折扣因子的通用多轮强化学习场景。
相关工作
当前,针对LLM的强化学习(Reinforcement Learning, RL)研究主要集中在单轮任务上,例如数学问题解答或特定数据检索。在此类任务中,诸如GRPO这类基于样本的优势估计算法表现出色。
然而,这种单轮设定极大地简化了真实世界中复杂的、需要多轮交互的任务。直接将GRPO等为单轮任务设计的算法应用于多轮场景时,会遇到根本性的困难,或需要做出重大妥协,例如将整个交互视为单步、固定折扣因子\($\gamma=1\)$,并仅使用轨迹级别的稀疏奖励。这种妥协牺牲了对智能体行为效率的激励和精细的信用分配能力,阻碍了能够进行长时程规划、试错和迭代优化的智能体LLM的研发。
本文旨在解决这一瓶颈,通过推出GEM框架,为研究社区从单轮任务过渡到复杂的多轮、长时程交互任务提供必要的基础设施。
本文方法
本文的核心贡献分为两部分:GEM框架和作为基线算法的REINFORCE with ReBN。
GEM框架
GEM是一个受OpenAI-Gym启发而构建的、专为LLM智能体设计的环境框架。其目标是为LLM的强化学习研究提供标准化的基础设置。
- 标准化接口: GEM遵循了广泛使用的OpenAI Gym API设计,核心函数为\(reset()\)和\(step()\),使得智能体与环境的交互逻辑清晰简洁。
- 丰富的任务与工具: GEM采用模块化设计,将任务(Tasks)和工具(Tools)分离。
- 任务: 目前涵盖七大类:语言游戏(Language Games)、推理(ReasoningGym)、编程(Coding)、数学(Math)、问答(QA)、终端操作(Terminal)和视觉语言(Vision-Language)。
- 工具: 内置了Python解释器、网页搜索等工具。工具的引入可以将原本的单轮任务(如数学解题)转化为需要与工具进行多轮交互的复杂任务。
- 高效执行:
- 异步矢量化 (Asynchronous vectorization): 支持并行执行多个环境实例,通过异步工具调用大幅提升数据收集的吞吐量。
- 自动重置 (Autoreset): 环境在结束时会自动重置,简化了连续数据生成的代码逻辑,用户无需手动管理每个子环境的状态。
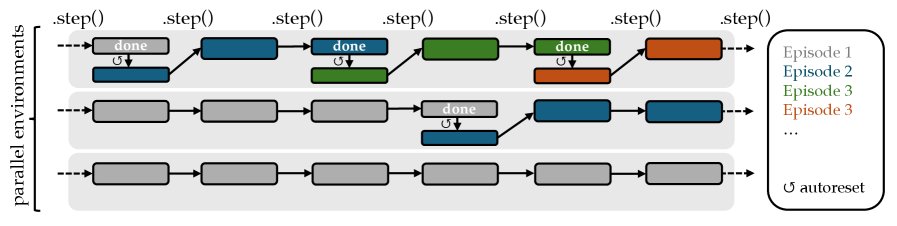
- 灵活的包装器 (Wrappers): 与Gym类似,GEM使用包装器来轻松扩展功能,例如,可以自定义观测(Observation)的格式(如仅保留最新输出、或拼接全部历史记录),也可以将工具实现为包装器叠加在任何任务环境之上。
RL算法:REINFORCE with ReBN
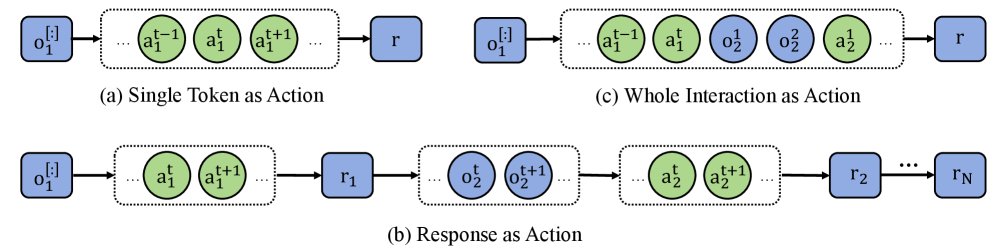
面对现有算法(如GRPO)在多轮任务上的局限性,本文回归到“响应即动作”的RL视角,并提出了一种简单、通用且高效的基线算法。
创新点
本文没有采用需要学习额外价值函数(Critic)的Actor-Critic方法(如PPO),也没有沿用在多轮场景下有局限性的GRPO,而是对基础的REINFORCE算法进行了改进。
该算法的优化目标如下:
\[\mathcal{J}_{\text{REINFORCE+ReBN}}(\theta)=\frac{1}{N}\sum_{n=1}^{N}\sum_{t=0}^{T^{(n)}-1}A_{\text{ReBN},t}^{(n)}\log\pi_{\theta}(a^{(n)}_{t} \mid s^{(n)}_{t})\]其中,$A^{(n)}_{\text{ReBN},t}=(G^{(n)}_{t}-\text{mean}(\mathbf{G}))/\text{std}(\mathbf{G})$,而$\mathbf{G}={G^{(n)}_{t}}_{n\in[1,\dots,N],t\in[1,\dots,T^{(n)}-1]}$是整个批次中所有轨迹、所有时间步的折扣回报(return)$G_t = \sum_{k=t}^{T-1}\gamma^{k-t}r_k$的集合。
优点
- 通用性强: 与GRPO不同,REINFORCE with ReBN完全兼容具有逐轮密集奖励(per-turn dense rewards)和任意折扣因子\($\gamma \leq 1\)$的完整RL设定,使其能处理更复杂的长时程交互任务。
- 无需Critic: 它避免了训练一个独立的价值网络(Critic)带来的复杂性和不稳定性,相比PPO等方法实现更简单。
- 高效的信用分配: 通过对整个批次的回报进行归一化(ReBN),该方法有效地稳定了策略梯度的估计,起到了类似优势函数(advantage function)的作用,实现了比原始REINFORCE更稳定、更高效的学习。
- 计算开销低: 相较于需要在每个时间步进行多次采样以估计优势的GRPO或需要训练Critic的PPO,该方法的计算开销更小。
实验结论
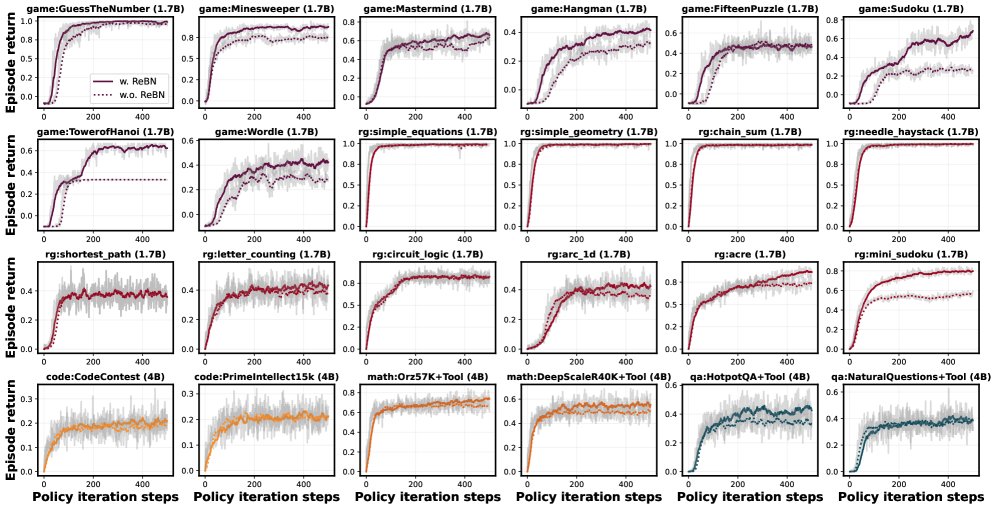
本文通过一系列实验验证了GEM框架的有效性和REINFORCE with ReBN算法的优越性。
算法基准测试
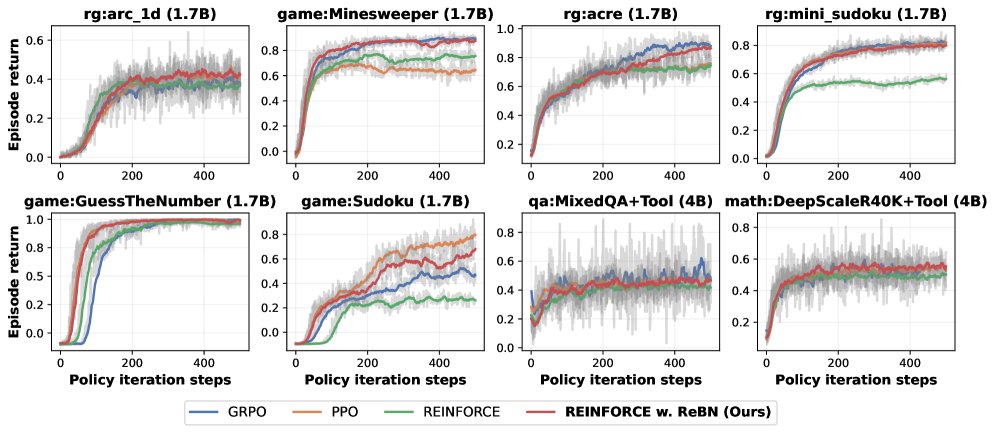
在8个涵盖单轮和多轮任务的环境中,对PPO、GRPO、REINFORCE和REINFORCE with ReBN(简称ReBN)进行了公平对比。
- GRPO: 在单轮任务中表现良好,但在需要精细信用分配的多轮任务中表现不佳。
- PPO: 总体表现强劲,尤其在长时程任务中能取得最佳回报,但其性能依赖于一个难以稳定训练的Critic网络。
- REINFORCE: 作为基线表现不俗,但有时会陷入次优收敛。
- REINFORCE with ReBN: 表现最为出色。它在所有环境中都一致且显著地优于原始REINFORCE,并且性能与PPO相当或更优。这证明了它是一个强大、稳定且计算高效的基线算法。
折扣因子\($\gamma\)$的影响
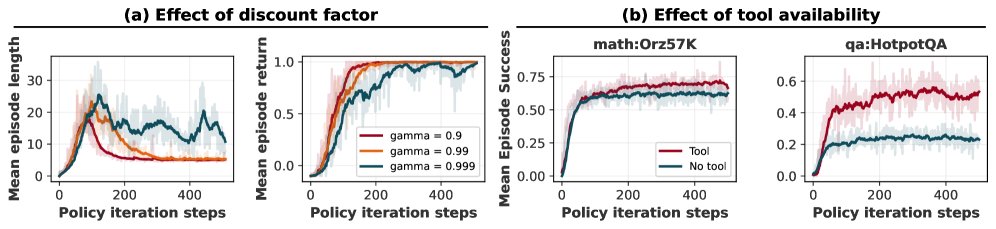
在“猜数字”游戏中,实验证明,设置\($\gamma < 1\)$会自然地激励智能体寻找更短的解决方案(即轮数更少)。只有当\($\gamma\)$较小时,智能体才能学习到最优的二分搜索策略。这凸显了可调节折扣因子的重要性,而这是GRPO在多轮设定下所不具备的。
工具集成的效果
在数学(Math)和问答(QA)任务中,实验对比了有无工具(Python解释器和搜索引擎)以及是否经过RL训练的效果。
数学任务基准分数
| Qwen3-4B-Base | 基础模型 (无工具) | 基础模型 (有工具) | 基础+RL (无工具) | 基础+RL (有工具) |
|---|---|---|---|---|
| AIME24 | 10.0 | 6.7 | 16.7 | 30.0 |
| AMC | 39.8 | 50.6 | 49.4 | 67.5 |
| MATH500 | 61.0 | 62.4 | 67.4 | 71.0 |
| MinervaMath | 36.4 | 30.1 | 40.1 | 40.4 |
| OlympiadBench | 29.5 | 31.0 | 33.5 | 39.9 |
| 平均分 | 35.3 | 36.2 | 41.4 | 49.8 |
问答任务基准分数
| Qwen3-4B | 基础 (无工具) | 基础+RL (无工具, 单环境) | 基础+RL (无工具, 混合环境) | 基础+RL (有工具, 单环境) | 基础+RL (有工具, 混合环境) |
|---|---|---|---|---|---|
| NQ† | 6.1 | 15.4 | 15.8 | 35.0 | 37.3 |
| TriviaQA† | 35.4 | 43.4 | 44.9 | 69.0 | 71.9 |
| PopQA† | 11.3 | 19.0 | 19.9 | 47.1 | 48.1 |
| HotpotQA* | 11.1 | 21.1 | 22.1 | 43.2 | 45.5 |
| 2wiki* | 10.0 | 26.8 | 30.1 | 44.5 | 46.7 |
| Musique* | 2.9 | 4.7 | 5.5 | 17.6 | 19.9 |
| Bamboogle* | 17.6 | 28.8 | 28.8 | 49.6 | 48.8 |
| 平均分 | 10.2 | 22.7 | 23.9 | 43.7 | 45.5 |
结论: 结果一致表明:
- 经过RL训练的模型性能远超基础模型。
- 集成了工具的模型在所有评估场景中均取得了最佳性能。
泛化能力研究
初步实验展示了积极的泛化结果:在\(game:Wordle-v0\)上训练的智能体,在未见过的\(ReasoningGym\)系列任务上也表现出性能提升。 
总结
本文成功推出了GEM,一个对标OpenAI-Gym的、用于智能体LLM的标准化训练和评估环境。同时,提出的REINFORCE with ReBN算法被证明是一个简单、通用且极为有效的基线方法,特别适合多轮交互任务。GEM及其配套工具和算法为未来更强大、更自主的AI系统的研究铺平了道路。