Gemma 2: Improving Open Language Models at a Practical Size
-
ArXiv URL: http://arxiv.org/abs/2408.00118v3
-
作者: Anton Tsitsulin; Joana Carrasqueira; Xiang Xu; N. Devanathan; Matthew Watson; H. Dhand; Josh Lipschultz; Tomás Kociský; Se-bastian Krause; Lucas Dixon; 等185人
-
发布机构: Google DeepMind
TL;DR
本文介绍Gemma 2系列开放语言模型(2B、9B、27B),通过在Transformer架构中交错使用局部-全局注意力、采用分组查询注意力,并对2B和9B模型应用知识蒸馏进行训练,实现了在同等参数规模下的最佳性能,甚至能与2-3倍大的模型相媲美。
关键定义
本文主要在现有技术的基础上进行组合与改进,以下是对理解本文方法至关重要的几个核心技术:
- 知识蒸馏 (Knowledge Distillation): 一种训练策略,其中一个较小的“学生”模型(如Gemma 2的2B和9B模型)不直接学习预测下一个词元 (token),而是学习模仿一个更大、更强的“教师”模型的输出概率分布。这为学生模型提供了比标准one-hot标签更丰富的梯度信号,从而在同等训练数据量下达到更好的性能,模拟了在更多数据上训练的效果。
- 交错式局部-全局注意力 (Interleaving Local-Global Attention): 一种混合注意力机制。模型架构中的Transformer层交替使用两种注意力模式:一层使用局部滑动窗口注意力 (Sliding Window Attention),只关注最近的4096个token;下一层则使用全局注意力 (Global Attention),可以关注整个8192个token的上下文。这种设计旨在平衡计算效率和长距离依赖的捕获能力。
- 分组查询注意力 (Grouped-Query Attention, GQA): 一种注意力变体,将查询头(Query heads)分成几组,每组共享一套键(Key)和值(Value)头。本文中,\(num_groups\)设为2,这意味着KV头的数量是Q头的一半。该技术在保持模型性能的同时,降低了推理时的内存占用和计算量。
- Logit软上限 (Logit soft-capping): 一种稳定训练的技术,通过一个\(tanh\)函数将注意力层和最终输出层的logits值限制在一个预设的\(soft_cap\)范围内(注意力层为50,最终层为30)。其公式为:\(logits\) $\leftarrow$ \(soft_cap\) $\times \tanh(\text{logits} / \text{soft_cap})$。
相关工作
当前,小型语言模型的性能提升主要依赖于大幅增加训练数据量,但这种方法的回报遵循对数规律递减,即效果提升越来越有限。例如,最新的小型模型需要多达15T的token才能获得1-2%的微小性能改进,这表明现有的小模型仍处于训练不足(under-trained)的状态。
本文旨在解决的核心问题是:如何在不单纯依赖海量增加训练数据的情况下,找到更有效的方法来提升小型语言模型的性能。研究者们探索用更丰富的训练目标(如知识蒸馏)替代传统的“下一个token预测”任务,为模型在每一步训练中提供更高质量的信息。
本文方法
Gemma 2模型家族建立在Gemma 1的解码器-仅(decoder-only)Transformer架构之上,但引入了多项关键的架构和训练方法改进。
模型架构
Gemma 2的架构在保留RoPE位置编码和GeGLU激活函数等Gemma 1特性的同时,引入了显著的更新,旨在提升性能和效率。
- 更深的神经网络: 相比Gemma 1,Gemma 2采用了更深的网络结构,消融实验证明更深的模型在同等参数量下性能略优于更宽的模型。
- 交错式局部-全局注意力: 模型在不同层之间交替使用局部滑动窗口注意力(窗口大小4096)和全局注意力(范围8192),以兼顾效率和长上下文建模能力。
- 分组查询注意力 (GQA): 所有模型均采用GQA,并将KV头的数量设置为查询头的一半,以在不牺牲性能的前提下加速推理。
- 双重归一化 (Pre-norm & Post-norm): 为了稳定训练,每个Transformer子层(注意力和前馈网络)的输入和输出都使用RMSNorm进行归一化。
- Logit软上限: 在自注意力层和最终输出层对logits进行软上限处理,以增强训练稳定性。
下表总结了Gemma 2各尺寸模型的关键架构参数:
| 参数 | 2B | 9B | 27B |
|---|---|---|---|
| d_model | 2304 | 3584 | 4608 |
| 层数 | 26 | 42 | 46 |
| Pre-norm | 是 | 是 | 是 |
| Post-norm | 是 | 是 | 是 |
| 非线性函数 | GeGLU | GeGLU | GeGLU |
| 前馈网络维度 | 18432 | 28672 | 73728 |
| 注意力头类型 | GQA | GQA | GQA |
| 查询头数量 | 8 | 16 | 32 |
| KV头数量 | 4 | 8 | 16 |
| 头大小 | 256 | 256 | 128 |
| 全局注意力范围 | 8192 | 8192 | 8192 |
| 滑动窗口大小 | 4096 | 4096 | 4096 |
| 词汇表大小 | 256128 | 256128 | 256128 |
| 词嵌入绑定 | 是 | 是 | 是 |
预训练
Gemma 2的预训练在一系列关键方面与Gemma 1有所不同。
- 训练数据: 27B模型在13T token上训练,9B在8T上训练,2B在2T上训练。数据源主要为英文网页文档、代码和科学文献。数据处理沿用了Gemma 1的过滤技术,以减少不安全内容、个人信息和评估集污染。
- 知识蒸馏: 这是2B和9B模型训练的核心创新。它们并非采用传统的下一个token预测损失函数,而是通过最小化与教师模型(一个更大的语言模型)输出概率分布的负对数似然来进行训练。目标函数如下:
其中 $P_{S}$ 是学生模型的概率分布,$P_{T}$ 是教师模型的概率分布,$x_c$ 是上下文。这种方法被用来“模拟超越可用token数量的训练”。27B模型则仍采用传统的从头训练方式。
后训练
为了得到指令微调(instruction-tuned)模型,本文对预训练模型进行了一系列后训练处理。
- 监督微调 (SFT): 在混合了合成与人类生成的“提示-回复”对上进行微调。
- 基于人类反馈的强化学习 (RLHF): 使用比策略模型大一个数量级的奖励模型进行RLHF,新奖励模型更侧重于多轮对话能力。
- 模型合并: 将不同超参数下训练得到的模型进行平均,以提升整体性能。
- 格式化: 指令微调模型使用了新的对话格式,模型在生成结束时会明确使用\(<end_of_turn><eos>\)序列,而非仅有\(<eos>\)。这有助于更好地管理多轮对话流程。
实验结论
本文通过大量的消融实验和基准评估,验证了Gemma 2在架构和训练方法上的优势。
核心实验发现
- 知识蒸馏的有效性: 消融实验证明,使用知识蒸馏训练的2B模型(在500B token上训练)性能远超从头开始训练的模型(平均分67.7 vs 60.3)。这证实了知识蒸馏能够显著提升模型质量,即使在远超计算最优(compute-optimal)的token数量下也是如此。
- 架构选择的合理性: 实验表明,在同等参数量下,更深的网络结构略优于更宽的结构。GQA在性能上与多头注意力(MHA)相近,但推理速度更快。
- 预训练模型性能: Gemma 2 27B在各项基准测试中优于同等规模的Qwen1.5 32B,并与尺寸大2.5倍、训练数据量多2/3的LLaMA-3 70B模型表现出很强的竞争力。得益于知识蒸馏,Gemma 2 9B和2B模型相较于Gemma 1在多个基准上取得了高达10%的巨大性能提升。
下表展示了预训练模型在部分核心基准上的表现:
| LLaMA-3 70B | Qwen1.5 32B | Gemma-2 27B | |
|---|---|---|---|
| MMLU | 79.2 | 74.3 | 75.2 |
| GSM8K | 76.9 | 61.1 | 74.0 |
| ARC-c | 68.8 | 63.6 | 71.4 |
| HellaSwag | 88.0 | 85.0 | 86.4 |
后训练模型性能
- LMSYS聊天机器人竞技场: Gemma 2的指令微调模型在人类盲测中表现出色。Gemma 2 27B (Elo 1218) 的排名高于Llama 3 70B (Elo 1206);Gemma 2 9B (Elo 1187) 与GPT-4-0314 (Elo 1186) 相当;Gemma 2 2.6B (Elo 1126) 排名高于GPT-3.5-Turbo-0613 (Elo 1116)。这标志着Gemma 2在同规模开放模型中达到了新的SOTA水平。
- 人类偏好与多轮对话评估: 在独立的内部评估中,Gemma 2模型在安全性和指令遵循方面相比Gemma 1.1有显著提升,并且在多轮对话中的用户满意度和目标达成率也远高于前代模型。
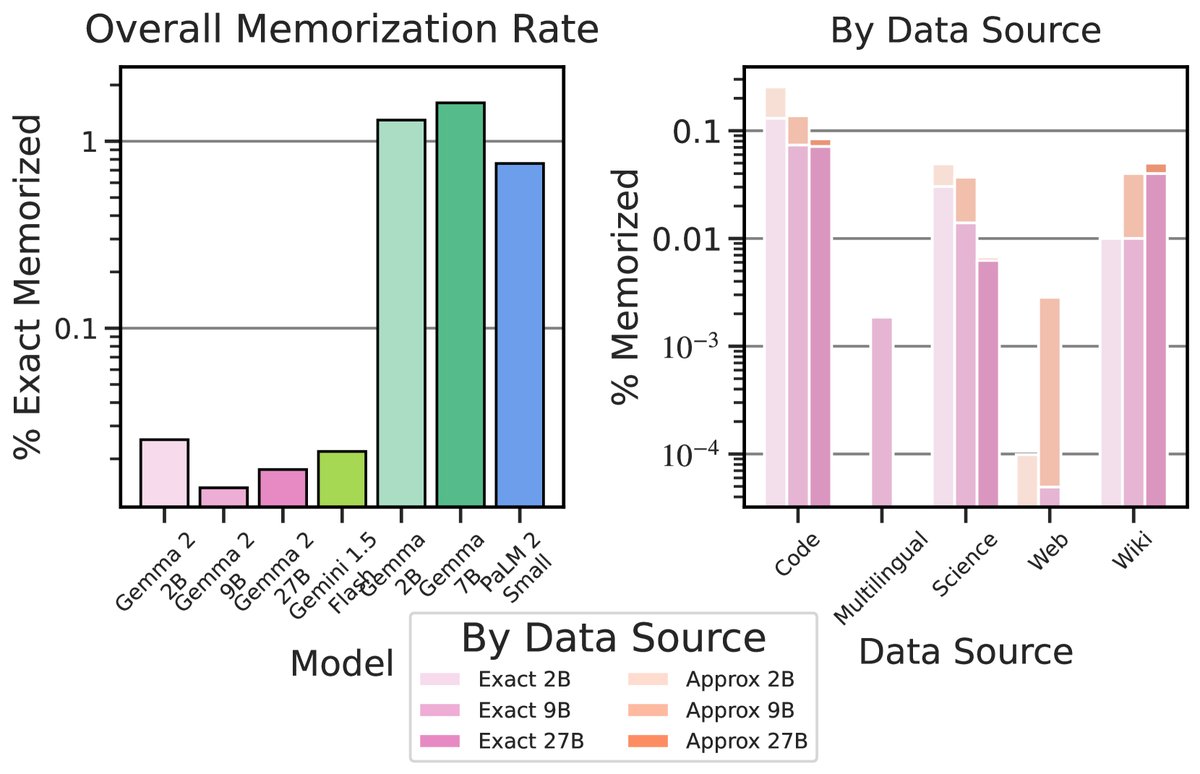
- 记忆化与隐私: Gemma 2的记忆化率极低,无论是精确匹配还是近似匹配,其记忆率都远低于包括Gemma 1在内的先前模型。
最终结论
Gemma 2通过架构改进(如交错式注意力)和创新的训练方法(特别是大规模应用知识蒸馏),成功地在不显著增加模型尺寸的前提下,大幅提升了模型的综合能力。实验结果表明,Gemma 2不仅在自动化基准上领先于同类开放模型,在反映真实世界应用的人类评估中也表现出极强的竞争力,为开发实用、高效且负责任的AI应用提供了强大的新工具。