Generative AI
-
ArXiv URL: http://arxiv.org/abs/2309.07930v1
-
作者: Jochen Hartmann; Patrick Zschech; Stefan Feuerriegel; Christian Janiesch
-
发布机构: FAU Erlangen-Nürnberg; LMU Munich; Munich Center for Machine Learning; TU Dortmund University; Technical University of Munich
Generative AI
概念化
生成式AI的数学原理
生成式人工智能 (Generative AI) 主要基于生成式建模 (generative modeling),这在数学上与常用于数据驱动决策支持的判别式建模 (discriminative modeling) 有显著区别。
-
判别式建模:旨在学习数据点 \(X\) 和类别 \(Y\) 之间的决策边界,以将 \(X\) 分到不同的类别中(例如,分类任务中 \(Y ∈ {0,1}\))。它学习的是条件概率 $$P(Y X)$$。 - 生成式建模:旨在推断数据的实际分布。例如,学习输入 \(X\) 和输出 \(Y\) 的联合概率分布 \(P(X,Y)\),或者在 \(Y\) 是高维空间时学习 \(P(Y)\)。通过学习数据分布,生成式模型能够生成新的合成样本。
本文将相关概念定义如下:
- 生成式AI模型:指使用机器学习架构(如深度神经网络)实现的生成式建模,能够基于从训练数据中学到的模式创建新数据样本。
- 生成式AI系统:包含模型、数据处理和用户界面等组件的完整基础设施。模型是系统的核心。
- 生成式AI应用:指这些系统的实际用例和实现,用于解决现实世界问题,如内容生成或代码生成。
下表总结了在模型、系统和应用层面上跨不同数据模态的生成式AI。
| 模型层面 | 系统层面 | 应用层面 | |
|---|---|---|---|
| 输出模态(部分) | 不同数据模态的底层AI模型 | 嵌入模型功能以提供交互界面 | 解决特定业务问题和利益相关者需求 |
| 文本生成 | X-to-text 模型,如 GPT-4 和 LLaMA 2 | 对话智能体和搜索引擎,如 ChatGPT 和 YouChat | 内容生成(如SEO和客户服务)、翻译和文本摘要 |
| 图像/视频生成 | X-to-image 模型,如 Stable Diffusion 和 DALL-E 2 | 图像/视频生成系统和机器人,如 Runway 和 Midjourney | 合成产品和广告视觉效果、教育内容 |
| 语音/音乐生成 | X-to-music/speech 模型,如 MusicLM 和 VALL-E | 语音生成系统,如 ElevenLabs | AI音乐生成、文本到语音生成(如新闻、产品教程等) |
| 代码生成 | X-to-code 模型,如 Codex 和 AlphaCode | 编程代码生成系统,如 GitHub Copilot | 软件开发、代码合成、审查和文档编写 |
模型、系统和应用层面的生成式AI视图
分类体系
本文提出了一个三层框架来理解生成式AI:模型层、系统层和应用层。这个分类体系的核心维度是技术实现与最终用户价值的距离,从底层的算法核心到顶层的实际业务解决方案。
模型层面 (Model-Level)
模型是生成式AI的核心,是一种使用AI算法从训练数据中学习模式并创建新数据实例的机器学习架构。它具有至关重要但不完整性,需要通过系统和应用进行特定任务的微调。
- 核心技术:深度神经网络是主要架构,特别是Transformer架构被广泛用于处理序列数据(如语言),而扩散概率模型(diffusion probabilistic models)则常用于文生图。
- 基础模型 (Foundation Models):指那些规模巨大、功能全面且通用的生成式AI模型。它们具有两大关键特性:
- 涌现性 (Emergence):模型表现出未经明确训练的行为,这些行为是隐式诱导而非显式构建的。例如,GPT模型能创建\(.ical\)格式的日历条目。
- 同质化 (Homogenization):单个统一模型可以支持大量不同的系统和应用。例如,Copilot能生成多种编程语言的代码。
- 模型分类:根据输入输出类型,模型可分为单模态 (unimodal)(输入输出类型相同,如纯文本模型)和多模态 (multimodal)(支持不同类型的输入输出,如文本到图像)。
- 训练方法:训练过程多种多样,如下图所示。例如,生成对抗网络 (Generative Adversarial Networks, GANs) 通过生成器和判别器的对抗来学习;而类似ChatGPT的系统则使用基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 来优化输出,使其更符合人类偏好。
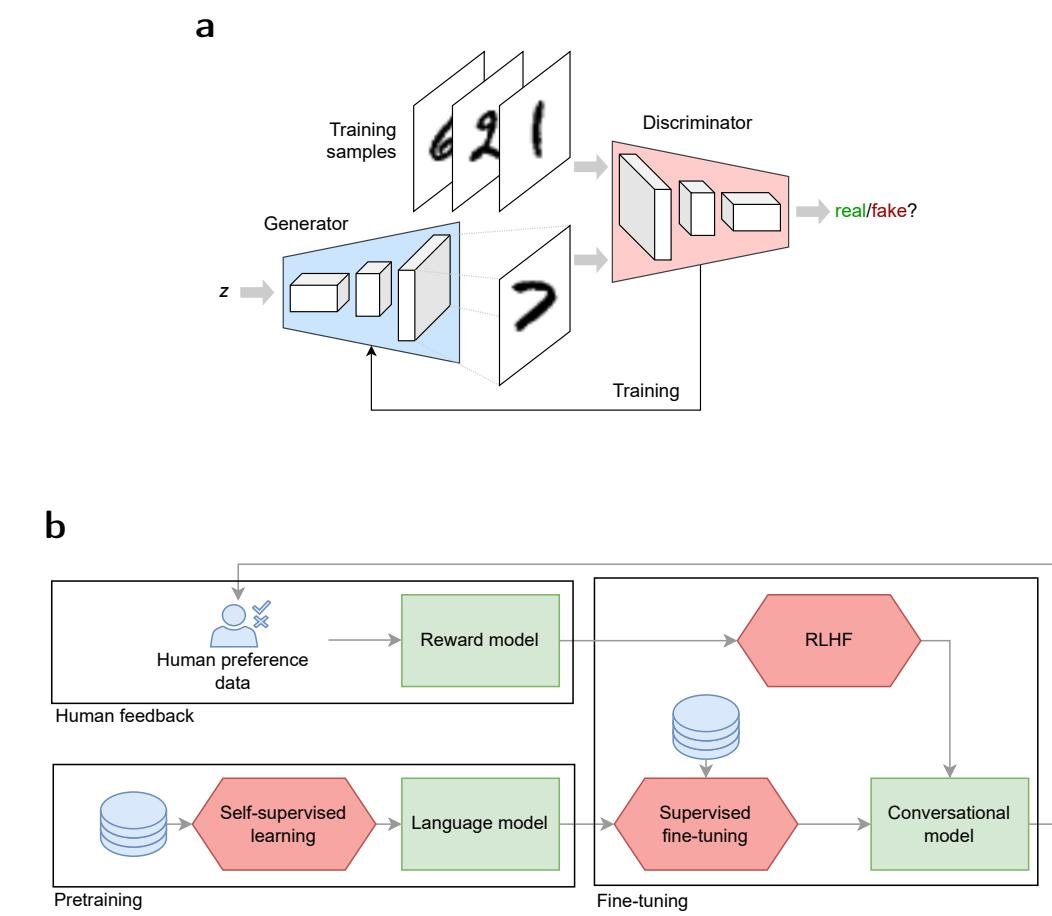
下表概述了生成式AI中常见的核心概念和模型架构。
| 概念 | 描述 |
|---|---|
| 扩散概率模型 (Diffusion probabilistic models) | 一类潜变量模型,常用于图像生成等任务。通过模拟数据点在潜空间中的扩散过程来捕捉数据分布,然后逆转该过程以生成自然图像。Stable Diffusion是其著名变体。 |
| 生成对抗网络 (Generative adversarial network) | 一种包含两个相互竞争的神经网络(生成器和判别器)的架构。生成器学习生成逼真样本,判别器学习区分真实样本和生成样本,通过这种对抗学习使生成器产生高质量输出。 |
| (大)语言模型 ((Large) language model) | 用于建模和生成文本的神经网络,通常结合了大规模(如Transformer)、自监督预训练(如“预测下一个词”)和海量文本数据训练三个特点。LLM拥有数十亿参数,如GPT-3。 |
| 基于人类反馈的强化学习 (Reinforcement learning from human feedback) | 通过人类反馈来学习序列任务(如对话)的方法。它先从人类反馈中训练一个奖励模型,再用此模型作为奖励函数来优化策略,使输出更符合人类偏好。ChatGPT就使用了该技术。 |
| 提示学习 (Prompt learning) | 一种利用LLM中存储的知识来完成下游任务的方法,无需对模型进行微调。通过设计特定的输入提示(prompt),引导模型生成期望的输出。 |
| 序列到序列 (seq2seq) | 一种将输入序列映射到输出序列的机器学习方法,常见于机器翻译。它由一个编码器(将输入序列编码为向量)和一个解码器(将向量解码为输出序列)组成。 |
| Transformer | 一种采用自注意力机制 (self-attention) 的深度学习架构,能权衡输入数据各部分的重要性。它能并行处理整个输入序列,在自然语言处理任务中表现优于循环神经网络(RNN)。 |
| 变分自编码器 (Variational autoencoder) | 一种将输入数据编码到低维潜空间再从中重构原始数据的神经网络。它采用概率方法进行编解码,使其能捕捉数据分布并生成新样本。 |
| 零样本/少样本学习 (Zero-shot / few-shot learning) | 解决数据稀缺问题的学习范式。零样本学习指模型在未见过任何任务样本的情况下执行任务;少样本学习指仅用少量样本学习。LLM是出色的少样本/零样本学习者。 |
系统层面 (System-Level)
系统层面将底层的AI模型与基础设施、用户界面和数据处理组件相结合,从而增强模型的实用性和易用性。
- 核心作用:系统将模型的功能嵌入到一个可交互的界面中。例如,GitHub Copilot系统集成了Codex模型,Midjourney系统通过Discord机器人让用户与底层的图像生成模型交互。
- 关键问题:系统层面关注的是可扩展性、部署、可用性以及持续的模型监控,以防止性能退化。ChatGPT的成功不仅在于其模型强大,更在于其简洁易用的系统界面。
- 功能增强:系统可以集成外部工具(如实时信息检索)来克服模型的局限性,例如知识截止日期和信息压缩问题。
应用层面 (Application-Level)
应用层面是生成式AI系统在特定组织或场景中,为解决具体业务问题、满足利益相关者需求而创造价值的实践。
- 本质:应用是“人-任务-技术”系统,利用生成式AI技术增强人类完成特定任务的能力。
- 应用场景:涵盖从SEO内容生成、电影制作到软件开发等无数真实世界用例。
- 影响:生成式AI应用将催生新的工作模式,并逐步从处理常规任务转向辅助医疗、法律等更敏感和关键的决策。这要求我们为可信赖的设计提供原则,并审视其对用户信任度的影响。
生成式AI的社会技术视图
- AI能力的演变:AI的能力从过去主要被理解为用于决策的分析能力 (analytic capability),扩展到了现在用于内容创作的生成能力 (generative capability)。
- 人机交互模式的转变:传统的IT工具被视为被动工具,而由LLM驱动的智能体IT工件 (agentic IT artifacts) 正在挑战“人类主导”的假设。人与AI的交互模式正从委托 (delegation) 模式转向共创 (co-creation) 模式,即双方在协作中扮演不同角色,共同引导创作过程。
- 混合智能的重构:生成式AI的共创能力正在改变我们对混合智能(结合人类与AI优势)的理解。需要新的人机交互模型来指导人和AI系统的行为。
- 心智理论与人造心智理论:心理学中的心智理论 (Theory of Mind) 描述了人类理解他人意图和情感的能力。随着AI交互日益自然,人类也需要一个“人造心智理论” (theory of the artificial mind),来解释和预测AI系统的行为逻辑,从而更好地与之协作。
当前生成式AI的局限性
本文指出了当前生成式AI在模型层面存在的四个主要技术局限性,这些局限性可能长期存在,并对系统和应用层面产生影响。
-
输出不准确 (Incorrect outputs):生成式AI基于概率算法,旨在生成最可能的回应,而非绝对正确的回应。这导致了“幻觉” (hallucination) 现象——模型产生看似合理但实际上是无稽之谈或不正确的内容。这类输出难以验证,可能传播错误信息。
-
偏见与公平性 (Bias and fairness):由于训练数据源于充满社会偏见的人类内容,生成式AI模型会学习并放大这些偏见,如性别、种族和宗教歧视。尽管可以通过对齐过程(如RLHF)和系统级缓解措施来解决部分问题,但实现真正的“公平AI”仍是开放的研究课题。
-
版权侵犯 (Copyright violation):生成式AI可能产生与现有受版权保护作品相似甚至完全相同的内容,从而引发版权问题。这涉及两个主要风险:一是模型可能在训练中接触并复制了受版权保护的材料;二是在未接触的情况下也可能“偶然”生成了相似内容(如商标)。此外,由AI生成作品的知识产权归属也是一个悬而未决的法律问题。
-
环境问题 (Environmental concerns):训练和运行大规模神经网络(如GPT-3)需要消耗巨大的电力,产生大量的碳足迹。例如,训练GPT-3的碳排放量相当于几十个家庭一年的排放量。这促使AI研究社区寻求更高效的训练算法、模型压缩技术和优化的硬件来减少对环境的影响。
对BISE社区的启示与未来方向
生成式AI为商业与信息系统工程 (Business & Information Systems Engineering, BISE) 领域带来了大量研究机遇和挑战。下表列举了部分研究问题。
| BISE部门 | 研究问题(示例) |
|---|---|
| 业务流程管理 | • 生成式AI如何辅助自动化常规任务? • 生成式AI如何揭示流程创新机会并支持流程(再)设计? |
| 决策分析与数据科学 | • 如何有效地为特定领域应用微调生成式AI模型? • 如何提高生成式AI系统的可靠性? |
| 数字业务管理与数字领导力 | • 生成式AI如何支持资源分配等管理任务? • 随着由生成式AI驱动的智能助手的出现,员工的数字工作将如何改变? |
| 信息系统经济学 | • 生成式AI对社会福利有何影响? • 哪些工作和任务受生成式AI影响最大? |
| 企业建模与企业工程 | • 如何使用生成式AI来支持企业模型的构建和维护? • 生成式AI如何支持企业应用(如CRM、BI等)? |
| 人机交互与社会计算 | • 应如何设计生成式AI系统以培养信任? • 哪些对策能有效防止用户受AI生成的虚假信息欺骗? • 生成式AI在多大程度上可以取代或增强众包任务? • 生成式AI如何辅助教育? |
业务流程管理 (Business Process Management)
- 流程生命周期:生成式AI可用于流程发现(如从文本生成流程描述)、流程改进(如为流程再设计提供创意)以及流程执行(如开发新一代动态、自适应的流程指导系统,从非结构化数据中提取知识)。
- 短期影响:将推动机器人流程自动化 (RPA) 的发展,用智能化的方式替代手工规则。
- 长期潜力:创建能够整合企业内部分散知识(如手册、邮件、Wiki)的智能流程指导系统。
决策分析与数据科学 (Decision Analytics and Data Science)
- 模型定制化:研究如何为特定领域(如医疗、金融)高效且安全地定制生成式AI模型,以提升性能。
- 可靠性提升:开发算法和用户中心化的解决方案,以检测和减轻“幻觉”现象,例如通过提供可验证的解释或参考资料。
- 模型可解释性:利用生成式AI将复杂的分析模型(如SHAP或LIME的输出)解释为普通用户能理解的自然语言描述,弥合建模专家与领域用户之间的鸿沟。
数字业务管理与数字领导力 (Digital Business Management and Digital Leadership)
- 价值创造:研究生成式AI如何通过知识创造、任务增强和自主智能体来创造价值,并探讨成功利用该技术所需的组织能力。
- 管理与工作模式:AI助手将接管更多管理任务(如资源分配),算法化管理 (algorithmic management) 理论需要被重新审视。员工的工作模式将发生改变,“提示工程”可能成为一项关键技能。
- 知识管理:生成式AI将彻底改变组织的知识管理方式,实现自动化的知识发现、共享和个性化推送。
信息系统经济学 (Economics of Information Systems)
- 经济影响量化:通过严谨的因果推断(如田野实验)来量化生成式AI对生产力、创新和创造力的影响。
- 产业变革:研究生成式AI对内容平台(如图片库、问答网站)的颠覆性影响,以及开源与闭源模型对市场竞争格局的影响。一个关键问题是少数科技巨头掌握大量交互数据所带来的经济后果。
- 经济政策:探讨生成式AI对未来工作模式、知识产权保护、市场垄断以及社会福利的深远影响,为制定相应政策提供依据。
企业建模与企业工程 (Enterprise Modeling and Enterprise Engineering)
- 建模辅助:利用生成式AI作为辅助技术,解决传统企业模型静态、构建维护成本高昂的痛点。
- 自动化与多模态:研究如何利用生成式AI自动创建和更新不同抽象级别的企业模型,或生成多模态的模型表示(如文本描述直接生成BPMN图)。已有初步研究表明,生成式AI在从文本描述生成概念模型方面具有很高的准确性。