Generative Data Refinement: Just Ask for Better Data
-
ArXiv URL: http://arxiv.org/abs/2509.08653v2
-
作者: Edward Grefenstette; Will Ellsworth; Minqi Jiang; Sian Gooding
-
发布机构: Google DeepMind
TL;DR
本文提出了一个名为“生成式数据精炼”(Generative Data Refinement, GDR)的框架,利用预训练的生成模型将包含不良内容(如个人信息、有毒内容)的原始数据集重写为更适合模型训练的、经过精炼的高质量数据集,同时保留了数据的多样性和实用性。
关键定义
- 生成式数据精炼 (Generative Data Refinement, GDR):一个利用预训练的生成模型来转换数据集的框架。它针对数据集中每个样本,通过生成式重写来移除不希望出现的内容(如个人可识别信息、有毒言论),同时保留其他有用的信息,从而产出一个“精炼后”的数据集。
- 扎根合成数据 (Grounded Synthetic Data):指那些以真实数据样本为基础(或条件)生成的合成数据。与完全从零开始、仅通过提示(prompting)生成的合成数据不同,GDR产出的数据属于扎根合成数据,因为它是在修改真实数据样本的基础上进行的,从而能更好地保留真实世界数据的多样性。
相关工作
当前,大规模模型的能力受限于训练数据的质量与数量。由于公开索引的数据集即将耗尽,研究人员开始关注未被公开索引的海量用户生成内容。然而,直接使用这些数据存在巨大风险,如泄露隐私、传播有毒或受版权保护的内容。
为解决此问题,现有方法主要有两类:
- 纯合成数据生成:使用预训练模型生成全新的数据。这种方法的主要瓶颈在于,生成数据的多样性受限于教师模型,容易出现模式坍塌(mode collapse),且生成内容可能与真实数据分布存在偏差。
- 差分隐私 (Differential Privacy, DP):通过向数据或算法(如DP-SGD)中注入噪声来提供隐私保护。但这种方法以牺牲数据效用为代价,无法解决数据集中普遍存在的敏感信息泄露问题(data leakage),并且会显著增加计算成本。
本文旨在解决的核心问题是:如何安全、高效地利用这些存在风险但信息丰富的未索引数据,同时避免纯合成数据生成的多样性差和差分隐私的效用损失问题。
本文方法
GDR框架的核心思想是将数据清洗任务重新定义为一个“生成式重写”问题。它不直接删除或简单替换不良内容,而是利用大型语言模型(LLM)的强大理解和生成能力,对每个数据样本进行智能化的重写和精炼。
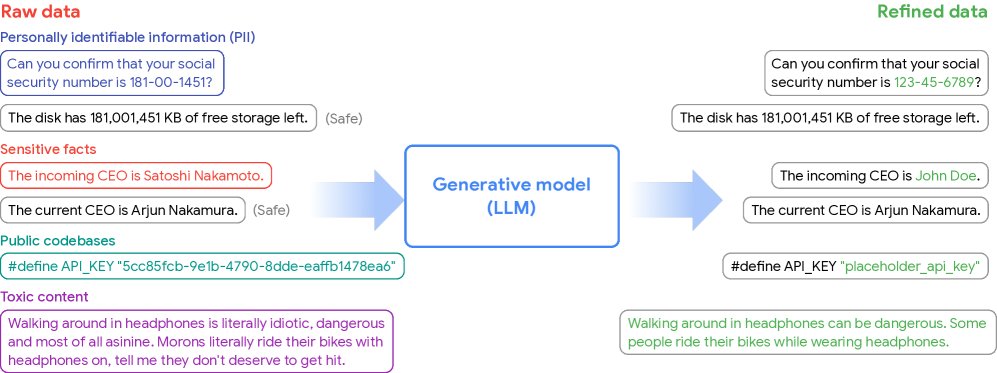 图1:生成式数据精炼(GDR)概览。原始数据(可能包含个人身份信息、有毒内容等)被输入到一个预训练的生成模型中。该模型利用其丰富的世界知识,精炼每个样本,去除不良内容,同时保留其他有用信息,最终生成一个适合训练的精炼数据集。
图1:生成式数据精炼(GDR)概览。原始数据(可能包含个人身份信息、有毒内容等)被输入到一个预训练的生成模型中。该模型利用其丰富的世界知识,精炼每个样本,去除不良内容,同时保留其他有用信息,最终生成一个适合训练的精炼数据集。
方法本质
GDR的形式化定义如下:给定一个原始数据集 $D$ 中的样本 $x_i$,目标是寻找一个生成过程 $g$(例如,一个带提示的LLM),使得生成的样本 $y_i \sim g(\cdot \mid x_i)$ 在满足特定标准 $h(y_i)=1$(如不含有害内容)的同时,与原始样本的距离 $\Delta(x_i, y_i)$ 最小化。
这个过程本质上是将LLM作为一个“智能噪声算子”。与差分隐私(DP)中添加高斯噪声的盲目做法不同,GDR利用LLM的上下文理解能力,选择性地、有针对性地修改数据中的问题部分。例如,它不是简单地将姓名替换为\([REDACTED]\),而是可能替换为一个上下文相关的、虚构的姓名,从而最大程度地保留原始句子的结构和非敏感信息。
创新点与优点
- 保留数据多样性:由于GDR的每个输出都“扎根”于一个真实的输入样本,它能继承真实世界数据集的内在多样性。这有效解决了传统合成数据方法中常见的模式坍塌问题,即生成内容高度重复、缺乏多样性。
- 保留数据效用:通过智能重写而非删除,GDR能够保留原始数据中的绝大部分有用信息。实验证明,在经过GDR处理的数据集上训练的模型,既能学习到原始数据中的公共知识,又能有效避免泄露私密或有毒内容。
- 通用性与易用性:GDR框架非常通用。仅通过设计不同的提示(prompt),就可以用同一个强大的LLM来完成多种数据精炼任务,例如数据匿名化和内容去毒,且可应用于文本、代码等多种数据模态。
- 成本可控:虽然对大规模数据集进行推理的初始成本可能很高,但这个成本可以被摊销,因为精炼后的数据集可以被重复使用。更重要的是,实验表明,通过对小型模型进行监督微调(SFT)或使用少样本提示(few-shot prompting),可以在特定任务上达到甚至超过大型模型的性能,从而显著降低实际应用中的计算成本。
实验结论
本文通过在数据匿名化和内容去毒两个关键任务上进行实验,验证了GDR框架的有效性。
数据匿名化(PII移除)
- 性能超越行业标准:在包含108个PII类别的基准测试中,GDR(使用零样本提示的Gemini Pro 1.5)的F-score达到0.88,远超商业级检测与移除服务(DIRS)的0.52。GDR的召回率高达0.99,而DIRS仅为0.53。
| 召回率 | 精确率 | F-score | |
|---|---|---|---|
| DIRS | 0.53 | 0.52 | 0.52 |
| GDR | 0.99 | 0.80 | 0.88 |
表1:在跨越108个PII类别的2万多个句子上进行PII移除的平均精确率、召回率和F-score。
-
小模型可堪大用:虽然大模型在零样本下表现更好,但通过对一个小的8B模型(Flash 8B)进行监督微调,其PII移除性能超越了未微调的大模型(Gemini Pro 1.5)。这证明了GDR在实践中是成本可行的。
 图2:模型大小对GDR在PII基准测试上精确率和召回率的影响。微调后的Flash 8B(SFT)表现优于更大的Gemini Pro 1.5。
图2:模型大小对GDR在PII基准测试上精确率和召回率的影响。微调后的Flash 8B(SFT)表现优于更大的Gemini Pro 1.5。 -
数据效用得到保留:在一个合成公司信息的问答任务中,使用GDR精炼数据训练的模型 $M^{\prime}$ 能准确回答关于公共信息的问题(准确率0.25),同时完全无法回答关于私有信息的问题(准确率0.00)。相比之下,使用DIRS处理数据的模型 $M_{\text{DIRS}}$ 两者都无法回答(准确率均为0.00),证明GDR在去隐私的同时保留了数据效用。
| $M$ (原始) | $M_{\text{DIRS}}$ | $M^{\prime}$ (GDR) | |
|---|---|---|---|
| 公共信息准确率 $\uparrow$ | 0.32 | 0.00 | 0.25 |
| 私有信息准确率 $\downarrow$ | 0.26 | 0.00 | 0.00 |
表2:在不同数据集上微调的模型对公共和私有事实的回答准确率。
大规模代码匿名化
在包含120万行代码的大型代码数据集上,GDR与人类专家标注的一致性远高于DIRS。特别是在行级别,DIRS的低准确性使其不可靠,而GDR则能精确地识别和重写PII,从而在避免删除大量有用代码的同时完成匿名化。
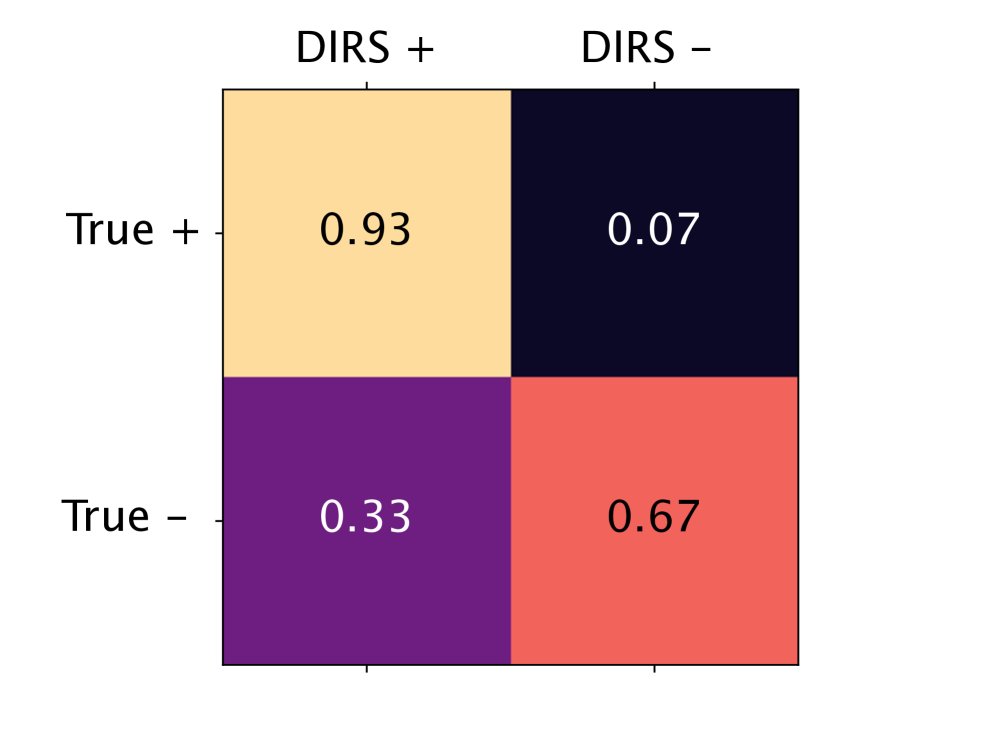
 (a) 代码库级别与专家标签的一致性
(a) 代码库级别与专家标签的一致性
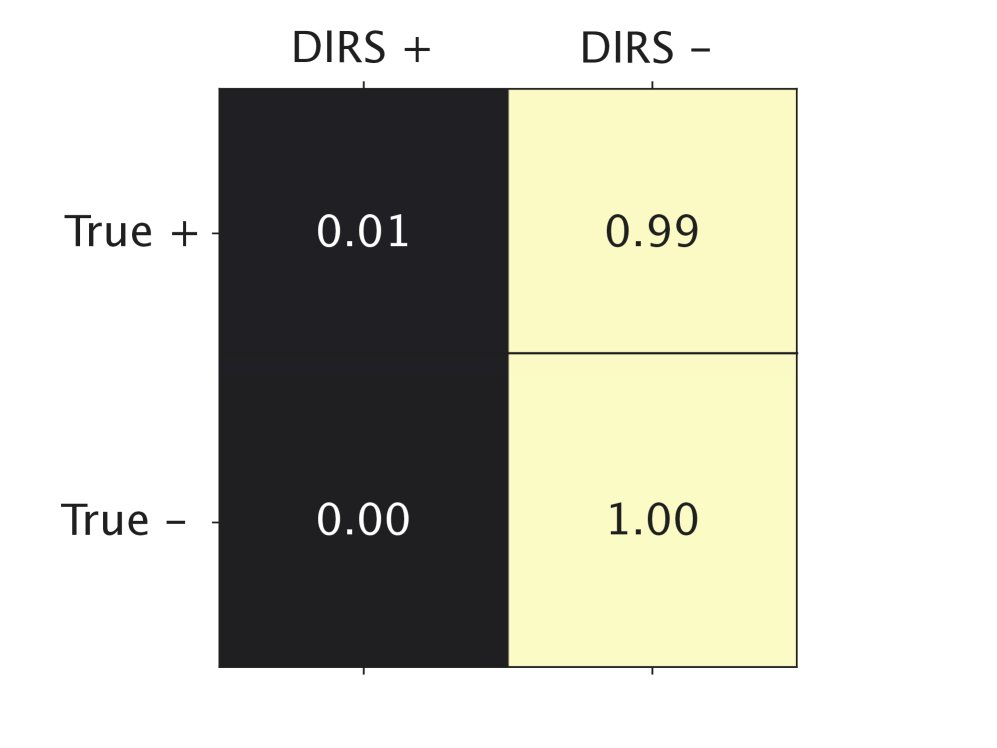
 (b) 行级别与专家标签的一致性
(b) 行级别与专家标签的一致性
图4:DIRS和GDR在479个代码库上的PII标签与专家标签的混淆矩阵。GDR在行级别(b)的真阳性(TP)和真阴性(TN)上表现明显优于DIRS。
内容去毒
-
有效降低毒性:GDR成功地将来自4chan /pol/板块的剧毒数据集(pol100k)的平均毒性分数从0.19降低到0.13,甚至低于基线模型自己生成的合成对话(0.14)。
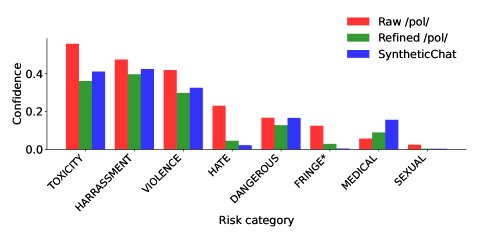 图5:pol100k原始数据集、GDR去毒后数据集以及基线合成对话的毒性分数分布。
图5:pol100k原始数据集、GDR去毒后数据集以及基线合成对话的毒性分数分布。 -
从有毒数据中学习:在去毒后的\(pol100k\)数据集上微调的模型,在一个从原始数据中提取事实构建的问答任务(pol5k-quiz)上准确率从0.88提升到0.92。这表明模型成功地从有毒数据中学习到了有用的世界知识。
数据多样性
与直接生成的合成对话数据(SyntheticChat)相比,GDR精炼后的数据集(Refined pol100k)在多样性指标(L2距离和ROUGE-2分数)上与原始真实数据集(Raw pol100k)相当,并显著优于前者。UMAP可视化清晰地显示,合成数据存在明显的模式坍塌,而GDR精炼后的数据则覆盖了与真实数据相似的广阔空间。
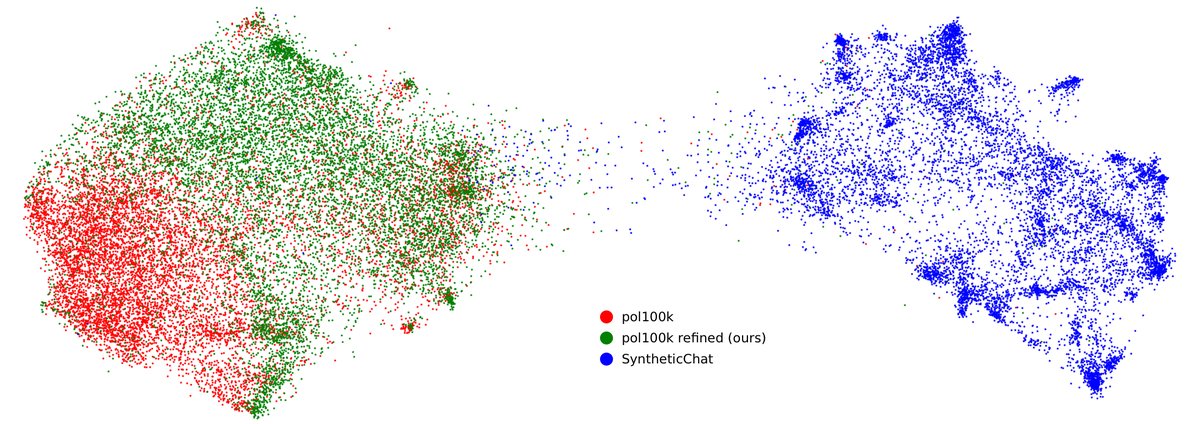 图6:三类数据(合成对话、原始pol100k、GDR精炼后pol100k)各1万样本的Gecko嵌入UMAP可视化。合成数据(Synthetic)形成了密集的簇,表明多样性较低。
图6:三类数据(合成对话、原始pol100k、GDR精炼后pol100k)各1万样本的Gecko嵌入UMAP可视化。合成数据(Synthetic)形成了密集的簇,表明多样性较低。
总结
GDR框架是一个简单而强大的工具,它能有效利用现有的大规模语言模型来清洗和精炼含有不良内容的数据集。通过智能重写而非简单删除,GDR在保护数据安全的同时,最大程度地保留了原始数据的多样性和实用价值,为扩大前沿模型训练数据总量提供了一条极具潜力的途径。