HAD: HAllucination Detection Language Models Based on a Comprehensive Hallucination Taxonomy
-
ArXiv URL: http://arxiv.org/abs/2510.19318v1
-
作者: Wei Zhou; Fan Xu; Xiaojun Wan; Zhenghan Yu; Xinyu Hu; Jinjie Gu; Li Lin; Xu Zhang; Yang Zhang
-
发布机构: Alibaba Group; Fudan University; Peking University
TL;DR
本文提出了一个全面的幻觉分类体系,并基于此构建了一个大规模合成数据集,用以训练 \(HAD\) 模型,使其能够在一个统一的推理过程中完成幻觉分类、范围识别和内容纠正。
关键定义
本文沿用并扩展了现有的关键定义,提出了一个更细致的分类体系。
- 幻觉 (Hallucination):指模型生成的输出看似可信,但实际上在事实层面不正确或与所提供的上下文不符的现象。
- 忠实性幻觉 (Faithfulness Hallucination):源于输入内容与生成内容之间的不一致,或生成内容内部的矛盾,其判断不依赖外部事实信息。
- 事实性幻觉 (Factuality Hallucination):指生成内容包含与外部世界事实不符的不准确、歪曲或捏造的信息。
相关工作
当前,针对大型语言模型(LLM)幻觉的研究取得了显著进展,但仍存在明显局限:
- 评估维度单一:许多研究仅关注事实性(factuality)或忠实性(faithfulness),未能对两者进行综合评估。
- 任务特异性强:现有方法大多针对特定任务(如问答、摘要),导致其通用性受限。
- 分类粒度粗糙:已有的幻觉分类体系粒度较粗,不足以支持跨多种应用场景的详细分析和有效应用。
本文旨在解决上述问题,通过提出一个更全面、细粒度的幻觉分类体系,并开发一个适用于多种自然语言生成(NLG)任务的通用幻觉检测与修正模型。
本文方法
幻觉分类体系
本文提出了一个三层级的幻觉分类体系,包含11个细粒度类别,全面覆盖了忠实性和事实性两个维度。该体系是对现有研究的综合与扩展。
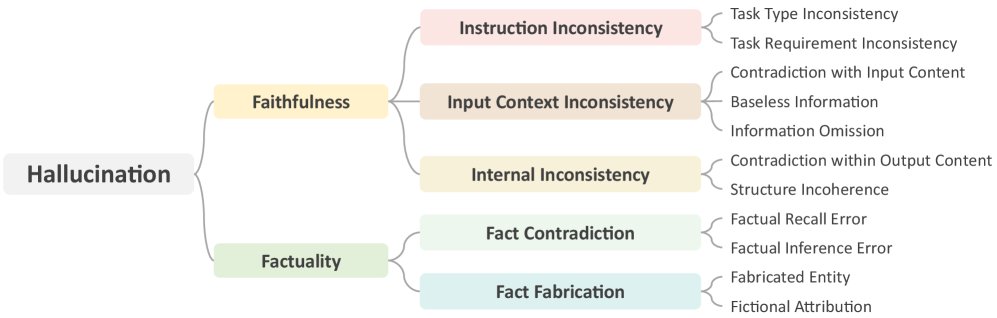
忠实性幻觉 (Faithfulness Hallucination)
这类幻觉源于生成内容与输入(指令、上下文)或其内部的不一致。
- A. 指令不一致 (Instruction Inconsistency)
- 任务类型错误 (Task Type Error):输出的任务类型与指令要求不符。
- 任务要求不一致 (Task Requirement Inconsistency):输出未满足指令中的具体要求(如格式、长度、主题等)。
- B. 输入上下文不一致 (Input Context Inconsistency)
- 上下文矛盾 (Context Contradiction):输出与输入上下文中的信息相矛盾。
- 上下文外信息 (Extrinsic Information):在要求严格遵循上下文的任务中,输出了上下文中未包含的信息。
- 上下文遗漏 (Context Omission):输出遗漏了输入上下文中的关键细节。
- C. 内部不一致 (Internal Inconsistency)
- 逻辑错误 (Logical Error):输出包含自相矛盾的陈述或错误的推理。
- 不连贯 (Incoherence):输出包含冗余、重复或不连贯的语句。
事实性幻觉 (Factuality Hallucination)
这类幻觉指生成内容与外部世界知识不符。
- D. 事实矛盾 (Fact Contradiction)
- 事实回忆错误 (Factual Recall Error):输出包含错误的原子事实。
- 事实推断错误 (Factual Inference Error):对事实的解释不完整或存在误解,如混淆时间、人物,或颠倒因果。
- E. 事实捏造 (Fact Fabrication)
- 实体捏造 (Fabricated Entity):凭空捏造现实世界不存在的实体(如概念、人名)。
- 主张捏造 (Fabricated Claim):对真实实体捏造无法通过可靠来源证实或证伪的信息。
数据构建
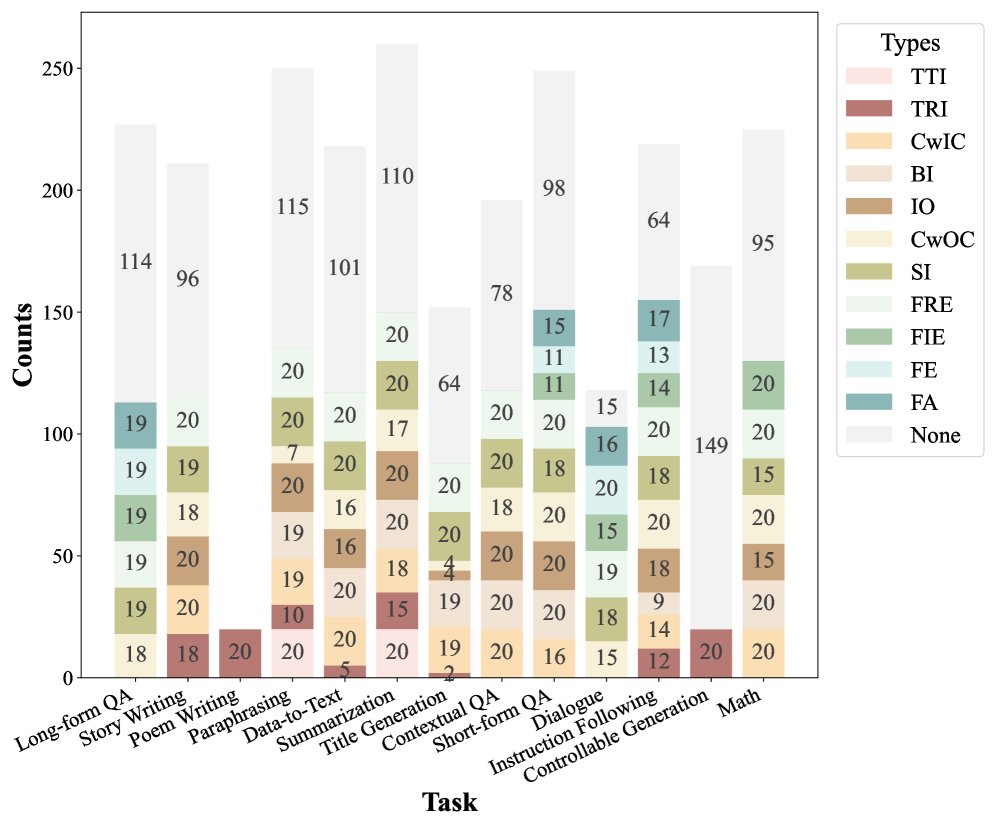
为了训练一个能识别上述11种幻觉类型的多任务模型,本文构建了一个大规模的合成数据集。
创新点
本文方法的创新之处在于三位一体的设计:
- 细粒度分类驱动:首先定义了一个全面的幻觉分类体系,作为数据构建和模型训练的理论基础。
- 大规模多任务数据合成:基于该体系,通过\(GPT-4o\)对多种NLG任务的正确数据进行“幻觉注入”,并经过自动过滤,生成了约9万条包含幻觉类型、幻觉范围(span)和修正参考的高质量训练样本。
- 统一的多功能模型:训练出的\(HAD\)模型能在一个统一的推理流程中,同时完成幻觉分类、范围识别和内容纠正三项任务,具备跨任务的通用性。
数据源与合成流程
- 源数据:为保证多样性,从多种NLG任务中选取数据,包括长文本问答(ELI5)、故事/诗歌写作、摘要(SNI)、数学推理(GSM8K)等。
- 幻觉注入:使用\(GPT-4o\)根据预设的幻觉类型定义和3-shot示例,对原始正确输出进行修改,以注入特定类型的幻觉。
- 自动过滤与测试集标注:再次使用\(GPT-4o\)根据一系列标准对生成的幻觉数据进行验证和过滤,以确保质量。此外,通过专家手动标注和修正,构建了一个包含2,248个样本的高质量测试集\(HADTest\)。
HAD模型
- 基础模型:主要基于\(Llama3-8B-Instruct\)进行微调,同时也实验了\(Llama3-7B-Instruct\)和\(DeepSeek-Coder-V2-Lite-16B\)等不同尺寸和架构的模型,形成了\(HAD-7B\)、\(HAD-8B\)和\(HAD-14B\)系列。
- 训练范式:采用监督式微调(supervised fine-tuning),将幻觉分类、范围识别和纠正统一到一个生成任务中。模型输入包含任务指令、上下文和待检测的输出,模型需要生成结构化的结果,指明幻觉类型(或无幻觉)、幻觉的具体文本范围以及修正后的文本。
- 优点:与现有方法相比,\(HAD\)模型不仅能判断有无幻觉,还能提供细粒度的类别和精确位置,并给出修正建议,功能更全面。其基于多样化数据集的训练使其具备了跨不同NLG任务的泛化能力。
实验结论
关键结果
\(HAD\)模型在域内和域外测试中均表现出色,通常优于现有的基线模型。
域内测试 (In-Domain Evaluation on HADTest): 如下表所示,\(HAD-14B\)在所有子任务上均取得了最佳性能,包括二元分类准确率(89.10%)、细粒度分类F1值(77.38%)、幻觉范围识别F1值(76.01%)和内容纠正F1值(77.97%),显著超越了\(GPT-4o\)等通用大模型。
| 模型 | 二元分类准确率 | 细粒度分类准确率 | 细粒度分类精确率 | 细粒度分类召回率 | 细粒度分类F1 | 范围识别精确率 | 范围识别召回率 | 范围识别F1 | 纠正精确率 | 纠正召回率 | 纠正F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FAVA-Model | 59.43 | - | - | - | 34.69 | 50.35 | 36.56 | 70.84 | 65.41 | 66.29 | |
| GPT-4o | 63.08 | 40.30 | 46.61 | 41.64 | 56.41 | 73.03 | 57.79 | 63.22 | 68.93 | 62.90 | |
| GPT-4o mini | 60.19 | 29.76 | 32.00 | 29.37 | 48.00 | 59.03 | 46.91 | 57.99 | 65.17 | 58.81 | |
| DeepSeek-V3 | 58.50 | 39.72 | 38.48 | 38.47 | 46.58 | 60.45 | 48.15 | 40.41 | 63.23 | 45.37 | |
| HAD-7B | 87.46 | 81.76 | 76.09 | 75.17 | 76.50 | 74.08 | 72.52 | 74.90 | 74.41 | 74.05 | |
| HAD-8B | 86.12 | 79.72 | 76.99 | 74.09 | 78.73 | 77.07 | 75.21 | 79.03 | 78.60 | 78.29 | |
| HAD-14B | 89.10 | 83.05 | 77.38 | 77.62 | 78.96 | 78.27 | 76.01 | 78.87 | 78.16 | 77.97 | |
| HAD-14B-Binary | 87.77 | - | - | - | 83.48 | 85.39 | 82.25 | 86.29 | 85.57 | 84.97 |
域外测试 (Out-of-Domain Evaluation): 如下表所示,\(HAD\)模型在\(HaluEval\)、\(FactCHD\)、\(FaithBench\)等多个公开基准测试上取得了SOTA或具有竞争力的结果,展示了其强大的泛化能力和鲁棒性。值得注意的是,专门用于二元分类的\(HAD-14B-Binary\)在某些任务上表现优于多任务的\(HAD-14B\),揭示了功能全面性与单一任务精度之间的权衡。
| 模型 | HaluEval-QA | HaluEval-Dialogue | HaluEval-Sum | HaluEval-General | FactCHD (P-Acc) | FaithBench (Acc) | FaithBench (F1) |
|---|---|---|---|---|---|---|---|
| SelfCheckGPT | 48.20 | 21.30 | 36.30 | 49.70 | 54.54 | 50.00 | 41.26 |
| LYNX 8B | 60.25 | 74.48 | 85.70* | 68.45 | 44.88 | 56.71 | 44.36 |
| ANAH-v2 | 73.13 | 77.50 | 81.33 | 64.92 | - | - | |
| FAVA-Model | 57.82 | 73.37 | 62.16 | 50.42 | 44.62 | 53.18 | 41.64 |
| HHEM-2.1-Open | - | - | - | 37.86 | - | 55.68* | 40.86* |
| GPT-4o | 73.55 | 81.30 | 86.33 | 71.43 | 51.89 | 56.29* | 40.75* |
| GPT-4o mini | 71.71 | 81.18 | 84.04 | 69.80 | 39.20 | 52.13 | 35.29 |
| DeepSeek-V3 | 77.85 | 85.80 | 50.73 | 72.09 | 62.98 | 52.94 | 32.79 |
| HAD-7B | 82.24 | 78.41 | 83.63 | 81.54 | 63.68 | 44.63 | 44.30 |
| HAD-8B | 82.35 | 75.40 | 81.40 | 76.55 | 64.16 | 55.46 | 55.55 |
| HAD-14B | 82.33 | 79.94 | 86.65 | 81.36 | 65.00 | 51.85 | 45.45 |
| HAD-14B-Binary | 82.16 | 76.55 | 86.43 | 83.18 | 60.18 | 57.73 | 57.81 |
错误分析
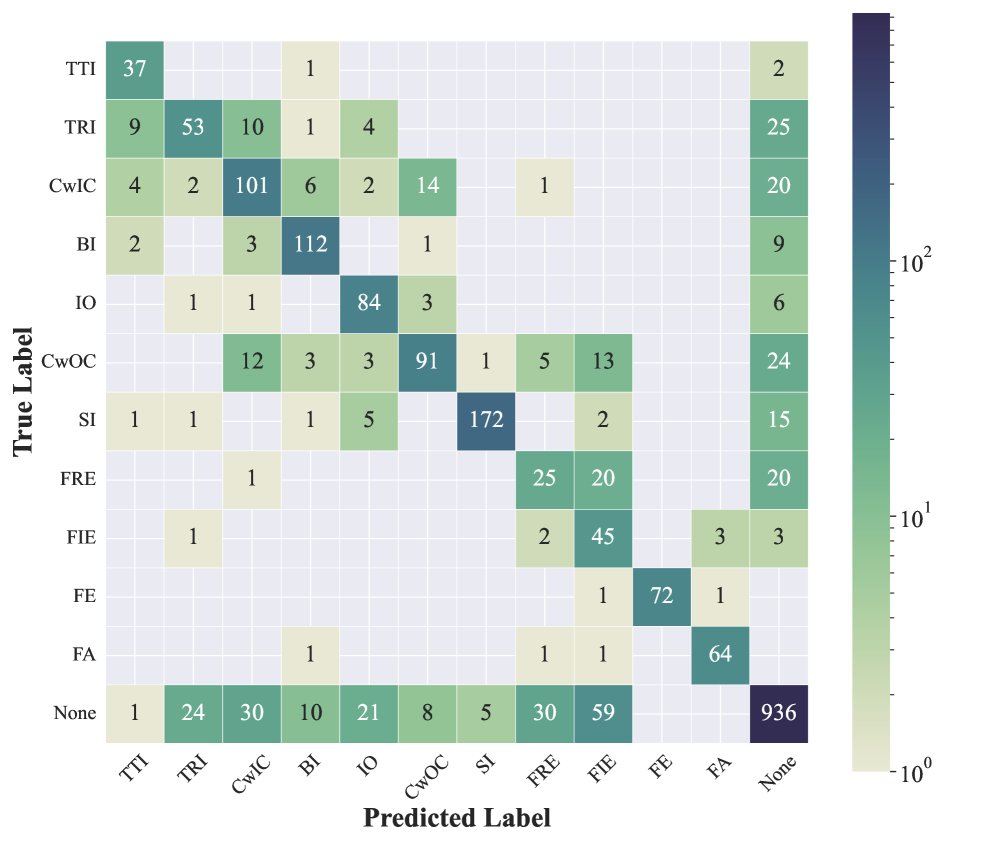
- 知识依赖性:混淆矩阵显示,模型在处理“事实回忆错误”和“事实推断错误”这类与事实性相关的幻觉时表现较差,F1分数较低,这主要是因为模型自身知识库的局限性。
- 类别混淆:模型在区分相似的幻觉类别时存在困难,例如“实体捏造”和“主张捏造”。
- 任务泛化挑战:在\(HaluEval-general\)数据集上表现不佳,表明模型在应对更广泛、更多样化的任务类型和由真实LLM生成的响应时仍有提升空间。
知识增强
为了弥补模型内在知识的不足,本文尝试了知识增强方法,即在输入中加入通过检索模型从维基百科中检索到的相关背景知识。
| F1分数 | 事实回忆错误 | 事实推断错误 | 实体捏造 | 主张捏造 |
|---|---|---|---|---|
| HAD-14B | 35.90 | 26.87 | 81.48 | 70.48 |
| +知识 | 37.84 | 52.17 | 97.99 | 87.88 |
实验结果表明,引入外部知识能显著提升对事实性幻觉的检测能力,尤其在需要关联多个事实进行推断的“事实推断错误”类别上,改进最为明显。
最终结论
本文成功地开发了一套名为\(HAD\)的幻觉检测模型。通过构建一个全面细粒度的幻觉分类体系,并在此基础上合成大规模、多样化的训练数据,\(HAD\)模型实现了在单一推理过程中对幻觉进行分类、定位和修正。实验证明,该方法不仅在特定测试集上表现优异,还在多个域外基准上展现了出色的泛化能力和鲁棒性,为构建更可靠、更值得信赖的AI系统提供了有效的工具。