Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
-
ArXiv URL: http://arxiv.org/abs/2304.13712v2
-
作者: Bing Yin; Qizhang Feng; Ruixiang Tang; Xia Hu; Haoming Jiang; Jingfeng Yang; Xiaotian Han; Hongye Jin
-
发布机构: Amazon; Rice University; Texas A&M University
TL;DR
本文是一份面向实践者和终端用户的综合性实践指南,围绕模型、数据和下游任务三个维度,深入探讨了如何有效利用大型语言模型(LLMs)解决自然语言处理(NLP)问题,并详细剖析了不同场景下选择LLMs或微调模型的利弊。
模型实用指南
本节首先对现代语言模型的发展历程进行了概述和观察,然后将其主要分为两大类:BERT风格(编码器-解码器或仅编码器)和GPT风格(仅解码器)。
 图1. 现代LLMs的演化树。它追溯了近年来语言模型的发展,并突出了一些最知名的模型。同一分支上的模型关系更近。基于Transformer的模型以非灰色显示:蓝色分支为仅解码器模型,粉色分支为仅编码器模型,绿色分支为编码器-解码器模型。模型在时间轴上的垂直位置代表其发布日期。开源模型用实心方块表示,闭源模型用空心方块表示。右下角的堆叠条形图显示了来自不同公司和机构的模型数量。
图1. 现代LLMs的演化树。它追溯了近年来语言模型的发展,并突出了一些最知名的模型。同一分支上的模型关系更近。基于Transformer的模型以非灰色显示:蓝色分支为仅解码器模型,粉色分支为仅编码器模型,绿色分支为编码器-解码器模型。模型在时间轴上的垂直位置代表其发布日期。开源模型用实心方块表示,闭源模型用空心方块表示。右下角的堆叠条形图显示了来自不同公司和机构的模型数量。
从图1的演化树中,可以观察到以下趋势: a) 仅解码器(Decoder-only)模型逐渐主导LLMs的发展:早期,这类模型不及编码器-解码器或仅编码器模型流行。但自2021年GPT-3问世后,仅解码器模型迎来爆发式增长,而以BERT为代表的仅编码器模型则逐渐式微。
b) OpenAI在LLM领域保持领先:无论是过去还是现在,OpenAI在开发与GPT-3及GPT-4相媲美的模型方面始终处于领导地位,其他机构难以追赶。
c) Meta对开源LLM贡献卓著:Meta是商业公司中对开源社区最慷慨的贡献者之一,其开发的所有LLM均已开源。
d) LLM呈现闭源趋势:在2020年之前,大多数LLM是开源的。但自GPT-3之后,公司越来越倾向于闭源其模型(如PaLM, LaMDA, GPT-4),这增加了学术界进行模型训练研究的难度,基于API的研究可能成为主流。
e) 编码器-解码器模型仍有潜力:尽管仅解码器模型因其灵活性和通用性看似更有前景,但编码器-解码器架构仍在被积极探索,且其中多数是开源的。
下表总结了这两类模型的特点和代表模型。
| 特点 | 代表性LLMs | ||
|---|---|---|---|
| 编码器-解码器或仅编码器 (BERT风格) | 训练 模型类型 预训练任务 | 掩码语言模型 (Masked Language Models) 判别式 (Discriminative) 预测被掩码的词 | ELMo, BERT, RoBERTa, DistilBERT, BioBERT, XLM, XLNet, ALBERT, ELECTRA, T5, GLM, XLM-E, ST-MoE, AlexaTM |
| 仅解码器 (GPT风格) | 训练 模型类型 预训练任务 | 自回归语言模型 (Autoregressive Language Models) 生成式 (Generative) 预测下一个词 | GPT-3, OPT, PaLM, BLOOM, MT-NLG, GLaM, Gopher, Chinchilla, LaMDA, GPT-J, LLaMA, GPT-4, BloombergGPT |
BERT风格语言模型:编码器-解码器或仅编码器
这类模型的核心训练范式是掩码语言模型(Masked Language Model),即在输入句子中掩盖一部分词,然后让模型根据上下文预测这些被掩盖的词。这种方式使模型能深入理解词与词之间以及词与上下文之间的关系。这类模型,如BERT、RoBERTa和T5,在许多NLP任务(如情感分析、命名实体识别)上取得了SOTA(State-of-the-art)成果。
GPT风格语言模型:仅解码器
这类模型通常是自回归语言模型(Autoregressive Language Models),其训练方式是根据前面的词序列来预测下一个词。研究发现,大幅扩展这类模型的规模能显著提升其在少样本(few-shot)甚至零样本(zero-shot)场景下的性能。以GPT-3为代表的模型通过提示(prompting)和上下文学习(in-context learning)展现了卓越的少样本/零样本能力。近期的突破是ChatGPT,它在GPT-3的基础上针对对话任务进行了优化,实现了更具交互性、连贯性和上下文感知能力的对话。
数据实用指南
数据在模型选择和性能中扮演着至关重要的角色,其影响贯穿预训练、微调和推理(inference)的全过程。
核心观点 1
(1) 在面临分布外数据(out-of-distribution, OOD),如对抗样本和领域偏移时,LLMs比微调模型具有更好的泛化能力。
(2) 当标注数据有限时,LLMs是更优选择;当标注数据充足时,两者皆可,具体取决于任务需求。
(3) 建议选择那些在与下游任务相似领域数据上进行过预训练的模型。
预训练数据
预训练数据的质量、数量和多样性是LLMs强大能力的基础,对模型性能有决定性影响。预训练数据通常包含书籍、文章、网站等海量文本,旨在为模型灌输丰富的词汇知识、语法、句法、语义以及常识。数据的多样性也至关重要,例如,PaLM和BLOOM因包含大量多语言数据而在多语言任务和机器翻译上表现出色;GPT-3.5因包含代码数据而在代码生成方面能力突出。因此,选择LLM时,应优先考虑其预训练数据与下游任务的相似性。
微调数据
根据可用标注数据的数量,可以分为三种场景:
- 零标注数据 (Zero annotated data):在此情况下,直接使用LLMs的零样本能力是最佳选择。LLMs在零样本设置下通常优于传统的零样本方法,并且由于不更新模型参数,可以避免灾难性遗忘(catastrophic forgetting)。
- 少量标注数据 (Few annotated data):LLMs的上下文学习(in-context learning)能力此时表现突出。通过在输入提示中加入少量示例,LLMs能够有效地泛化到新任务,其性能甚至能媲美经过微调的SOTA模型。相比之下,传统的少样本学习方法(如元学习)应用于小模型时,可能因模型规模和过拟合问题而表现不佳。
- 充足标注数据 (Abundant annotated data):当有大量标注数据时,微调小模型和使用LLMs都是可行的。微调模型通常能很好地拟合数据,而LLM则可能在满足特定约束(如隐私保护)时更有优势。此时的选择需综合考虑性能、计算资源和部署限制。
总结而言,LLMs在数据可用性方面更具通用性,而微调模型在有充足标注数据时是一个可靠选项。
测试/用户数据
在实际部署中,测试数据与训练数据之间常存在分布差异,如领域偏移(domain shifts)、分布外变异(out-of-distribution variations)或对抗性样本(adversarial examples)。精调模型由于拟合了特定数据分布,在面对这些挑战时泛化能力较差。而LLMs因其未经过显式的拟合过程,表现出更强的鲁棒性。特别是经过人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)训练的LLMs(如InstructGPT和ChatGPT),其泛化能力得到显著增强,在多数对抗性和OOD任务上表现优越。
NLP 任务实用指南
本节详细探讨LLMs在各类NLP下游任务中的适用与不适用场景。下图提供了一个决策流程,可作为快速选择模型的参考。
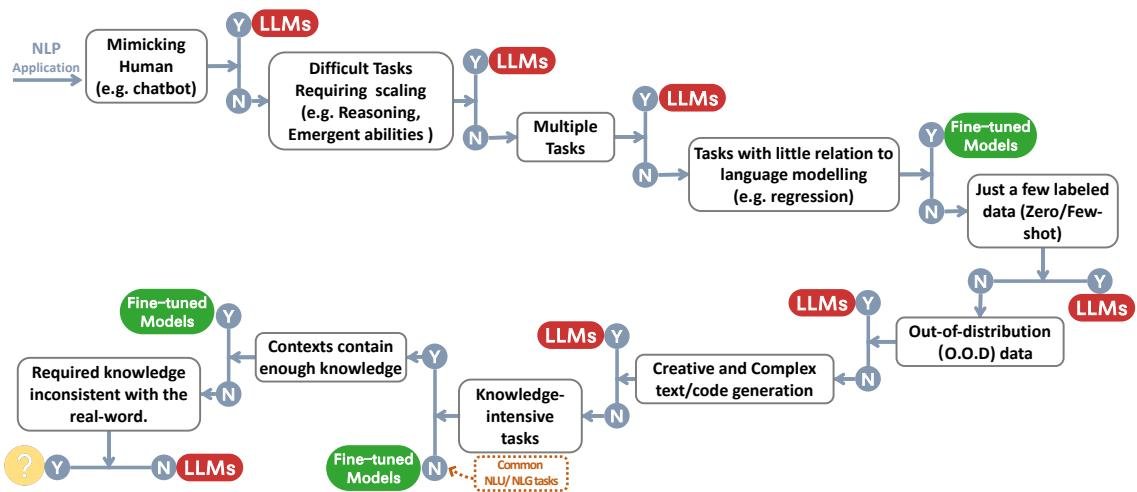
传统NLU任务
传统自然语言理解(Natural Language Understanding, NLU)任务包括文本分类、命名实体识别(NER)、文本蕴含等,通常作为更大型AI系统的中间步骤。
核心观点 2
在传统NLU任务中,微调模型通常是更好的选择,但当需要强泛化能力时,LLMs可以提供帮助。
- 不适用场景 (No use case):在大多数有充足、高质量标注数据且测试集分布内外差异不大的NLU基准(如GLUE, SuperGLUE)上,微调模型的性能通常优于LLMs。
- 文本分类:在多数数据集上,LLMs略逊于微调模型。尤其在毒性检测任务上,差距非常大,LLMs表现不佳,而基于BERT的微调模型(如Perspective API)效果更好。
- 自然语言推断 (NLI) 和 问答 (QA):在多数数据集上,微调模型表现更优。
- 信息检索 (IR):LLMs尚未被广泛应用,因为难以将大量候选文本转换成其擅长的少样本/零样本格式。
- 底层中间任务 (NER、依存句法分析):根据现有评估,LLMs在这些任务上(如CoNLL03 NER)的性能远不及微调模型。
- 适用场景 (Use case):当任务需要极强的泛化能力时,LLMs的优势凸显。
- 杂项文本分类:对于主题多样、关系不明确、难以格式化的真实世界分类任务,LLMs表现更好。
- 对抗性NLI (ANLI):这是一个通过对抗性挖掘构建的困难数据集,LLMs在其上表现出优越的性能。
- 这些例子都证明了LLMs在处理分布外数据和稀疏标注数据时的卓越泛化能力。
生成任务
自然语言生成(Natural Language Generation, NLG)任务主要分为两类:一是将输入文本转换为新的符号序列(如摘要、翻译),二是从零开始“开放式”生成文本(如写邮件、故事、代码)。
核心观点 3
凭借强大的生成能力和创造力,LLMs在大多数生成任务中表现出优越性。
- 适用场景 (Use case):
- 摘要任务:尽管在ROUGE等自动评估指标上不占优,但在人工评估中,LLMs生成的摘要在忠实度、连贯性和相关性方面更受青睐。
- 机器翻译 (MT):LLMs在将低资源语言翻译成英语方面表现出色,这得益于其预训练数据中大量的英语语料。多语言预训练模型(如BLOOM)在更广泛的语言对上表现良好。
- 开放式生成:LLMs在生成新闻文章、小说和代码方面能力非凡。例如,GPT-4能够解决相当一部分有难度的LeetCode编程问题。
- 不适用场景 (No use case):在大多数高资源和极低资源的翻译任务中,专门微调的模型(如DeltaLM+Zcode)性能仍然最佳。
知识密集型任务
这类任务高度依赖背景知识、领域专业知识或世界常识,超越了简单的模式识别。
核心观点 4
(1) 由于储存了海量的真实世界知识,LLMs在知识密集型任务上表现出色。
(2) 当任务所需的知识与模型学到的知识不匹配,或任务仅需上下文知识时,LLMs表现不佳,此时微调模型同样有效。
- 适用场景 (Use case):
- 闭卷问答:在需要模型记忆事实性知识的任务(如NaturalQuestions, TriviaQA)中,LLMs表现远超微调模型。
- 大规模多任务语言理解 (MMLU):这是一个涵盖57个学科、需要广泛知识的挑战性基准,新发布的GPT-4在此任务上取得了SOTA性能。
- Big-bench中的部分任务:在一些需要特定领域知识(如印度神话、元素周期表)的任务上,LLMs的性能甚至超越了人类平均水平。
- 不适用场景 (No use case):
- 仅需上下文知识的任务:如机器阅读理解(Machine Reading Comprehension, MRC),模型只需理解给定段落即可回答问题,小型的微调模型同样能胜任。
- 知识与模型储备相悖的任务:当任务要求与模型已有的世界知识相悖或无关时(如Big-Bench中的“ASCII艺术数字识别”或“数学符号重定义”任务),LLMs表现很差,甚至不如随机猜测。
- 可使用检索增强的场景:通过检索增强(retrieval augmentation),让模型可以访问外部知识库。在这种“开卷”模式下,小型的微调模型结合检索器,其性能可以超过不带检索的LLMs。
与规模化相关的能力
模型规模(如参数量、计算量)的扩展极大地增强了语言模型的能力。某些能力,如推理,随着模型规模的扩大,从几乎不可用状态演变为接近人类水平。
核心观点 5
(1) 随着模型规模的指数级增长,LLMs在算术推理和常识推理等方面的能力尤为突出。
(2) 随着LLMs规模扩大,会涌现出一些意外的能力,如词语操纵和逻辑能力,这为应用带来惊喜。
(3) 由于对LLMs能力如何随规模变化的理解有限,在许多情况下,性能并非随着规模的扩大而稳定提升。
- 适用场景:推理
- 算术推理/问题解决:LLMs的算术推理能力随规模增长显著提升。在GSM8k等数据集上,作为通用模型,LLMs的性能已能与专用模型竞争,GPT-4更是超越了所有其他方法。配合思维链(Chain-of-Thought, CoT)提示,其计算能力还能进一步提升。
- 常识推理:LLMs的常识推理能力同样随规模稳步增长,在StrategyQA等数据集上优于微调模型。在ARC-C(中小学科学问题)上,GPT-4的准确率已接近100%。
- 适用场景:涌现能力 (Emergent Abilities) 涌现能力指那些在小模型上不存在,只有当模型规模超过某个阈值后才突然出现的能力。这些能力无法通过小模型的性能外推来预测。
- 词语操纵:如颠倒词语拼写、词语排序和字母重组。
- 逻辑能力:如逻辑推导、逻辑序列和逻辑网格谜题。
- 其他:高级编码(如自动调试)、概念理解等。
- 不适用场景及理解
- 逆规模现象 (Inverse Scaling Phenomenon):在某些任务上,模型性能随规模增大反而下降。例如,在要求模型处理被重新定义的数学符号的任务(Redefine-math)中,LLMs表现很差。
- U型现象 (U-shaped Phenomenon):在另一些任务上,性能随规模增大先下降后上升。例如,在评估模型是否会忽略事后信息的任务(Hindsight-neglect)中观察到此现象。
- 这些现象的成因仍在探索中,可能与模型过度依赖先验知识、评估指标的粒度以及任务内在的复杂性有关。这提示我们在选择模型时,并非总是越大越好。
其他杂项任务
本节探讨之前未覆盖的其他任务,以更全面地理解LLMs的优劣。
核心观点 6
(1) 在与LLMs预训练目标和数据差异较大的任务中,微调模型或专用模型仍有其用武之地。
(2) LLMs是出色的人类模仿者、数据标注员和生成器。它们还可用于NLP任务的质量评估,并带来可解释性等额外好处。
- 不适用场景 (No use case):
- 回归任务:LLMs在预测连续值的回归任务(如GLUE STS-B)上表现不佳,逊于微调的RoBERTa模型。这主要是因为其语言建模的预训练目标与回归任务的目标不匹配。
- 多模态任务:LLMs主要在文本数据上训练,处理包含图像、音频、视频等多模态数据的任务能力有限。目前,BEiT、PaLI等微调的多模态模型在视觉问答(VQA)、图像描述等领域仍占主导地位。
- 适用场景 (Use case):
- 模仿人类与对话:以ChatGPT为代表的LLMs在模仿人类对话方面表现出色,能进行连贯、可靠、信息丰富的多轮交流。
- 数据标注与生成:LLMs可作为高质量的标注员和数据增强的生成器,其生成的数据甚至被用来训练其他模型。
- 质量评估:LLMs可作为NLG任务(如摘要、翻译)的评估器,其评估结果与人类判断的相关性很高,但可能存在偏爱LLM生成文本的偏见。
- 额外优势:LLMs的某些能力带来了额外的好处,如思维链(CoT)推理过程为模型预测提供了实例级别的可解释性。
真实世界“任务”
真实世界的“任务”通常没有学术界那样明确的定义,用户输入可能充满噪声,任务类型多样且模糊。
核心观点 7
与微调模型相比,LLMs更适合处理真实世界的场景。然而,如何有效评估模型在真实世界中的表现仍是一个开放问题。
真实世界场景的挑战主要来自:
- 噪声/非结构化输入:用户输入可能包含拼写错误、口语、混合语言。
- 非标准化的任务:用户请求通常不属于预定义的NLP任务类别,甚至一个请求包含多个任务。
- 遵循复杂指令:用户指令可能包含隐式意图,需要模型理解上下文并做出恰当回应。
LLMs因其在多样化数据上的训练,具备更强的开放域响应能力和对模糊、噪声输入的处理能力,因此比专门针对特定任务的微调模型更适合应对这些挑战。指令微调(instruction tuning)和人类对齐微调(human alignment tuning)等技术进一步增强了LLMs理解和遵循用户指令的能力。评估模型在真实世界中的有效性非常困难,主要依赖昂贵的人工评估,这也是一个重要的研究方向。
其他考量因素
尽管LLMs在各种下游任务中表现强大,但在实际应用中还需考虑其他因素,如效率、成本和延迟等。