HEAL: A Hypothesis-Based Preference-Aware Analysis Framework
-
ArXiv URL: http://arxiv.org/abs/2508.19922v1
-
作者: Chenglong Wang; Yifu Huo; Chunliang Zhang; Tong Xiao; Tongran Liu
-
发布机构: Chinese Academy of Sciences; NiuTrans Research; Northeastern University
TL;DR
本文提出了一个名为HEAL的新型评估框架,它将大语言模型的偏好对齐问题重新定义为在“假设空间”内的重排序过程,并通过排序准确性和偏好强度相关性两个新指标,更全面地分析现有偏好学习方法。
关键定义
本文提出或沿用了以下几个对理解论文至关重要的核心概念:
- 假设空间 (Hypothesis Space): 对于给定的输入提示 $x$,模型可能生成的所有响应(即假设)构成的集合 $Y_x$。这个空间中的响应根据一个指示函数 $\mathbf{I}(x,y)$(如模型的生成概率 $\pi_\theta(y \mid x)$ 或偏好分数)进行排序。
- 黄金标准假设空间 (Gold-Standard Hypothesis Space): 一个理论上最优的假设空间 $Y_{\mathrm{x;gold}}$,其排序由一个黄金标准评分函数 $\mathrm{GS}(x,y)$(如来自强大奖励模型或人类的评分)决定。它代表了偏好对齐的理想目标。
-
排序准确性 (Ranking Accuracy, RA): 本文提出的第一个核心度量,用于评估模型的排序与黄金标准排序的一致性。它通过计算两个假设空间排序的肯德尔相关系数 (Kendall’s Tau-b),并将其映射到 $[0, 1]$ 区间,公式为:
\[\mathrm{RA}(\mathcal{D})=\mathbb{E}_{(x,Y_{x}^{(1)},Y_{x}^{(2)})\sim\mathcal{D}}\frac{\tau_{b}(Y_{x}^{(1)},Y_{x}^{(2)})+1}{2}\]RA衡量模型是否能正确理解响应之间的相对好坏顺序。
-
偏好强度相关性 (Preference Strength Correlation, PSC): 本文提出的第二个核心度量,用于评估模型对偏好强度(即好坏程度)的捕捉能力。它通过计算模型生成响应的对数似然与黄金标准偏好分数之间的皮尔逊相关系数 (Pearson Correlation) 来实现,公式为:
\[\mathrm{PSC}(\mathcal{D})=\mathbb{E}_{(x,Y_{x}^{(1)},Y_{x}^{(2)})\sim\mathcal{D}}\left[\frac{\mathbb{E}[I_{1}I_{2}]-\mathbb{E}[I_{1}]\mathbb{E}[I_{2}]}{\sigma_{I_{1}}\sigma_{I_{2}}}\right]\]PSC衡量模型是否能区分“好”与“非常好”之间的细微差别。
相关工作
目前,直接偏好优化 (Direct Preference Optimization, DPO) 及其变种已成为对齐大语言模型(LLMs)的主流方法。对这些方法的评估通常依赖于AlpacaEval、MT-Bench等基准,其标准流程是:模型生成单个响应,然后由一个代理模型(如GPT-4)将其与参考响应进行比较。
这种评估范式存在根本局限性:
- 评估片面: 它只考察模型生成的单个样本,忽略了在真实应用中可能出现的各种潜在输出,无法全面评估模型的偏好对齐情况。
- 忽略相对比较: 它忽视了对多个候选响应进行相对排序的评估,而这正是偏好学习的核心建模场景。
因此,本文旨在解决当前评估方法的局限性,提出一个能对模型在整个假设输出空间中的偏好表现进行全面、量化分析的新框架。
本文方法
本文提出了HEAL (Hypothesis-based PrEference-aware AnaLysis),一个基于假设的、关注偏好的分析框架。
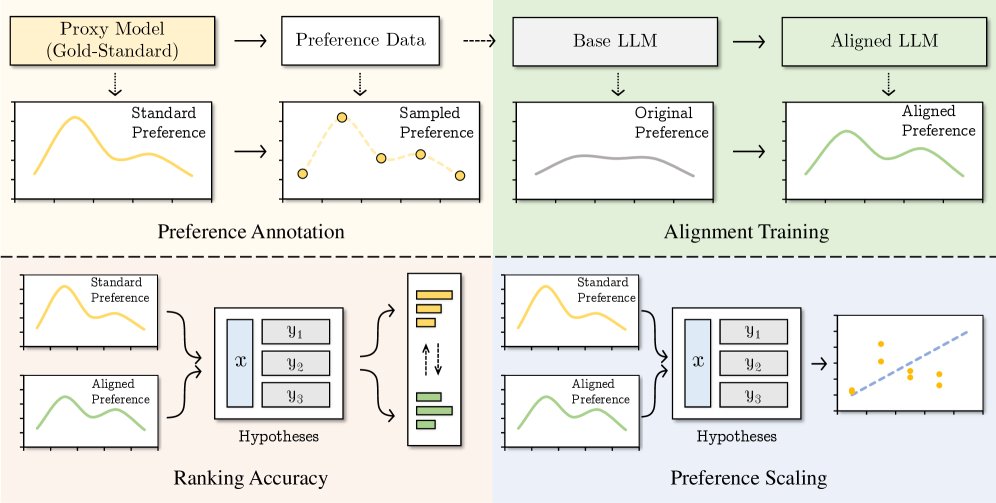
创新点
HEAL的核心创新在于将偏好学习的评估范式从“单点生成评估”转变为“假设空间重排序评估”。它不再关注模型“生成了什么”,而是关注模型“如何看待所有可能的输出”。
其工作流程如下:
- 构建假设空间:对于一个给定的提示,收集多个不同的可能响应,构成一个假设集合。
- 双重排序:
- 模型排序: 使用被评估的LLM计算每个响应的生成似然,并据此对假设集合进行排序,得到模型的“假设空间”。
- 黄金标准排序: 使用一个代理模型(如强大的奖励模型)或人类标注者为每个响应打分,并据此排序,得到“黄金标准假设空间”。
- 量化对比:通过两个互补的度量来量化模型排序与黄金标准排序之间的差距:
- 排序准确性 (RA): 衡量序数一致性。即模型的排序与黄金标准的排序在多大程度上是一致的。高RA意味着模型理解了哪个响应更好。
- 偏好强度相关性 (PSC): 衡量连续对齐精度。即模型的生成似然(代表其偏好强度)是否与黄金标准分数呈线性相关。高PSC意味着模型不仅知道哪个更好,还知道好多少。
优点
- 全面性: 通过考察整个假设空间而非单个样本,HEAL能更全面、稳定地评估模型的偏好对齐能力。
- 诊断性: RA和PSC两个指标提供了强大的诊断工具。例如,一个模型可能RA很高但PSC很低,这表明它能正确排序,但无法感知偏好的细微强度差异。
- 灵活性: HEAL框架可以灵活地集成不同的黄金标准来源,包括生成模型、奖励模型和人类反馈,形成统一的评估体系。
为了支持该框架,本文还构建了一个统一的假设基准 UniHypoBench,该基准为每个指令提供了多个(>8个)来自不同模型的响应,为进行全面的假设空间分析提供了数据基础。
实验结论
本文使用HEAL框架对DPO、SimPO、ORPO等主流偏好优化方法进行了深入评估。
关键实验结果
| 模型/方法 | 对齐ArmoRM (同分布) | 对齐GRM (异分布) | | :— | :— | :— | | LLaMA-3-8B-Instruct | RA: 54.15, PSC: 0.124 | RA: 51.68, PSC: 0.056 | | +DPO | RA: 54.16, PSC: 0.138 | RA: 51.29, PSC: 0.049 | | +ORPO | RA: 52.67, PSC: 0.084 | RA: 51.56, PSC: 0.053 | | +SimPO | RA: 63.59, PSC: 0.502 | RA: 49.50, PSC: -0.031 | 注:上表为UniHypoBench上未进行长度归一化的部分结果摘要。RA(%)和PSC为关键指标。
-
偏好学习有效但远未完美:所有偏好优化方法在RA和PSC上普遍优于基线模型,证明了它们确实能捕捉到偏好信息。然而,即使是表现最好的SimPO,其排序准确率也仅在60-70%左右,说明现有方法对偏好的学习仍有很大的提升空间。
-
模型学习到的是“代理模型”的特定偏好:当使用与训练时相同的代理模型进行评估时(同分布),模型表现出明显的对齐效果。但当换用另一个具有不同偏好分布的代理模型进行评估时(异分布),性能提升消失甚至下降。这表明当前方法更多是“过拟合”到特定代理模型的判断模式,而非学习到通用的偏好。
-
捕捉偏好强度极具挑战性:实验中,所有模型的PSC得分普遍很低(通常低于0.3),说明它们难以准确量化不同响应之间的偏好强度差异。SimPO是一个例外,其PSC得分相对较高,显示出在建模偏好强度方面的潜力。
-
方法机制分析:
- 通过对生成似然分布的可视化分析发现,DPO和SimPO等方法能有效抑制负样本(不好的响应)的生成概率,但未能实现将好坏响应完全分离的理想双峰分布。这表明它们主要是通过全局似然调整来学习,而非构建更具辨别力的偏好表征。
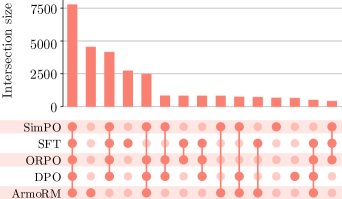
- Upset图分析显示,不同方法在学习到的偏好上存在交集(所有方法都学到的基础知识)、大量未学到的偏好,以及各自方法学到的独特偏好。
最终结论
本文提出的HEAL框架通过引入假设空间分析,为评估和理解LLM的偏好对齐提供了全新的视角和强大的诊断工具。实验结果表明,尽管当前的偏好优化方法取得了一定成功,但它们在学习的完整性、鲁棒性以及对偏好强度的细粒度感知方面存在明显不足。HEAL框架揭示的这些问题为未来开发更先进、更全面的对齐算法指明了方向。