Higher Embedding Dimension Creates a Stronger World Model for a Simple Sorting Task
-
ArXiv URL: http://arxiv.org/abs/2510.18315v1
-
作者: Brady Bhalla; Nancy Chen; Honglu Fan
-
发布机构: California Institute of Technology; Cornell University; Google DeepMind
TL;DR
本文通过强化学习训练Transformer执行排序任务,发现更高的嵌入维度能促使智能体形成更可靠、更具可解释性的内部世界模型,即便任务准确率早已饱和。
关键定义
本文沿用了现有的概念,并在一个简单的排序任务中对其进行了具体化和量化。以下是对理解本文至关重要的核心观察和评估指标:
-
全局顺序编码 (Global Order Encoding):一个涌现出的机制。Transformer模型在其自注意力权重矩阵的最后一行中,为输入序列的每个Token(代表一个数字)生成一个值。这些值的顺序与Token所代表数字的实际大小顺序单调对应,从而在注意力权重中编码了整个序列的全局顺序。
-
最大差异选择 (Largest Difference Selection):与上述机制配合的决策规则。模型通过计算“全局顺序编码”中相邻值之间的差异,并选择差异最大的位置执行相邻交换操作。这一策略被证明是智能体进行排序决策的核心。
-
表征质量评估指标 (Representation Quality Metrics):为量化上述两个机制的可靠性,本文定义了三个关键指标:
- 准确率 (Accuracy):智能体在所有可能的排列中,选择正确交换操作的比例。
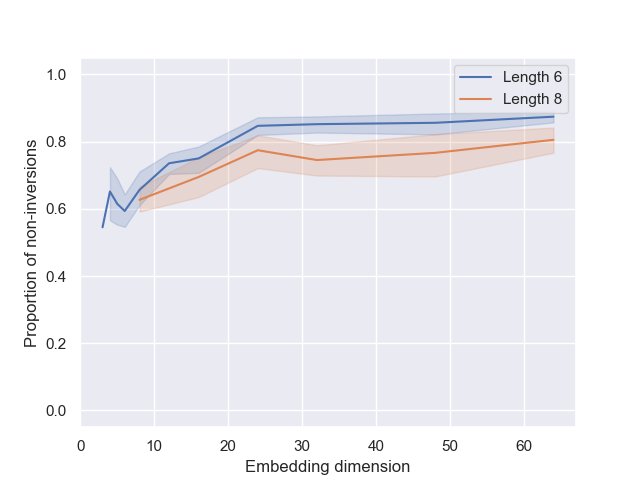
- 顺序一致性 (Ordering Consistency):通过计算注意力权重最后一行的值序列与输入数字序列之间的“非逆序对”比例来衡量。值越高,表示模型内部编码的顺序与真实顺序越一致。
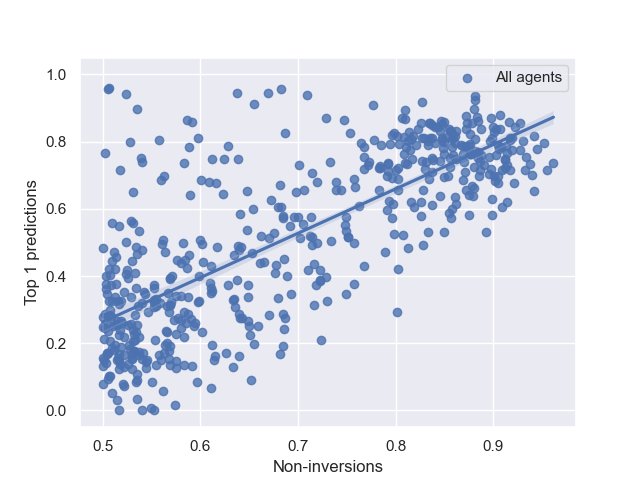
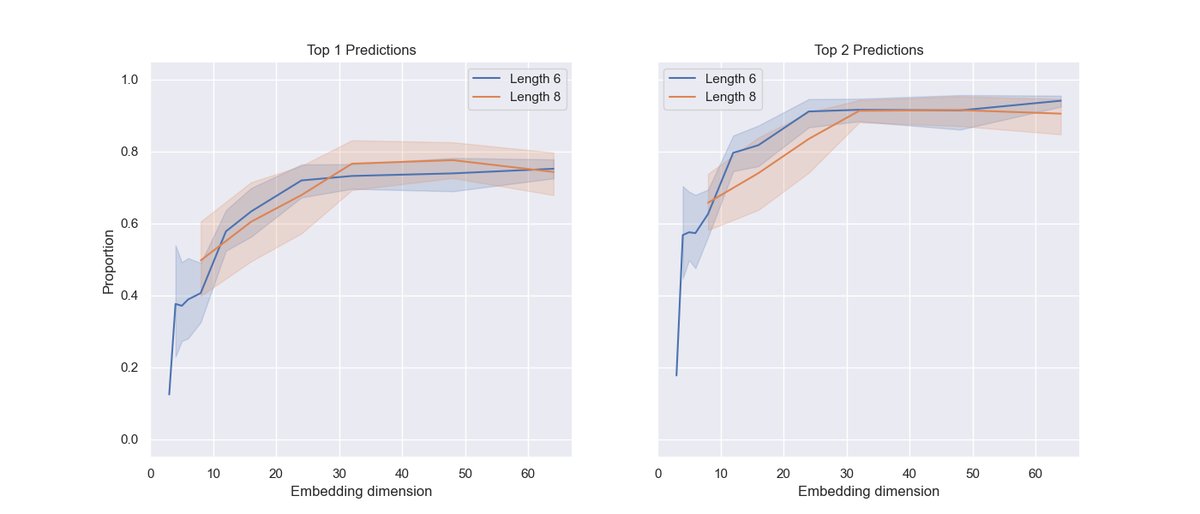
- 决策匹配度 (Decision Alignment):衡量智能体实际选择的交换位置,与其内部“最大差异”预测相符的频率(例如,是否是Top-1或Top-2的预测)。
相关工作
当前,研究人员已开始利用Transformer架构在强化学习(Reinforcement Learning, RL)中构建世界模型 (world model),以提升数据效率和性能。同时,机制可解释性 (mechanistic interpretability) 领域通过分析小型、简化的“玩具”模型(如Othello-GPT)来揭示神经网络内部的算法行为。
然而,现有研究存在一个问题:我们知道模型能够形成内部表征,但对于这些表征的质量,以及模型容量(如嵌入维度)如何影响这种质量,尤其是在一个简单、确定的算法任务中,尚缺乏清晰的量化理解。
本文旨在解决的具体问题是:在一个简单的排序任务中,由RL训练的小型Transformer是否会发展出一个可解释的内部世界模型?以及,模型的嵌入维度如何影响这个世界模型的保真度、一致性和鲁棒性,这种影响是否超越了单纯的任务准确率提升?
本文方法
本文设计了一个受控实验,以探究嵌入维度对Transformer智能体在排序任务中学习内部表征质量的影响。
实验设计
智能体的任务是通过一系列相邻交换操作(类似冒泡排序)来排序一个数字序列。实验的核心自变量是模型的嵌入维度 (embedding dimension),其范围从2到128。实验在长度为6和8的序列上进行。为了保证结果的稳健性,本文训练了475个具有不同随机种子的智能体,从而能够可靠地评估不同嵌入维度下的平均性能和行为一致性。
模型与训练
- 模型架构:采用了一个极简的、解码器式(decoder-only)的Transformer模型,该模型仅包含一个嵌入层、一个单头自注意力模块和一个线性输出层。这种简化结构有助于隔离和分析嵌入维度的影响。
- 训练框架:使用强化学习中的近端策略优化 (Proximal Policy Optimization, PPO) 算法进行训练。
- 状态与动作:状态是数字序列的一个排列,动作是在某个位置进行相邻交换。
- 奖励机制:当序列在一次交换后变为完全有序时,智能体获得+1的奖励;否则,获得-0.001的微小负奖励,以鼓励其尽快完成任务。
评估指标
为了量化智能体内部“世界模型”的质量,本文设计了三个关键指标:
- 准确率:对于所有可能的初始排列,智能体选择的交换操作能够减少序列逆序数的比例。准确率为1表示智能体能以最优方式排序任何序列。
- 全局顺序一致性:考虑注意力权重矩阵 $W$ 的最后一行 $W_{\ell}$。计算 $W_{\ell}$ 中各值的顺序与输入序列 $\pi$ 的真实数字顺序之间的非逆序对比例。该值被归一化到 \([0, 1]\) 区间,1表示完美对齐。
- 决策机制匹配度:对于每个状态,计算 $W_{\ell}$ 中相邻值的差异,并对其进行排序。然后,检查智能体实际选择的交换位置在该排序列表中的排名。本文主要统计实际选择位于Top-1和Top-2预测的频率。
实验结论
实验结果有力地证明,尽管智能体在很低的嵌入维度下就能达到近乎完美的任务准确率,但更高的嵌入维度对于形成一个更一致、更忠实、更鲁棒的内部排序算法至关重要。
核心发现
智能体普遍收敛到一个简单且可解释的两步算法:
- 编码全局顺序:注意力权重的最后一行学会了对输入数字进行单调映射,从而编码了整个序列的全局顺序。
- 选择最大差异:智能体通过寻找该编码序列中相邻值的最大差异来决定下一步的交换位置。
准确率 vs. 表征质量
- 准确率饱和:对于长度为6的序列,当嵌入维度大于16时,智能体的准确率就已饱和,达到近100%。这表明完成任务本身并不需要很高的表征容量。
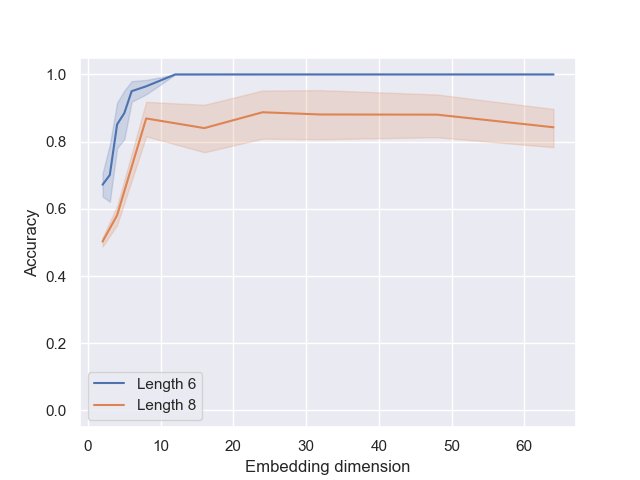
- 表征质量持续提升:与准确率不同,衡量全局顺序一致性和决策机制匹配度的指标在嵌入维度增加到约30时才趋于平稳。这意味着,额外的嵌入维度被用来提炼和稳固内部的“排序电路”,使其更可靠、更符合上述两步算法。
关键数据
- 全局顺序:在高嵌入维度下,对于长度为6和8的序列,顺序一致性指标分别稳定在87%和78%左右。
- 决策机制:在高准确率的智能体中,76-77%的决策与Top-1预测匹配,超过90%与Top-2预测匹配。
高准确率智能体选择的移动属于注意力矩阵最后一行中最大差距的比例。
| Top 1 | Top 2 | |
|---|---|---|
| 长度 6 | 76.2% | |
| 长度 8 | 92.5% |
失败模式
低嵌入维度的智能体常陷入“局部贪心陷阱”:它们仅关注局部最明显的逆序对并进行交换,因为它们未能形成全局顺序的表征,无法理解有时需要暂时增加局部逆序来纠正更大的全局逆序。随着嵌入维度的增加,这种失败模式显著减少。
总结
本文的结论是,增加嵌入维度(模型容量)对模型的好处远不止提升最终性能。在本文的排序任务中,更高的维度能创造一个结构更清晰、行为更可预测的内部世界模型。这一发现为“模型规模的提升会改善表征质量”提供了量化证据,并强调了在评估模型时,直接探测其内部表征的重要性,而不应仅仅依赖于任务表现。这种更优质的内部表征可能带来更好的泛化能力和鲁棒性。