Hybrid Architectures for Language Models: Systematic Analysis and Design Insights
-
ArXiv URL: http://arxiv.org/abs/2510.04800v1
-
作者: Junjie Wang; Chien-Yu Lin; Carole-Jean Wu; Haroun Habeeb; Seungyeon Kim; Bilge Acun; Sangmin Bae; Liang Luo
-
发布机构: KAIST; Meta
TL;DR
本文系统性地分析和评估了语言模型的混合架构(层间与层内),发现层内混合策略在模型质量与计算效率之间取得了最佳的帕累托前沿 (Pareto-frontier)。
关键定义
本文的核心是围绕两种混合语言模型架构展开的,它们都是对现有基础模块(Transformer和Mamba)的组合:
- 层间混合模型 (Inter-layer Hybrid Model):一种序列化的混合方法。它在模型的不同层之间交替堆叠 Transformer 块和 Mamba 块。其设计的关键在于决定两种模块的比例和排列顺序。
- 层内混合模型 (Intra-layer Hybrid Model):一种并行的混合方法。它在单个模型层内部实现两种基础模块的融合。常见做法是“头注意力切分 (head-wise splitting)”,即将一部分注意力头分配给 Transformer 的自注意力机制,另一部分分配给 Mamba 的状态空间模型。
相关工作
当前,主流的大语言模型大多基于 Transformer 架构,但其核心的自注意力机制具有与序列长度成二次方关系的计算复杂度,这导致在处理长序列时推理速度慢、内存占用高。
为了解决这一瓶颈,一系列受信号处理启发的结构化状态空间模型 (structured state space models, SSMs),如 Mamba,应运而生。Mamba 通过将上下文压缩为有限维度的状态,实现了对序列长度的线性扩展,并在语言建模任务上展现出与 Transformer 相当的性能。
这催生了混合架构的研究,即结合 Transformer 和 Mamba 各自的优势。尽管已经出现了一些混合模型(如 Jamba, Zamba),但它们大多是特定设计的展示,领域内缺乏对不同混合策略的系统性比较和深入分析。社区对于哪种混合方式更优、其背后的关键设计因素以及性能与效率的权衡关系等问题尚不清晰。
本文旨在解决这一问题,通过全面的评估,为层间和层内两种混合策略提供系统的比较、关键的设计洞见和实用的架构指南。
本文方法
本文通过系统性的实验,对层间(串行)和层内(并行)两种混合架构进行了全面的评估和优化,旨在为构建高效能的混合语言模型提供设计准则。
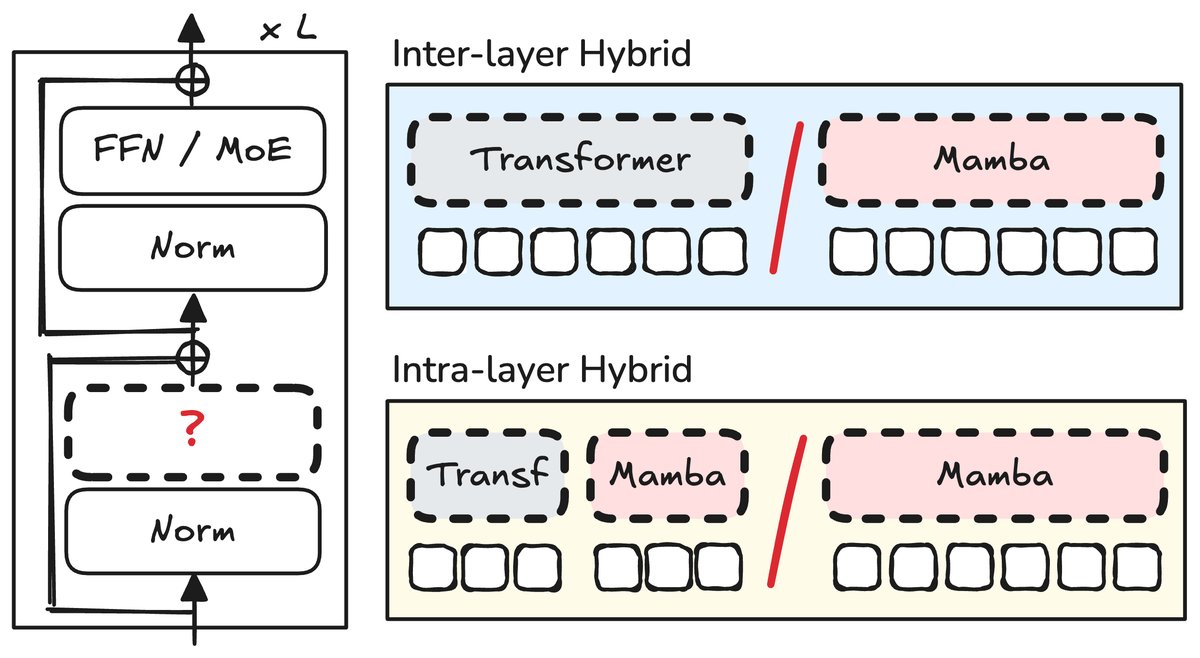
层间混合模型 (Inter-layer Hybrid)
设计与探索
层间混合模型通过在不同层顺序堆叠 Transformer 块和 Mamba 块。本文主要探索了两个核心设计问题:
- 模块比例:Transformer 块与 Mamba 块的最佳比例是多少?研究发现,尽管 1:1 的比例在模型质量上表现最佳,但考虑到效率,1:5 左右的比例(Transformer:Mamba)能在质量和效率之间取得理想的平衡。这与许多现有大型混合模型采用较低 Transformer 比例的设计相符。
- 模块位置:不同模块在网络中的位置是否影响性能?实验明确指出,不应将 Transformer 块放置在模型的初始层,这样做会导致性能严重下降。将 Transformer 块放置在中间层通常能获得最佳效果。
层内混合模型 (Intra-layer Hybrid)
设计与探索
层内混合模型在同一层内并行融合 Transformer 和 Mamba。本文采用“头注意力切分”的方式,并探索了多种架构变体:
- 架构变体:通过对归一化策略、可学习标量、融合操作和输出投影等多个维度进行消融实验,本文提出了一种优化的层内混合块设计。关键发现是:由于模块输出尺度差异大,归一化层至关重要;在融合时,通过减法操作(减轻注意力噪声)或拼接操作能获得最佳性能。
- 维度比例:在混合块内部,分配给 Transformer 和 Mamba 的维度比例如何影响性能?实验表明,增加分配给 Transformer 的维度能持续提升模型质量,这说明 Transformer 部分在混合块中扮演着关键角色。然而,考虑到并行计算的效率瓶颈在于较慢的 Transformer 部分,1:1 的维度比例提供了一个实用且高效的平衡点。
- 模块比例与位置:与层间混合类似,增加包含 Transformer 的层内混合块的比例也能稳定提升模型质量。将这些混合块均匀地散布在模型的不同深度,可以获得最好的性能。
实验结论
本文通过在语言建模、长上下文能力、扩展性和效率等多个维度进行综合实验,得出了一系列关于混合架构的关键结论。
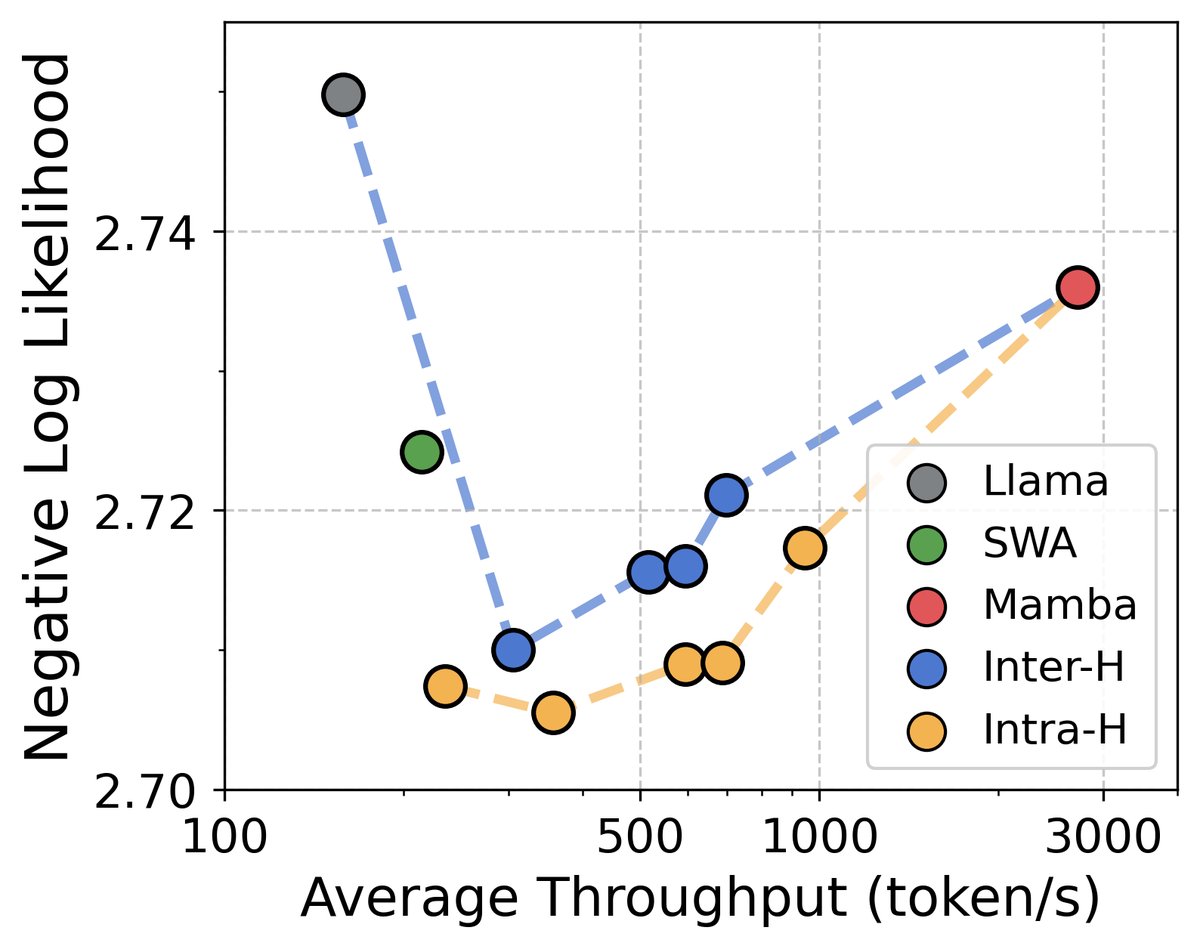
质量与效率
- 混合优于单一架构:两种混合模型(层间与层内)的性能均显著优于纯 Transformer 或纯 Mamba 模型,在同等算力下,准确率提升最多可达 2.9%。
- 层内混合表现最佳:层内混合模型在模型质量和推理效率的帕累托前沿上表现最优(如图2所示),实现了最佳的权衡。
- 训练与推理效率高:得益于 Mamba 的线性复杂度和高效的并行扫描算法,混合模型在训练上更快,在推理上则实现了更高的吞吐量和更低的显存占用(KV Cache),尤其是在长上下文场景下。
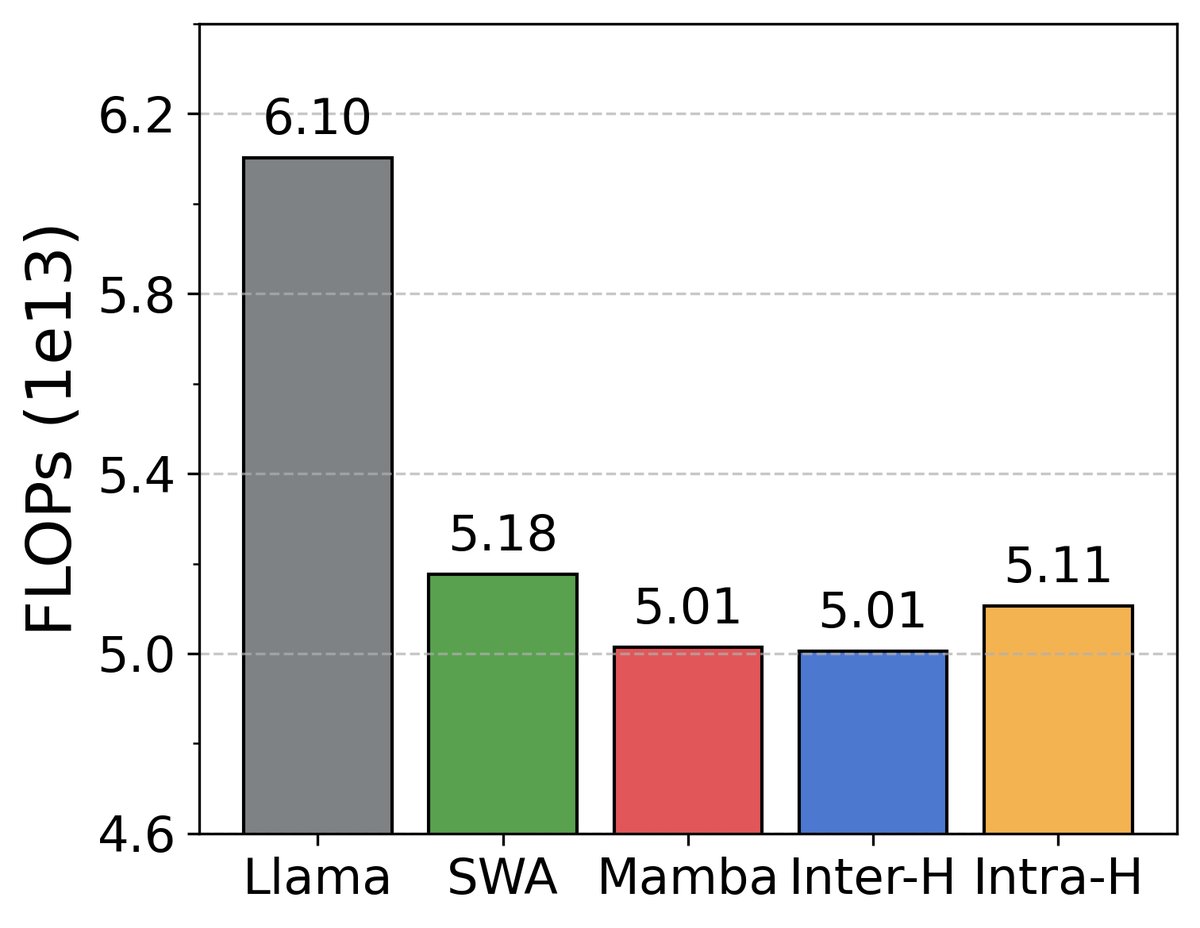
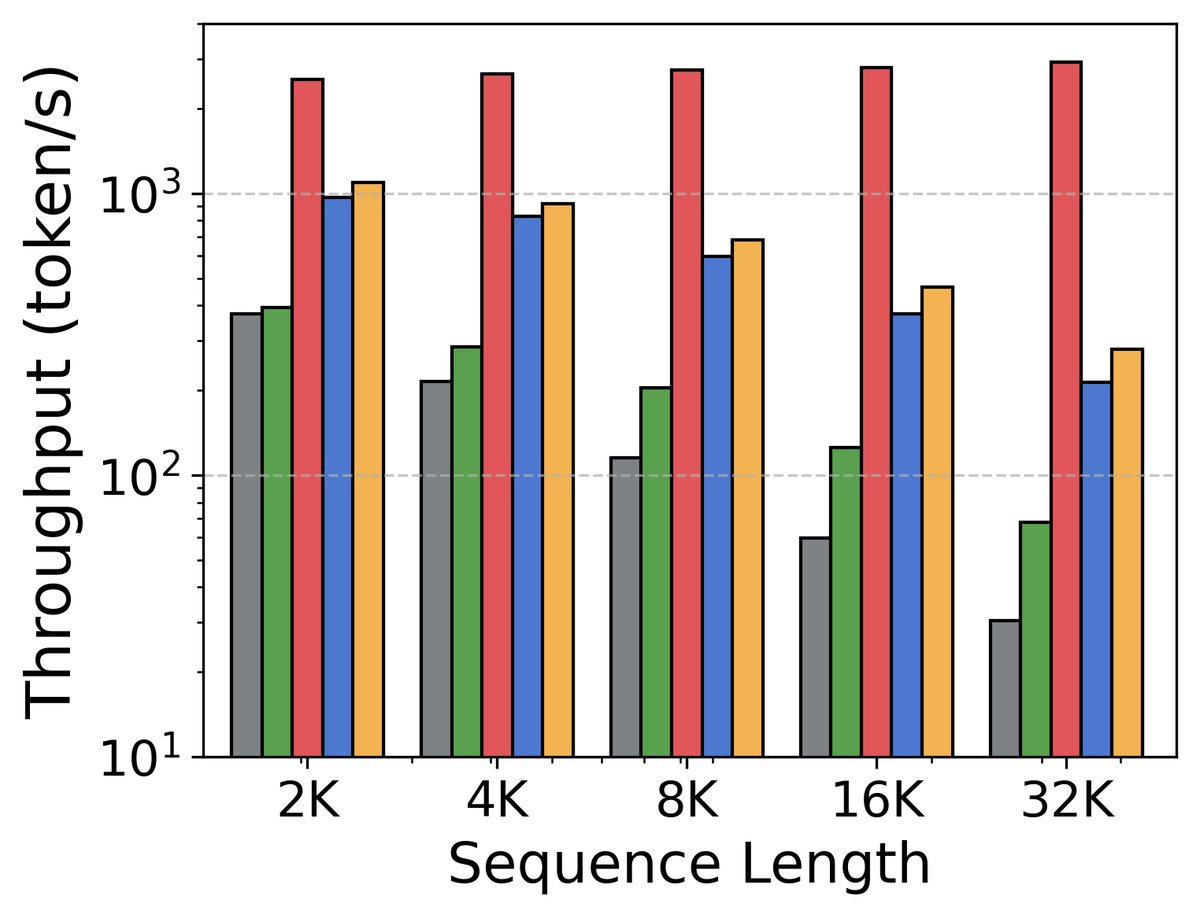
长上下文能力
- 更强的外推能力:混合模型继承了 Mamba 的优势,在处理超过预训练长度的序列时表现出更好的长度外推能力(即损失持续下降),而纯 Transformer 模型则表现不佳。
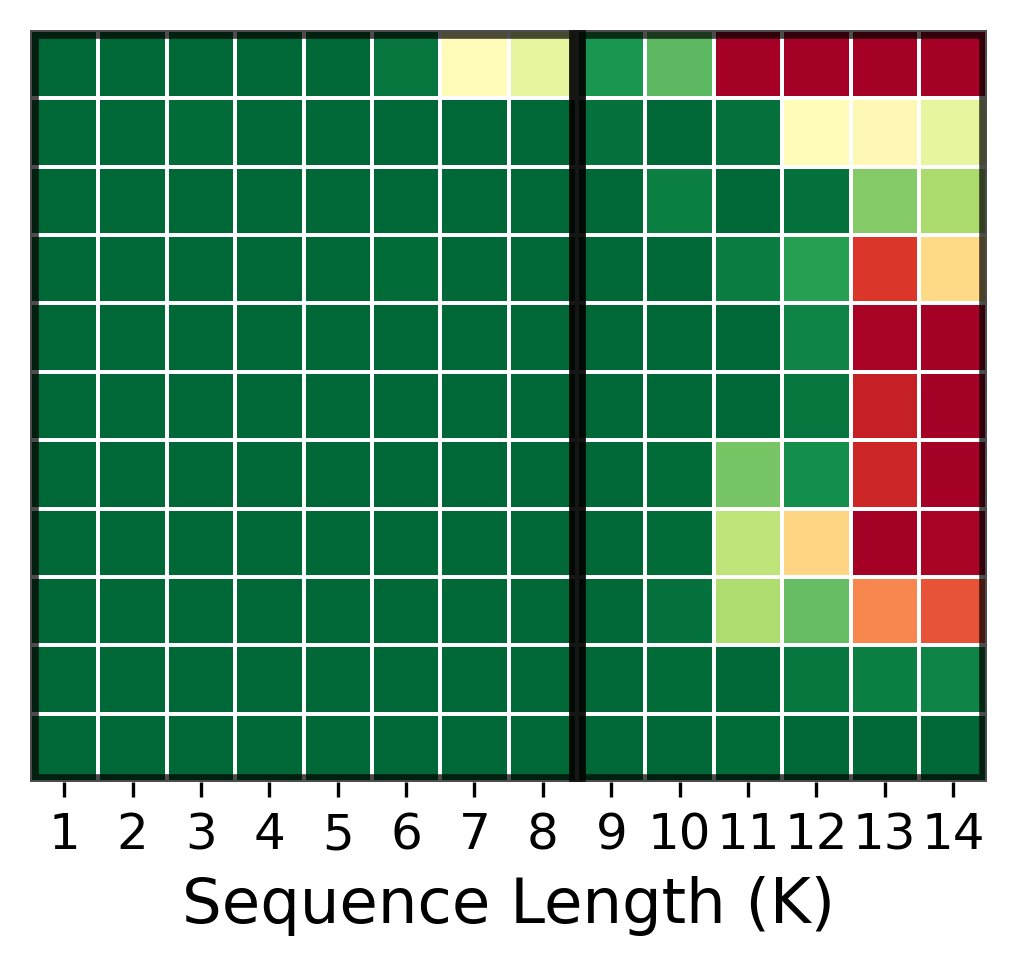
- 克服“大海捞针”难题:在“大海捞针 (Needle-In-A-Haystack)”测试中,纯 Transformer 在超长上下文中会失效,而 Mamba 和滑动窗口注意力 (SWA) 也仅在局部区域有效。令人惊讶的是,混合模型成功克服了两种基础模块的弱点,在远超预训练长度的上下文中依然保持了强大的信息检索能力。
扩展性与设计洞察
- 与 MoE 兼容:混合架构与专家混合 (Mixture-of-Experts, MoE) 技术完全兼容。将 MoE 应用于前馈网络层可以进一步提升模型性能,且不影响混合注意力的设计。
- 独特的缩放定律:混合模型展现出介于 Transformer 和 Mamba 之间的计算最优缩放行为。层内混合模型相比层间混合模型稍微更“数据饥渴”。
- 提供了清晰的设计指南:通过大量的消融研究,本文为两种混合架构提供了具体的、经过验证的设计准则,例如最优的模块比例(平衡质量与效率的 1:5)、模块放置策略(Transformer 不放于底层)以及层内混合块的具体设计(使用归一化、采用减法或拼接融合)。

| 架构 | FLOPs/样本 | 参数 (M) | 缓存大小 (MiB) | | — | — | — | — | | Transformer (Llama) | 134.2B | 10.1 | 256.0 | | SWA Transformer | 15.3B | 10.1 | 34.0 | | Mamba | 113.8B | 25.1 | 13.4 | | 层间混合 | 117.2B | 22.6 | 52.2 | | 层内混合 | 120.9B | 22.8 | 63.6 | —

| 方法 | 规模 | Tokens (B) | FLOPs (Peta) | NLL (验证集) | 平均准确率 | | — | — | — | — | — | — | | P-匹配 | | | | | | | Transformer | 1B | 102 | 13.7 | 2.569 | 59.90 | | SWA | 1B | 102 | 11.8 | 2.535 | 60.10 | | Mamba | 1B | 102 | 11.6 | 2.551 | 59.34 | | 层间混合 | 1B | 102 | 12.0 | 2.518 | 61.16 | | 层内混合 | 1B | 102 | 12.3 | 2.512 | 61.32 | | F-匹配 | | | | | | | Transformer | 1B | 102 | 13.7 | 2.569 | 59.90 | | Layer-inter | 1B | 118 | 13.7 | 2.483 | 62.80 | —

| 方法(1B) | MoE | NLL (验证集) | 平均准确率 | | — | — | — | — | | Transformer | 否 | 2.569 | 59.90 | | Transformer | 是 | 2.492 | 64.08 | | 层间混合 | 否 | 2.518 | 61.16 | | 层间混合 | 是 | 2.428 | 65.41 | | 层内混合 | 否 | 2.512 | 61.32 | | 层内混合 | 是 | 2.424 | 65.65 | —