ImageBind: One Embedding Space To Bind Them All
-
ArXiv URL: http://arxiv.org/abs/2305.05665v2
-
作者: Ishan Misra; Armand Joulin; Alaaeldin El-Nouby; Zhuang Liu; Kalyan Vasudev Alwala; Mannat Singh; Rohit Girdhar
-
发布机构: Meta AI
TL;DR
本文提出 ImageBind,一种仅通过将图像与其他多种模态(文本、音频、深度、热成像、IMU)的数据进行配对,就能学习到一个统一的多模态联合嵌入空间,并由此涌现出跨模态对齐与组合等新能力的方法。
关键定义
- 联合嵌入空间 (Joint Embedding Space): 一个共享的、高维的向量空间。来自不同模态(如图像、文本、音频)的数据经过各自的编码器后,被映射到这个空间中的向量(即嵌入)。在这个空间里,语义上相关的不同模态内容其向量表示在空间位置上是相近的。
- 图像绑定 (Binding with Images): 本文的核心思想。指利用图像作为“锚点”或“桥梁”,将其他所有模态都与图像模态对齐。具体做法是,只训练图像与其他单一模态的配对数据(如图像-文本、图像-音频),而不要求所有模态之间都有配对数据。
- 涌现对齐 (Emergent Alignment): 一种关键的现象。当模态 M1 与图像(I)对齐,同时模态 M2 也与图像(I)对齐后,M1 和 M2 之间会自动产生对齐,即使在训练过程中从未见过任何 (M1, M2) 的配对数据。例如,通过学习(图像,文本)和(图像,音频)的对齐,模型能自然地理解(文本,音频)之间的关联。
- 涌现零样本分类 (Emergent Zero-shot Classification): 基于“涌现对齐”产生的零样本能力。例如,模型可以在没有任何(音频,文本)配对数据训练的情况下,仅通过文本描述来对音频进行分类。这与标准的零样本分类(如 CLIP)不同,后者需要直接的(图像,文本)配对训练数据来实现对图像的零样本分类。
相关工作
当前,多模态学习领域在联合训练图像与文本(如 CLIP, ALIGN)或特定模态对(如视频-音频)方面取得了巨大成功,这些方法能够学习到强大的语义表示。然而,它们的局限性在于,所学的嵌入空间通常只适用于训练时使用的模态对。例如,为视频-音频任务训练的模型无法直接用于图像-文本任务。
这一领域的主要瓶颈是缺乏包含所有模态的大规模配对数据集(例如,一个样本同时包含高质量的图像、文本、音频、深度、热成像和IMU数据)。
本文旨在解决的问题是:如何在没有这种“全能”数据集的情况下,学习一个能够容纳并对齐多种不同模-态(图像、文本、音频、深度、热成像、IMU)的单一、统一的嵌入空间。
本文方法
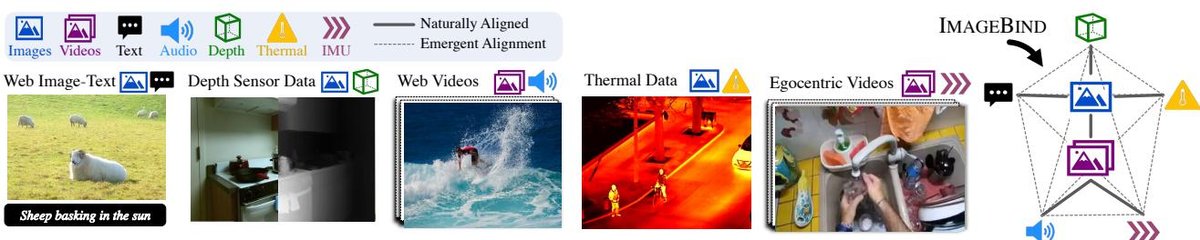
本文的核心目标是利用图像作为中心枢纽,将所有模态绑定在同一个联合嵌入空间中。通过分别将每种模态的嵌入与图像嵌入对齐,模型能够涌现出跨模态的零样本能力,即使某些模态对在训练中从未出现过。
创新点
本文最本质的创新在于提出了一个极其简洁且可扩展的范式:仅需图像配对数据即可绑定所有模态。以往的方法要么局限于特定模态对,要么需要多模态间的直接配对数据。ImageBind 证明,通过将所有其他模态(音频、深度、文本等)分别与图像对齐,系统能“涌现”出所有模态之间的相互对齐。这大大降低了对多模态数据的采集要求,因为(图像,模态X)这样的数据对远比(模态X,模态Y,模态Z…)的数据更容易获取。
优点
- 高可扩展性:该框架易于扩展。要加入一个新的模态,只需找到该模态与图像的配对数据进行训练,而无需与其他已有模态重新配对。
- 利用现有成果:能够直接利用并“冻结”像 OpenCLIP 这样强大的预训练视觉-语言模型的编码器,从而将它们强大的图像和文本表示能力迁移到其他非视觉模态。
- 涌现新能力:无需任何额外训练,即可实现多种新颖的应用,如跨模态检索(用音频搜图片)、模态组合(图片+声音进行检索)、跨模态检测(用声音定位物体)和生成(用声音生成图片)。
方法细节
绑定模态
对于任意一个模态 $\mathcal{M}$ 和图像 $\mathcal{I}$ 的配对观察样本 $(I_i, M_i)$,模型使用两个独立的编码器 $f$ 和 $g$ 将它们分别编码为归一化的嵌入向量 $\mathbf{q}_i = f(I_i)$ 和 $\mathbf{k}_i = g(M_i)$。然后,使用 InfoNCE 对比损失函数来优化这两个编码器,使得配对样本的嵌入在空间中更接近,非配对样本的嵌入更疏远。
损失函数定义如下:
\[L_{\mathcal{I},\mathcal{M}} = -\log \frac{\exp(\mathbf{q}_i^{\mathsf{T}} \mathbf{k}_i/\tau)}{\exp(\mathbf{q}_i^{\mathsf{T}} \mathbf{k}_i/\tau) + \sum_{j \neq i} \exp(\mathbf{q}_i^{\mathsf{T}} \mathbf{k}_j/\tau)}\]其中,$\tau$ 是一个控制分布平滑度的温度超参数,$j$ 表示批次内的负样本。实际训练中使用的是对称损失 $L_{\mathcal{I,M}} + L_{\mathcal{M,I}}$。通过对所有模态都执行这一过程(即训练 \((图像, 文本)\)、\((图像, 音频)\)、\((图像, 深度)\) 等),最终实现了所有模态在统一空间中的对齐。
实现细节
- 编码器架构:所有模态的编码器均采用 Transformer 架构。图像/视频使用 ViT,音频被转换为梅尔频谱图后也使用 ViT,深度和热成像图被当作单通道图像同样使用 ViT。IMU 数据先通过一维卷积处理,再送入 Transformer。文本编码器则沿用 CLIP 的设计。
- 训练数据:
- 图像-文本: 利用大规模网络数据,直接加载并冻结从 OpenCLIP 预训练好的 ViT-H 图像编码器和文本编码器。
- 视频-音频: AudioSet 数据集。
- 图像-深度: SUN RGB-D 数据集。
- 图像-热成像: LLVIP 数据集。
- 视频-IMU: Ego4D 数据集。
- 训练策略:在训练过程中,强大的图像和文本编码器被冻结,只更新音频、深度、热成像和 IMU 模态的编码器。这种策略高效地将预训练模型的知识迁移到了新模态。
实验结论

实验结果有力地证明了 ImageBind 方法的有效性,尤其是在涌现零样本能力方面。
关键实验结果
- 涌现零样本分类:ImageBind 在多个模态的零样本分类任务上取得了令人瞩目的成绩。例如,在音频分类基准(如 ESC, AS-A)上,它的涌现零样本性能不仅远超随机猜测,甚至能媲美或超越那些使用(音频-文本)配对数据进行专门监督训练的先进模型(如 AudioCLIP)。这证明图像确实成功地扮演了连接音频和文本语义的桥梁。
| IN1K | P365 | K400 | MSR-VTT | NYU-D | SUN-D | AS-A | VGGS | ESC | LLVIP | Ego4D | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random | 0.1 | 0.27 | 0.25 | 0.1 | 10.0 | 5.26 | 0.62 | 0.32 | 2.75 | 50.0 | 0.9 |
| ImageBind | 77.7 | 45.4 | 50.0 | 36.1 | 54.0 | 35.1 | 17.6 | 27.8 | 66.9 | 63.4 | 25.0 |
| Text Paired | - | - | - | - | 41.9* | 25.4* | 28.4† | - | 68.6† | - | - |
| Absolute SOTA | 91.0 | 60.7 | 89.9 | 57.7 | 76.7 | 64.9 | 49.6 | 52.5 | 97.0 | - | - |
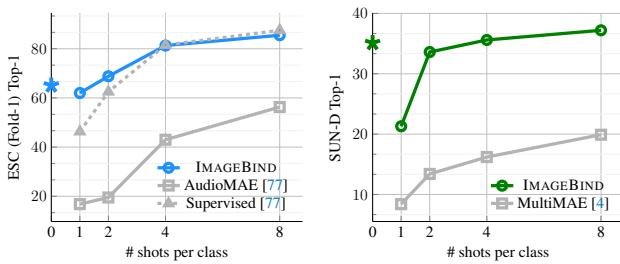
- 少样本分类:在少样本学习场景下,ImageBind 学习到的特征同样表现出色。无论是在音频还是深度分类任务上,ImageBind 提取的特征在仅用少量标注样本进行线性分类器微调时,其性能全面优于专门为该模态设计的自监督模型(如 AudioMAE 和 MultiMAE)。
- 模态组合与应用:
- 嵌入向量算术:实验表明,ImageBind 的嵌入空间支持跨模态的语义组合。例如,将“一张桌上水果的图片”的嵌入和“鸟鸣声”的嵌入相加,用得到的组合向量去检索图片,可以成功找回“树上有鸟和水果”的图片。
- “升级”现有模型:无需重新训练,ImageBind 的音频嵌入可以直接替换基于文本的模型中的文本嵌入。例如,将 Detic(一个基于文本的目标检测器)的类别嵌入换成 ImageBind 的音频嵌入,使其能用声音(如狗叫声)来定位图像中的物体。同样,也能让 DALLE-2 这样的扩散模型根据音频输入来生成图像。

方法优势验证
- 图像编码器的重要性:消融实验(图 6)清晰地表明,随着图像编码器(从 ViT-B 到 ViT-L 再到 ViT-H)能力的增强,所有其他模态的涌现零样本分类性能都得到了显著提升。这证明了更强的视觉表征能够更好地“绑定”其他模态。
- 最佳实践:实验还探索了对比损失的温度、投影头设计、训练时长等超参数,为不同模态提供了最佳实践配置。例如,深度和音频模态对对比温度的偏好不同。
最终结论
本文成功证明了,通过一个简单而强大的“图像绑定”策略,可以学习到一个覆盖六种模态的统一嵌入空间。该方法的核心贡献在于揭示并利用了“涌现对齐”现象,使得模型在没有直接看到跨模态配对数据的情况下,也能进行零样本跨模态推理。ImageBind 不仅在多个基准测试中取得了SOTA或极具竞争力的表现,还开辟了如跨模态组合、用非文本模态“提示”现有视觉模型等全新的应用方向,为多模态学习领域提供了一个简洁、有效且可扩展的新范式。