Improved Baselines with Visual Instruction Tuning
-
ArXiv URL: http://arxiv.org/abs/2310.03744v2
-
作者: Yuheng Li; Haotian Liu; Chunyuan Li; Yong Jae Lee
-
发布机构: Microsoft Research; University of Wisconsin–Madison
TL;DR
本文通过对LLaVA框架进行简单而有效的改进,即采用MLP视觉-语言连接器、引入带有响应格式化提示的学术VQA数据等,构建了LLaVA-1.5,一个在11个基准上达到SOTA、同时保持极高数据和计算效率的大型多模态模型基线。
关键定义
本文主要沿用并优化了现有大型多模态模型(Large Multimodal Models, LMMs)的设计,其中几个关键概念对于理解本文至关重要:
- 视觉指令微调 (Visual Instruction Tuning): 指在经过预训练后,使用包含图像和指令的特定数据集对LMM进行微调的过程。其目标是让模型能理解并遵循多样化的人类指令,完成看图对话、推理、描述等复杂任务。
- 视觉-语言连接器 (Vision-Language Connector): LMM中连接预训练视觉编码器和大型语言模型(LLM)的关键模块。它的作用是将视觉特征(如图像块Tokens)转换为LLM能够理解的语言嵌入空间中的Tokens。本文证明了简单的MLP连接器比复杂的Q-Former等结构更具数据效率和竞争力。
- 响应格式化提示 (Response Format Prompting): 本文提出的一种简单而有效的数据处理技巧。通过在VQA等任务的提问指令末尾附加明确的格式要求(如 “Answer the question using a single word or phrase.”),来引导模型生成特定格式(如短答案)的回复,从而有效解决了模型在长对话和短问答两种模式间难以平衡的问题。
相关工作
当前,大型多模-态模型(LMMs)在视觉指令微调的驱动下取得了显著进展。以LLaVA和InstructBLIP为代表的模型展示了强大的指令遵循和视觉推理能力。然而,现有技术存在明显瓶颈:
- 能力不均衡: 不同的模型架构和训练数据导致能力上的偏差。例如,LLaVA擅长开放式对话,但在需要简短、精确答案的传统VQA基准上表现不佳。相反,InstructBLIP在VQA上表现优异,但其对话能力较弱,容易对短答案“过拟合”。
- 高昂的训练成本: 许多先进模型(如InstructBLIP, Qwen-VL)依赖复杂的视觉重采样器(visual resamplers,如Q-Former)和海量的图文对数据(上亿甚至十亿级别)进行预训练,这使得研究和复现的门槛非常高。
本文旨在解决上述问题,特别是如何在一个统一的、数据高效的框架内,平衡模型的对话能力和在学术基准上的表现,并建立一个易于复现且性能强大的开源基线。
本文方法
本文在初代LLaVA模型的基础上进行了一系列系统性的改进,提出了LLaVA-1.5。其核心思想是,通过简单的架构调整、智能的数据策略和有效的扩展,可以实现比复杂模型更优的性能和更高的数据效率。
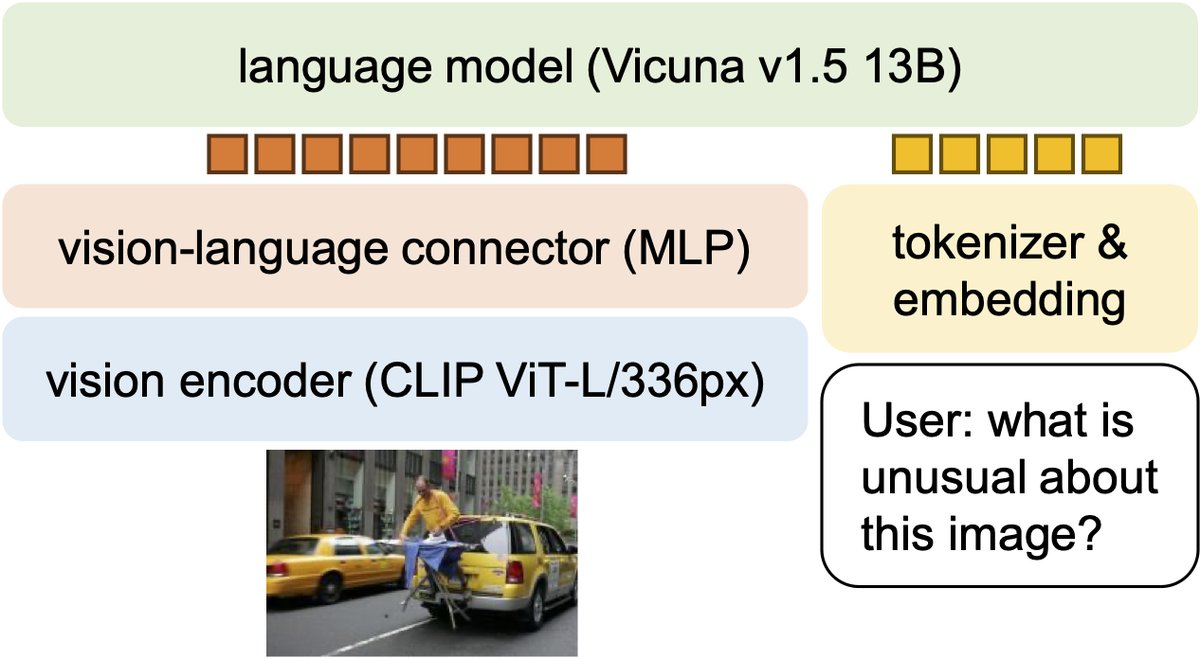 图:LLaVA-1.5 对 LLaVA 的简单修改:一个MLP连接器和包含带有响应格式提示的学术任务导向数据。
图:LLaVA-1.5 对 LLaVA 的简单修改:一个MLP连接器和包含带有响应格式提示的学术任务导向数据。
摆脱复杂设计的束缚
与InstructBLIP等模型采用Q-Former这类复杂的视觉重采样器不同,本文发现LLaVA中简单的全连接视觉-语言连接器具有惊人的潜力和数据效率。本文的改进保留了这一简洁的设计哲学。
创新点
核心改进主要体现在以下几个方面:
-
MLP视觉-语言连接器: 将LLaVA原有的单层线性投射层升级为一个两层的MLP。借鉴自监督学习的经验,这个小改动增强了连接器的表示能力,从而提升了模型的整体多模态理解力。
-
响应格式化提示: 为解决模型在长对话和短问答两种风格间的冲突,本文引入了“响应格式化提示”策略。在处理VQA这类需要简短答案的数据集时,直接在问题后附加一句明确的指令,如\("Answer the question using a single word or phrase."\)。这种方法避免了对答案进行复杂后处理,让模型在微调阶段就能学会根据指令调整输出格式,成功地平衡了不同任务的需求。
| 不同的格式化提示示例 | |
|---|---|
| 普通提示 | What is the color of the shirt that the man is wearing? |
| 回答 | The man is wearing a yellow shirt. |
| 模糊提示 | Q: What is the color of the shirt that the man is wearing? A: |
| 回答 | The man is wearing a yellow shirt. |
| 格式化提示 | What is the color of the shirt that the man is wearing? Answer the question using a single word or phrase. |
| 回答 | Yellow. |
表:不同提示对输出格式的规整效果对比。
- 扩展数据与模型规模:
- 数据: 在LLaVA原有指令微调数据的基础上,集成了更多面向学术任务的数据集,包括多种VQA(如VQAv2, OKVQA)、OCR(如TextVQA)和区域级VQA(如Visual Genome, RefCOCO)数据。此外,还加入了纯文本对话数据ShareGPT,以增强模型的语言和推理能力。
- 模型: 将视觉编码器从标准CLIP-ViT-L升级到能处理更高分辨率(336x336像素)的版本,并探索了将语言模型从7B扩展到13B参数,显著提升了模型在视觉对话等任务上的表现。
这些改进共同构成了LLaVA-1.5,一个仅使用约120万公开数据,在单台8-A100节点上约一天即可完成训练的高效模型。
扩展到更高分辨率 (LLaVA-1.5-HD)
为了处理超过预训练尺寸(如336x336)的更高分辨率图像,本文提出了一种无需对ViT进行位置编码插值和大规模微调的通用方法:
- 分块编码:将高分辨率大图分割成多个小图块(patch),每个图块的尺寸都符合视觉编码器原始的输入要求。
- 独立处理: 独立地对每个图块进行编码,得到各自的特征图。
- 合并与全局上下文: 将所有图块的特征图合并成一个大的特征序列。同时,将原始大图缩放到一个较低分辨率(如224x224),编码后作为一个“全局上下文”特征,与分块特征拼接在一起,共同送入LLM。
这种策略使得模型可以处理任意分辨率的输入,同时保持了LLaVA-1.5的数据效率,并有效地提升了对图像细节的感知能力。
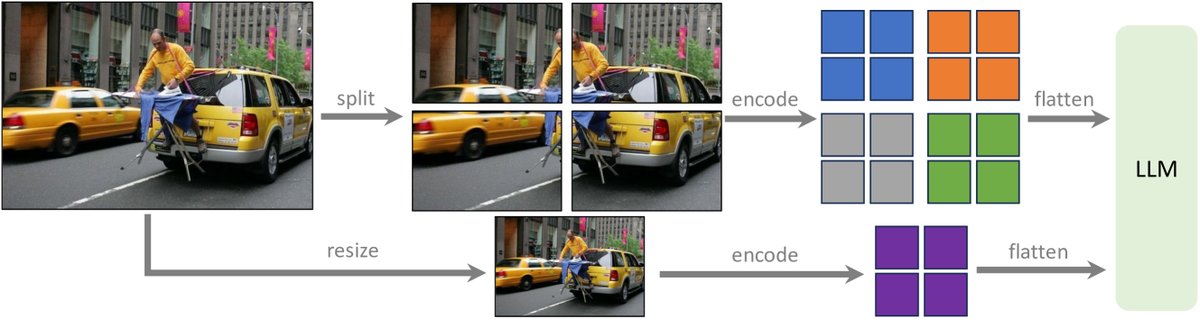 图:LLaVA-1.5-HD 通过将图像分割成网格并独立编码来扩展到更高分辨率。
图:LLaVA-1.5-HD 通过将图像分割成网格并独立编码来扩展到更高分辨率。
实验结论
LLaVA-1.5在一系列共12个基准测试中展现了卓越的性能,其结果证明了本文方法的有效性。
 图:LLaVA-1.5在11个任务上达到SOTA,并展示了高训练样本效率。
图:LLaVA-1.5在11个任务上达到SOTA,并展示了高训练样本效率。
关键实验结果
- 全面领先: 如表3和表4所示,LLaVA-1.5在11个基准测试中均取得了SOTA或接近SOTA的成绩,包括学术VQA(如VQAv2, GQA, TextVQA)、幻觉评估(POPE)、以及综合能力评测(MME, MMBench, MM-Vet)等。特别是在MMBench上,13B模型达到67.7%的准确率,显著优于先前模型。
- 卓越的数据效率: 与使用上亿甚至十亿级数据预训练的InstructBLIP和Qwen-VL相比,LLaVA-1.5(使用约60万预训练数据和约67万指令微调数据)以极少的数据量取得了更优的性能,证明了“视觉指令微调”本身的重要性可能被低估,而大规模视觉-语言对齐预训练的必要性值得重新审视。
- 高分辨率优势: LLaVA-1.5-HD通过分块处理高分辨率图像,在需要细粒度感知的任务上(如MM-Vet中的OCR和LLaVA-Wild中的细节描述)性能进一步提升。消融实验也证实,加入全局上下文特征能有效提升模型性能。
| 方法 | LLM | GQA | VisWiz | SciQA-IMG | TextVQA | POPE | MME | MMBench | MM-Vet |
|---|---|---|---|---|---|---|---|---|---|
| InstructBLIP-13B | Vicuna-13B | 49.5 | 33.4 | 63.1 | 50.7 | 77.0 | 1212.8 | - | 25.6 |
| Qwen-VL-Chat-7B | Qwen-7B | 57.5* | 38.9 | 68.2 | 61.5* | - | 1487.5 | 60.6 | - |
| LLaVA-1.5-7B | Vicuna-7B | 62.0* | 50.0 | 66.8 | 58.2 | 86.1 | 1510.7 | 64.3 | 31.1 |
| LLaVA-1.5-13B | Vicuna-13B | 63.3* | 53.6 | 71.6 | 61.3 | 86.2 | 1531.3 | 67.7 | 36.1 |
| LLaVA-1.5-13B-HD | Vicuna-13B | 64.7* | 57.5 | 71.0 | 62.5 | 86.4 | 1500.1 | 68.8 | 39.4 |
表:LLaVA-1.5与SOTA方法在多个关键基准上的性能对比(节选)。星号()表示训练集中包含该测试集的数据。*
新兴能力与发现
- 指令泛化能力: 模型能泛化到训练中未见的格式指令,如按要求输出”Unanswerable”或生成JSON格式的回答。
- 多语言能力: 尽管所有视觉指令数据均为英语,但模型(得益于ShareGPT数据)展现出令人惊讶的多语言对话能力,在中文MMBench-CN上的表现甚至超过了专门为中文优化的Qwen-VL-Chat。
- 对幻觉的新见解: 实验发现,提升输入图像的分辨率能显著减少模型产生幻觉的倾向。这表明幻觉问题不仅源于训练数据中的噪声,也与模型自身的感知能力(分辨率不足)密切相关。当模型“看不清”细节时,它更倾向于去“想象”。
- 组合能力: 模型表现出良好的能力组合性。例如,在纯文本对话(ShareGPT)和视觉问答(VQA)上分别训练后,模型能在视觉对话中展现出更强的语言表达和更准确的视觉 grounding,无需对组合任务进行显式训练。
最终结论
LLaVA-1.5凭借其简洁的架构、高效的训练策略和强大的性能,为大型多模态模型领域提供了一个可复现、可负担且极具竞争力的开源基线。该研究表明,精心设计的指令微调数据和策略,结合适度的架构与规模扩展,是打造强大LMM的关键,其重要性不亚于大规模的预训练。