Improving Context Fidelity via Native Retrieval-Augmented Reasoning
-
ArXiv URL: http://arxiv.org/abs/2509.13683v1
-
作者: Bang Liu; Xiao-Wen Chang; Xiangru Tang; Jinlin Wang; Shiqi Li; Xinyu Wang; Suyuchen Wang; Sirui Hong; Chenglin Wu
-
发布机构: CIFAR; McGill University; MetaGPT; Mila - Quebec AI Institute; Université de Montréal; Yale University
TL;DR
本文提出了一种名为CARE的新型原生检索增强推理框架,通过教导大型语言模型(LLM)在推理链中动态地从输入上下文中检索并整合证据,以解决上下文失真问题,从而在无需昂贵外部工具的情况下显著提升答案的准确性和忠实度。
关键定义
- 上下文忠实度 (Context Fidelity):指大型语言模型生成的答案与所提供的上下文信息保持一致、不产生矛盾或捏造事实的能力。这是评估知识密集型任务中模型可靠性的一个核心指标。
- 原生检索增强推理 (Native Retrieval-Augmented Reasoning):本文提出的核心范式。它指模型利用其固有的语言理解能力,直接从给定的输入上下文中识别和提取相关证据,并将其无缝地整合到自身的推理步骤中。这种方法与依赖外部索引、向量数据库或API调用的传统检索增强生成(RAG)形成对比。
- CARE (Context-Aware Retrieval-Enhanced reasoning):本文提出的框架,是“原生检索增强推理”范式的具体实现。它通过一个两阶段训练过程(监督微调+强化学习)和课程学习策略,教会模型在生成答案时,主动地在推理过程中引用上下文证据,从而提升回答的质量和可信度。
相关工作
当前,提升大型语言模型(LLM)在问答任务中表现的方法主要有两类。第一类是通过链式思考(Chain of Thought, CoT)等提示工程策略来增强模型的推理能力,但这些方法在处理长篇或含噪声的上下文时,仍难以保证对上下文的忠实度。
第二类是检索增强生成(Retrieval-Augmented Generation, RAG)。传统RAG方法通过从外部知识库检索信息来辅助生成,但这通常需要额外的模块(如向量数据库)和复杂的流程,增加了系统延迟和架构的冗余。并且,这些方法往往优先利用外部知识,可能忽略了用户在输入中已经提供的、最直接相关的上下文信息。
现有研究的主要瓶颈在于,检索过程和推理过程通常是分离的,导致模型无法灵活、动态地将检索到的信息与自身的推理逻辑深度结合。
本文旨在解决的核心问题是上下文幻觉 (context hallucination),即LLM在回答问题时生成与给定上下文相悖或无关的内容。具体而言,本文致力于在不依赖外部检索工具的前提下,教会模型如何更有效地利用输入上下文,通过在推理过程中显式地引用证据来保证答案的忠实度。
本文方法
本文提出了CARE(Context-Aware Retrieval-Enhanced reasoning)方法,一个旨在让LLM通过自身“原生”能力从输入上下文中进行检索,并将检索到的证据整合进推理过程的框架。其核心思想是,通过特定的训练使模型学会一种新的生成格式:在思考和推理的同时,显式地引用上下文中的事实依据。

Figure 1: 直接生成、基于推理的生成以及集成上下文事实的推理之间的比较。
CARE框架包含一个两阶段的训练过程:监督微调(SFT)和强化学习(RL)。
监督微调(SFT)阶段:学习证据整合的格式
此阶段的目标是让模型“冷启动”,熟悉在推理链中插入证据的目标输出格式。这依赖于一个自建的、包含证据标注的SFT数据集。
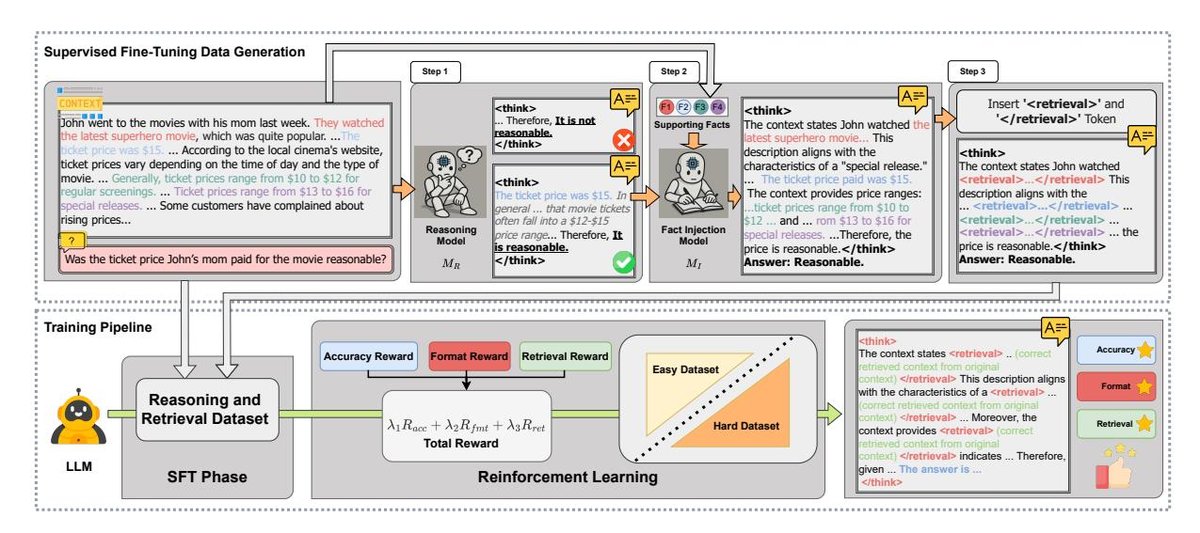
Figure 2: CARE的训练数据创建和两阶段训练过程图示。上部描绘了SFT数据生成流程,包括事实注入和在推理内容中插入特殊token。下部展示了SFT训练和带有多种奖励的强化学习(RL)训练。
SFT数据的生成流程如上图所示,包含三个步骤:
- 推理步骤生成:利用一个强大的推理模型($M_R$),基于原始数据集中的上下文($C_i$)和问题($Q_i$),生成初步的推理链($R_{i,A}$)。
- 证据集成:使用一个事实注入模型($M_I$),将数据集中预先标注的黄金标准支持事实($S_i$)无缝地编织进第一步生成的推理链中,得到一个与上下文证据更对齐的推理链($R_{i,I}$)。
- 检索Token插入:在集成证据的推理链中,用特殊的标记 \(<RETRIEVAL>\) 和 \(</RETRIEVAL>\) 将引用的证据文本包裹起来,形成最终的SFT训练样本。
通过这个流程,模型学习到了一个标准化的输出格式,即在\(<THINK>\)…\(</THINK>\)的推理过程中穿插\(<RETRIEVAL>\)…\(</RETRIEVAL>\)的证据引用。
强化学习(RL)阶段:优化自检索机制
在模型通过SFT掌握了基本格式后,RL阶段通过更复杂的奖励机制和学习策略来进一步优化其自检索和推理能力。此阶段不再需要带有黄金证据标注的数据。
优化算法:本文采用组相对策略优化(Group Relative Policy Optimization, GRPO)算法。该算法通过对一组采样的输出进行整体评估来更新策略,可以更稳定地优化模型。其目标函数如下:
\[J_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim \mathcal{D}, \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}(\cdot \mid q)}} \left[ \dots - \beta D_{\text{KL}}\left(\pi_{\theta} \parallel \pi_{\text{ref}}\right) \right]\]其中包含重要性比率、优势函数以及一个KL散度正则项,以防止模型偏离原始策略太远。
奖励设计:RL阶段的奖励函数是CARE方法成功的关键,它由三部分加权组成:
\[R_{\text{total}} = \lambda_1 R_{\text{acc}} + \lambda_2 R_{\text{fmt}} + \lambda_3 R_{\text{ret}}\]- $R_{\text{acc}}$ (准确性奖励):衡量最终答案与标准答案的F1分数。
- $R_{\text{fmt}}$ (格式奖励):鼓励模型生成符合 \(<THINK>\) 和 \(<RETRIEVAL>\) 规范的结构化输出。
- $R_{\text{ret}}$ (检索奖励):这是核心创新之一。该奖励会检查模型在 \(<RETRIEVAL>\) 标签内生成的内容是否存在于原始输入上下文中。只要存在,模型就会获得正向奖励。这个设计十分巧妙,因为它在不依赖黄金证据标签的情况下,有效地激励模型从上下文中引用内容。
课程学习策略:为了让模型能处理从简单到复杂的各种问答场景,本文设计了一种课程学习策略。训练初期,模型主要学习简单、短上下文的数据集($\mathcal{D}_{easy}$),然后逐渐增加复杂、长上下文、多跳推理的数据集($\mathcal{D}_{hard}$)的比例。这一策略帮助模型在不发生灾难性遗忘的情况下,平滑地提升处理复杂任务的能力。
Algorithm 1: 使用CARE奖励的课程强化学习
- 输入: 简单数据集 $\mathcal{D}_{easy}$, 困难数据集 $\mathcal{D}_{hard}$, 策略 $\pi_{\theta}$, KL系数 $\beta$ 等
- 过程:
- 在每个训练步骤中,根据一个随时间递减的比例 $\alpha$ 从 $\mathcal{D}_{easy}$ 或 $\mathcal{D}_{hard}$ 中采样问题。
- 从当前策略中采样多个输出 $o_i$。
- 对每个输出,提取其检索片段 $S$,并根据公式(6)计算总奖励 $R_{\text{total}}$。
- 使用GRPO算法和计算出的奖励来更新策略参数 $\theta$。
- 调整课程学习的混合比例 $\alpha$。
- 输出: 更新后的策略参数 $\theta$。
创新点
- 原生检索:最大的创新在于“原生检索”概念,即LLM自身学会了从上下文中提取证据,而无需任何外部工具或数据库,简化了系统架构,降低了延迟。
- 训练范式:结合SFT和RL的两阶段训练范式,以及巧妙的检索奖励($R_{\text{ret}}$)设计,使得模型能够在没有大量证据标注数据的情况下学会忠实于上下文。
- 课程学习:通过课程学习策略,模型的能力可以从简单任务泛化到复杂任务,增强了方法的通用性和鲁棒性。
实验结论
本文在一系列真实世界和反事实问答(QA)基准上进行了广泛实验,证明了CARE方法的有效性。
问答性能
| Model | Method | MFQA | HotpotQA | 2WikiMQA | MuSiQue | Average |
|---|---|---|---|---|---|---|
| Original | 45.57 | 54.64 | 45.87 | 32.08 | 44.54 | |
| LLaMA-3.1 8B | R1-Searcher | 28.44 | 53.71 | 67.10 | 41.41 | 47.67 |
| CRAG | 44.04 | 37.88 | 25.95 | 24.10 | 32.99 | |
| CARE | 49.94 | 63.09 | 75.29 | 51.00 | 59.83 | |
| Original | 46.94 | 58.47 | 46.96 | 30.78 | 45.79 | |
| Qwen2.5 7B | ReSearch | 32.45 | 54.24 | 55.78 | 47.61 | 47.52 |
| R1-Searcher | 28.36 | 55.43 | 65.79 | 47.09 | 49.17 | |
| CRAG | 47.90 | 43.97 | 33.00 | 28.44 | 38.33 | |
| CARE | 48.11 | 63.45 | 70.11 | 45.57 | 56.81 | |
| Original | 47.58 | 61.94 | 59.05 | 37.99 | 51.64 | |
| Qwen2.5 14B | CRAG | 50.89 | 44.74 | 34.68 | 28.17 | 39.62 |
| CARE | 48.81 | 67.75 | 78.68 | 51.27 | 61.63 |
Table 1: 真实世界QA数据集上的评估结果。
如上表所示,在所有测试的模型尺寸和家族中,CARE方法均显著优于基线模型(包括原始模型和各种RAG方法)。特别是在需要多跳推理的复杂任务(如2WikiMQA, MuSiQue)上,性能提升尤为明显。例如,在LLaMA-3.1 8B上,CARE的平均F1分数比原始模型高出15.29%。
反事实QA性能
| Model | Method | CofCA |
|---|---|---|
| LLaMA-3.1 8B | Original R1-Searcher CARE | 48.14 45.25 61.83 |
| Qwen2.5 7B | Original ReSearch R1-Searcher CRAG CARE | 58.38 47.32 43.61 56.01 64.56 |
| Qwen2.5 14B | Original CRAG CARE | 64.40 51.99 67.75 |
Table 2: 反事实QA任务上的评估结果。
在CofCA基准测试中,当上下文信息与模型预训练的知识相矛盾时,CARE表现出卓越的上下文忠实度,得分远超其他方法。相比之下,依赖外部搜索的方法(如ReSearch)在此任务上表现甚至不如原始模型,这凸显了CARE专注于内部上下文的优势。
消融研究与证据检索评估
| Settings | SFT | RL | Ret. | Cur. | MFQA | HotpotQA | 2WikiMQA | MuSiQue | CofCA | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | ✗ | ✗ | ✗ | ✗ | 46.64 | 58.47 | 46.96 | 30.78 | 58.38 | 48.25 |
| SFT Only | ✓ | ✗ | ✗ | ✗ | 42.24 | 47.08 | 61.51 | 33.82 | 59.21 | 48.77 |
| No Ret. | ✓ | ✓ | ✗ | ✗ | 37.66 | 62.59 | 70.57 | 43.85 | 57.26 | 54.39 |
| No Cur. | ✓ | ✓ | ✓ | ✗ | 38.33 | 64.10 | 70.69 | 47.49 | 60.60 | 56.24 |
| CARE | ✓ | ✓ | ✓ | ✓ | 48.11 | 63.45 | 70.11 | 45.57 | 64.56 | 58.36 |
Table 3: 基于Qwen2.5 7B的消融研究。”Ret.”代表检索奖励,”Cur.”代表课程学习。
- 消融研究证实了CARE框架各个组成部分的必要性。仅SFT效果有限;RL训练是性能提升的关键;而检索奖励(Ret.)和课程学习(Cur.)的引入进一步显著增强了模型的性能和泛化能力。
- 证据检索评估显示,在提取支持性事实上,CARE模型的BLEU和ROUGE-L分数也最高,证明它不仅答案更准,而且能更精确地找到支持答案的证据。
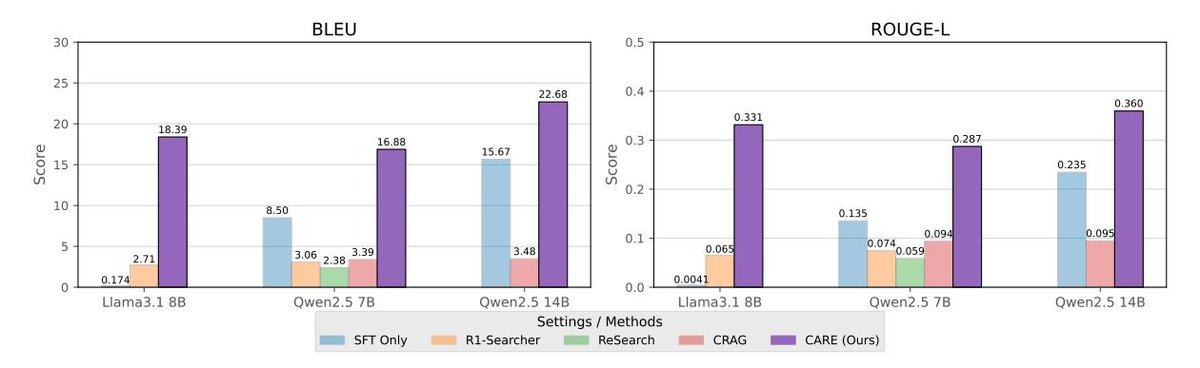 Figure 3: 不同设置下模型在BLEU和ROUGE-L指标上的性能比较。
Figure 3: 不同设置下模型在BLEU和ROUGE-L指标上的性能比较。
最终结论:CARE框架通过其新颖的“原生检索增强推理”机制,成功地提升了LLM的上下文忠实度和问答准确性。它在多种复杂问答场景下均表现出色,尤其擅长处理需要依赖长上下文进行多步推理的任务,为构建更可靠、更高效的知识密集型AI系统提供了一条有效路径。