Inefficiencies of Meta Agents for Agent Design
-
ArXiv URL: http://arxiv.org/abs/2510.06711v1
-
作者: Mert Yuksekgonul; James Zou; Batu El
-
发布机构: Stanford University
TL;DR
本文通过实验揭示了一类流行的元智能体(meta-agent)在自动化智能体设计中存在的三个核心问题:学习效率低下、生成的智能体多样性不足以及经济可行性有限,并发现进化式上下文策展策略可以有效提升性能。
关键定义
本文沿用了现有智能体设计的研究设定,并在此框架下提出了以下对理解本文至关重要的核心概念:
-
元智能体 (Meta-Agent): 指一个能够自动化设计、评估和迭代优化其他智能体(agent)的系统。本文聚焦于遵循“采样-评估-迭代”模式的元智能体,它们通过与语言模型交互来生成智能体代码。
-
上下文策展 (Context Curation, $\phi$): 在元智能体生成新智能体的过程中,从已有智能体档案库中选择一部分作为上下文(prompt)提供给语言模型的过程。本文的核心是比较三种不同的策展策略:
- 累积式 (Cumulative): 将所有先前设计和评估过的智能体都放入上下文,是先前研究中使用的方法。
- 并行式 (Parallel): 完全忽略新设计的智能体,每次生成都只使用最初始的智能体库作为上下文。
- 进化式 (Evolutionary): 仅选择档案库中迄今为止表现最好的少数几个智能体(“父代”)作为上下文,来生成新的智能体。
相关工作
当前,利用语言模型实现复杂任务的智能体系统已成为研究热点。遵循机器学习领域的“惨痛教训 (Bitter Lesson)”,即通用、可扩展的计算方法最终会胜过手动设计,近期研究(如 ADAS, MAS-GPT, AutoFlow 等)开始探索使用元智能体来自动化智能体架构的设计过程。
这些方法大多遵循一个“采样-评估-迭代” (sample–evaluate–iterate) 的范式:元智能体提出新的智能体设计,对其进行评估,然后根据反馈进行下一轮迭代。然而,这种自动化设计范式的实际效率和效益尚未得到充分检验。
本文旨在解决以下三个具体问题:
- 元智能体是否能有效地从过往的设计经验中学习?
- 元智能体设计出的多个候选智能体是否具有行为多样性,从而可以互补使用?
- 自动化智能体设计在何种情况下才具备经济可行性,即其带来的性能提升是否能抵消其高昂的设计成本?
本文方法
本文的研究方法建立在一个通用的元智能体设计框架之上,该框架遵循“采样-评估-迭代”循环。其核心贡献在于对该框架中的上下文策展 (Context Curation) 环节进行了系统性的比较和分析。
## 智能体设计框架
整个设计流程如算法所示。系统维护一个档案库 \(A\),其中存储了所有已发现的智能体 \(f_i\) 及其在训练集 \(D_train\) 上的评估得分 \(s_i\)。
- 初始化: 从一个初始智能体库 \(F\) 开始,填充档案库 \(A\)。
- 迭代循环: 在每次迭代 \(t\) 中: a. 策展 (Curation): 使用策展函数 \($\phi\)$ 从档案库 \(A\) 中选择一个子集 \($\hat{A}\)$。 b. 采样 (Sampling): 以 \($\hat{A}\)$ 为条件,通过语言模型 \($\Pi(\cdot \mid \hat{A})\)$ 生成一个新的智能体代码 \(f_t\)。 c. 评估 (Evaluation): 在训练集上评估新智能体 \(f_t\) 的性能,得到分数 \(s_t\)。 d. 更新 (Update): 将新的智能体对 \($(f\_t, s\_t)\)$ 添加到档案库 \(A\) 中。
## 创新点:三种上下文策展策略
本文的创新之处在于系统地研究了策展函数 \($\phi\)$ 的不同实现方式,而非提出一个全新的智能体框架。通过对比以下三种策略,本文揭示了元智能体学习效率的关键影响因素:
-
累积式 (Cumulative): \($\phi\_C\)$ 直接使用全部历史智能体作为上下文(\($\hat{A} = A\)$)。这是先前工作(如 ADAS)采用的直接方法,其假设是“信息越多越好”。
-
并行式 (Parallel): \($\phi\_P\)$ 在任何迭代中都只使用最初始的7个智能体作为上下文。这种策略下,每次智能体生成都是独立的,忽略了迭代过程中产生的新智能体。它作为一个关键的对照组,用于检验从新智能体中学习是否真的带来了好处。
-
进化式 (Evolutionary): \($\phi\_E\)$ 从档案库 \(A\) 中选出表现最好的7个智能体作为“父代”,并将它们提供给语言模型作为上下文。这借鉴了进化算法的思想,即只从最优的个体中学习和繁衍,旨在将搜索引向更高质量的设计空间。
通过在数学推理(MGSM)、阅读理解(DROP)、多任务问答(MMLU)和科学问答(GPQA)等多个基准任务上对比这三种策略,本文得以深入剖析元智能体设计的内部机制和效率瓶颈。
实验结论
## 学习效率
实验结果表明,简单地将所有历史信息累积起来作为上下文效果不佳。
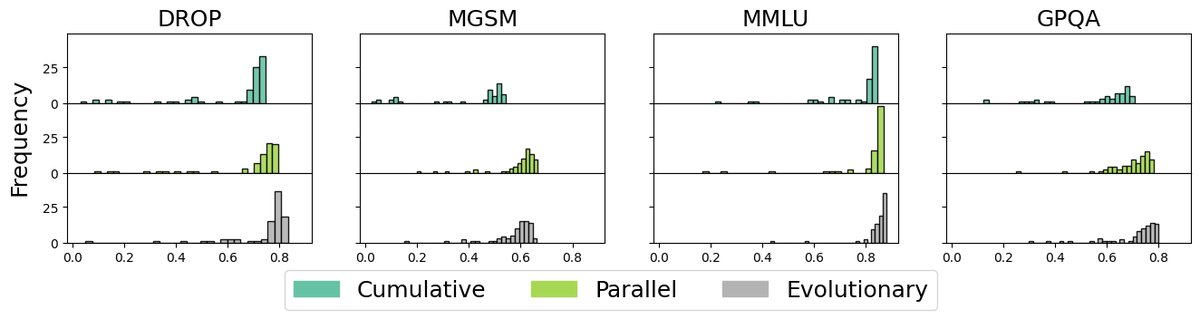
- 累积式策略表现最差:在所有任务中,累积式上下文策展的表现甚至不如完全忽略历史设计的并行式策略。这表明,未经筛选地增加上下文信息会对元智能体的设计过程产生负面影响,可能引入了过多的噪声。
- 进化式策略显著提升性能:与累积式策略相比,进化式策略在MGSM等任务上带来了高达10%的性能提升。这证明了选择性地只关注高质量的先前设计(即“精英”)是促进元智能体有效学习的关键。
## 多样性与互补性
本文通过计算不同智能体在训练集上解答正确性向量的余弦相似度来衡量它们的行为多样性。
- 生成智能体多样性低:总体而言,元智能体设计的智能体之间行为相似度很高,意味着它们倾向于解决同一批问题,缺乏互补性。
- 性能与多样性的权衡:进化式策略虽然性能最高,但其生成的智能体相似度也最高(多样性最低)。相反,并行式策略在性能稍逊于进化式的情况下,产生了更多样化的智能体,并在“覆盖率”(至少有一个智能体能解决的问题比例)指标上取得了最高分。这揭示了在优化单一最佳智能体性能和生成多样化智能体池之间的权衡。
## 经济可行性
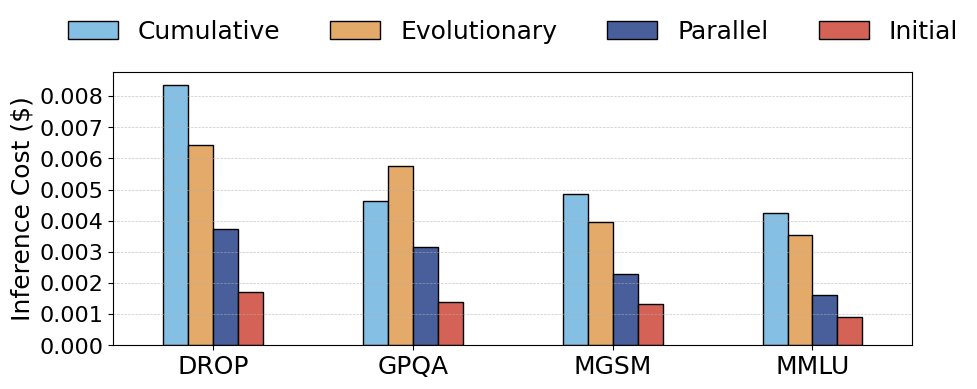
本文分析了自动化设计的总成本,包括固定的设计成本(\($C\_0\)$,包含所有采样和评估开销)和可变的推理成本(\($n \cdot C\_j\)$,其中\(n\)是部署样本数)。
- 设计成本高昂:元智能体设计过程本身成本很高。同时,设计出的智能体平均单次推理成本也普遍高于初始库中的手动设计智能体。
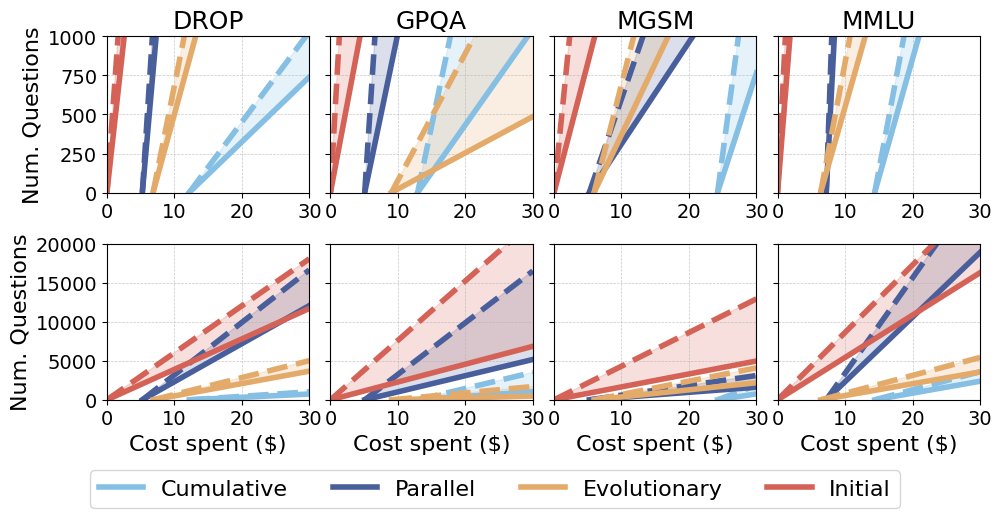
- 收支平衡点难以达到:只有在极少数情况下,自动化设计的收益才能抵消其成本。具体而言,仅在DROP和MMLU数据集上,使用并行式策略设计的智能体在部署规模超过约15,000个样本后,其“每解决一个问题的成本”才开始低于手动设计的智能体。对于其他数据集和策展方法,无论部署规模多大,自动化设计的成本都无法被其有限的性能增益所证明是合理的。
## 总结
本文的分析揭示了当前一类元智能体设计方法的关键低效之处。最终结论是:
- 学习方式至关重要:简单的信息累积有害无益,而受进化启发的选择性学习能显著提升性能。
- 存在关键权衡:在追求最高性能(进化式)与生成多样化智能体(并行式)之间存在权衡;在追求性能提升与控制高昂的设计和推理成本之间也存在权衡。
- 经济可行性有限:在多数情况下,自动化智能体设计带来的性能增益尚不足以覆盖其高昂的成本,其实用价值目前仅限于特定任务和大规模部署场景。