InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
-
ArXiv URL: http://arxiv.org/abs/2305.06500v2
-
作者: A. M. H. Tiong; Pascale Fung; Junnan Li; Junqi Zhao; Weisheng Wang; Wenliang Dai; Steven C. H. Hoi; Boyang Albert Li; Dongxu Li
-
发布机构: Hong Kong University of Science and Technology; Nanyang Technological University; Salesforce Research
TL;DR
本文提出了InstructBLIP,一个基于预训练模型BLIP-2的视觉语言指令微调框架,通过引入一个创新的指令感知查询转换器(Q-Former),使模型能根据文本指令提取相应的视觉特征,从而在广泛的未见过的视觉语言任务上实现了最先进的零样本(zero-shot)泛化能力。
关键定义
- 视觉语言指令微调 (Vision-Language Instruction Tuning):一种训练范式,通过在大量由自然语言指令描述的、多样化的视觉语言任务上对模型进行微调,使其能够理解并执行任意给定的指令,从而提升对未见任务的泛化能力。
- InstructBLIP: 本文提出的模型框架,它在BLIP-2的基础上进行指令微调。其核心架构包括一个冻结的图像编码器、一个冻结的大语言模型(LLM),以及一个可训练的、用于连接两者的查询转换器(Q-Former)。
- 指令感知的Q-Former (Instruction-aware Q-Former):这是InstructBLIP的核心技术创新。与BLIP-2不同,这个Q-Former不仅接收图像特征,还接收任务指令的文本Token作为输入。通过内部的自注意力机制,指令可以引导Q-Former从图像中提取与当前任务最相关的视觉特征,再将这些“指令感知”的特征输入给LLM。
- 训练集内/外数据集 (Held-in / Held-out Datasets):本文为评估模型的零样本泛化能力而采用的数据划分策略。模型在13个“训练集内”数据集上进行训练,然后在另外13个模型从未见过的“训练集外”数据集上进行零样本评估。这种评估方式能有效检验模型的泛化水平。
相关工作
当前构建通用视觉语言模型的尝试主要面临两大挑战:输入(图像)分布的丰富性和任务的多样性。
现有的研究路径可分为两类:
- 多任务学习 (Multitask Learning):将不同的视觉语言任务统一为相同的输入输出格式进行训练。然而,实验发现,不带指令的多任务学习在未见过的任务上的泛化能力很差。
- 扩展预训练LLM: 将预训练的LLM与视觉模块结合,并使用图像描述数据进行训练。例如BLIP-2,它展示了初步遵循指令的能力。但仅依赖图像描述数据,其能力被局限于内容描述,难以泛化到需要更复杂推理的视觉语言任务。
本文旨在解决上述问题,即如何通过指令微tuning来构建一个能够泛化到大量未见过的、多样的视觉语言任务的单一模型。
本文方法
InstructBLIP的整体框架建立在BLIP-2之上,但通过引入指令感知机制和优化的训练策略,显著提升了模型的泛化能力。
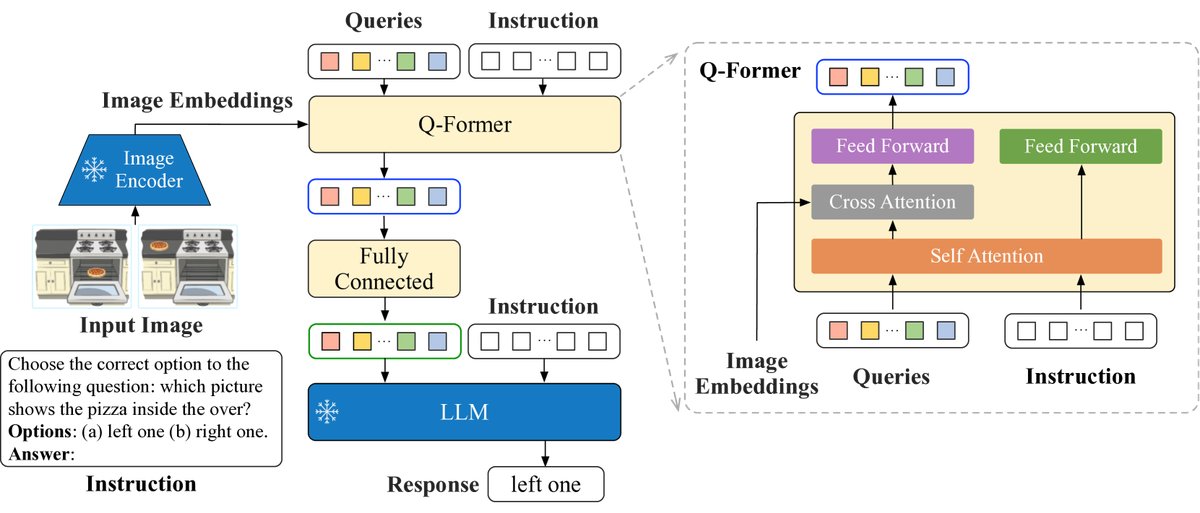
创新点
本文方法的核心创新在于指令感知的视觉特征提取(Instruction-aware Visual Feature Extraction)。
传统的模型(如BLIP-2)在提取视觉特征时是“指令无关”的,即无论任务指令是什么,同一张图片生成的视觉特征都是静态的。这限制了模型针对不同任务调整其“注意力”的能力。
InstructBLIP对此进行了改进:
- 架构设计:模型由一个冻结的图像编码器(ViT-g/14)、一个冻结的LLM(如FlanT5或Vicuna)和一个可训练的Q-Former组成。
- 指令注入:关键在于,任务指令的文本Token不仅被送入LLM,也被送入Q-Former。
- 特征提取:在Q-Former内部,指令Token与可学习的查询嵌入(query embeddings)通过自注意力层进行交互。这使得Q-Former能够根据指令的引导,有选择性地从图像编码器输出的特征中提取与任务最相关的信息。
- 优点:最终,Q-Former输出的是一组“为指令量身定制”的视觉特征,这些特征作为软提示(soft prompt)被输入LLM。这种动态的、与任务相关的特征提取方式,使得模型能更好地遵循指令并完成多样化的任务。
训练数据与策略
为了实现强大的泛化能力,本文在数据和训练层面也进行了系统性设计。
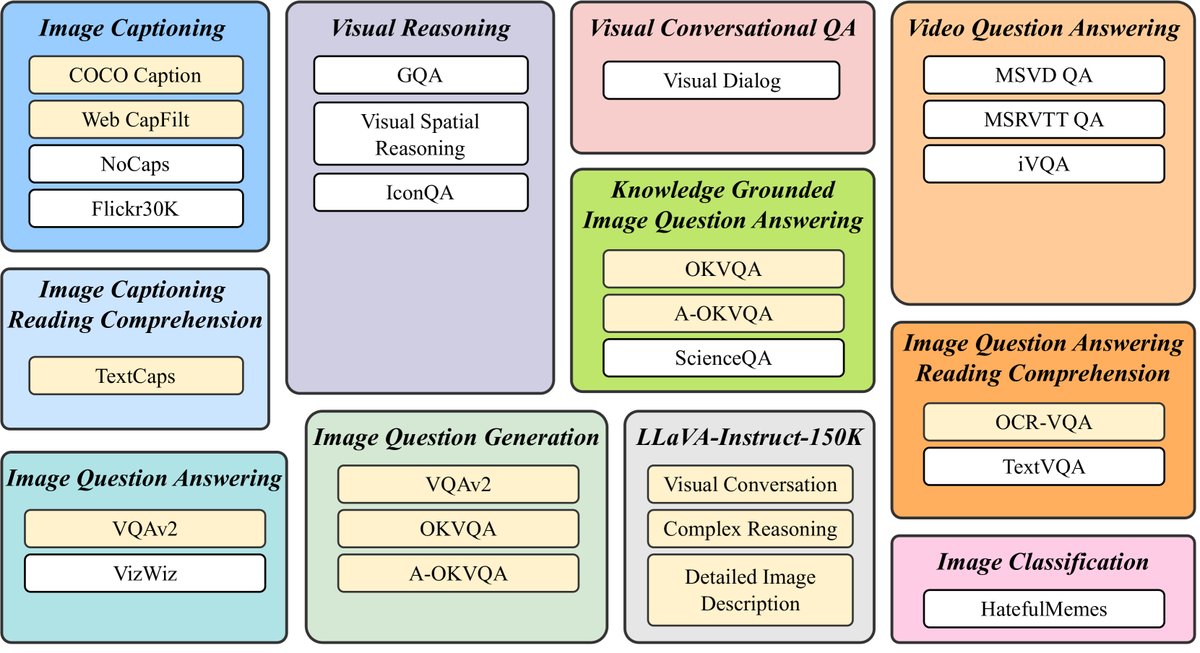
- 大规模、多样化的指令数据集:
- 本文收集并整理了26个公开的视觉语言数据集,覆盖了图像描述、视觉问答、视觉推理、视频问答、视觉对话等11个大类任务。
- 为每个任务精心设计了10-15个不同的指令模板,将这些数据集统一转换为指令微调格式。
- 这种数据多样性是模型泛化能力的基础。
- 平衡的数据集采样策略 (Balancing Training Datasets):
- 由于不同数据集的规模差异巨大,均匀混合会导致模型在小数据集上过拟合,在大数据集上欠拟合。
-
本文提出一种加权采样策略,即从每个数据集中采样的概率与其样本数量的平方根成正比:
\[p_{d} = \frac{\sqrt{S_{d}}}{\sum_{i=1}^{D}\sqrt{S_{i}}}\]其中,$S_d$ 是数据集 $d$ 的大小。
- 这种策略有助于同步不同任务的学习进度,提升整体性能。
推理方法
根据任务类型,本文采用两种不同的推理策略:
- 直接生成:对于图像描述、开放式问答等任务,模型直接生成文本答案。
- 词汇表排序 (Vocabulary Ranking):对于分类、多项选择问答等任务,模型被限制在候选答案的词汇表中生成,通过计算每个候选答案的对数似然(log-likelihood),选择得分最高的作为最终预测。这提升了在封闭集问题上的准确性。
实验结论
InstructBLIP在大量的实验中展示了其卓越的性能,尤其是在零样本泛化方面。

零样本评估
- SOTA性能:在13个Held-out(训练时未见过)数据集的零样本评测中,InstructBLIP在所有数据集上均取得了新的SOTA,全面且大幅超越了其基座模型BLIP-2以及参数量更大的Flamingo模型。例如,InstructBLIP (FlanT5XL) 相比BLIP-2 (FlanT5XL) 平均相对提升了15.0%。
- 跨任务泛化:尤其在视频问答等模型从未见过的任务类型上,InstructBLIP也表现出色,例如在MSRVTT-QA上相对SOTA提升了47.1%,证明了指令微调带来的强大泛化能力。
| 模型 | NoCaps | Flickr30K | GQA | VSR | IconQA | TextVQA | Visdial | HM | VizWiz | SciQA (image) | MSVD QA | MSRVTT QA | iVQA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo-80B | - | 67.2 | 35.0 | - | 46.4 | 31.6 | - | - | 35.6 | 17.4 | - | - | 40.7 |
| BLIP-2 (FlanT5XXL) | 98.4 | 73.7 | 44.6 | 46.9 | 52.0 | 29.4 | 64.5 | 34.4 | 44.1 | 68.2 | 17.4 | - | 45.8 |
| InstructBLIP (FlanT5XL) | 119.9 | 84.5 | 48.4 | 46.6 | 56.6 | 32.7 | 70.4 | 43.4 | 46.6 | 64.8 | 25.0 | 50.0 | 53.1 |
| InstructBLIP (FlanT5XXL) | 120.0 | 83.5 | 47.9 | 48.5 | 54.1 | 30.9 | 70.6 | 44.3 | 46.6 | 65.6 | 25.6 | 51.2 | 53.8 |
| InstructBLIP (Vicuna-7B) | 123.1 | 82.4 | 49.2 | 45.2 | 59.6 | 34.5 | 60.5 | 41.8 | 50.1 | 54.3 | 22.1 | 43.1 | 52.2 |
| InstructBLIP (Vicuna-13B) | 121.9 | 82.8 | 49.5 | 45.4 | 57.5 | 33.4 | 63.1 | 41.2 | 50.7 | 52.1 | 24.8 | 44.8 | 51.0 |
消融研究
- 指令感知的重要性:移除指令感知特征提取模块后,模型性能在所有数据集上都出现了显著下降,尤其是在需要空间或时间推理的任务上(如ScienceQA, iVQA),证明了该模块的核心价值。
- 数据平衡策略的有效性:移除数据平衡采样策略后,模型在多个数据集上的性能均有下降,说明该策略对于稳定训练和提升整体泛化能力至关重要。
| 模型 | Held-in 平均分 | GQA | ScienceQA | IconQA | VizWiz | iVQA |
|---|---|---|---|---|---|---|
| InstructBLIP (FlanT5XL) | 94.1 | 48.4 | 70.4 | 50.0 | 32.7 | 53.1 |
| w/o 指令感知特征 | 89.8 | 45.9 ($\downarrow$2.5) | 63.4 ($\downarrow$7.0) | 45.8 ($\downarrow$4.2) | 25.1 ($\downarrow$7.6) | 47.5 ($\downarrow$5.6) |
| w/o 数据平衡 | 92.6 | 46.8 ($\downarrow$1.6) | 66.0 ($\downarrow$4.4) | 49.9 ($\downarrow$0.1) | 31.8 ($\downarrow$0.9) | 51.1 ($\downarrow$2.0) |
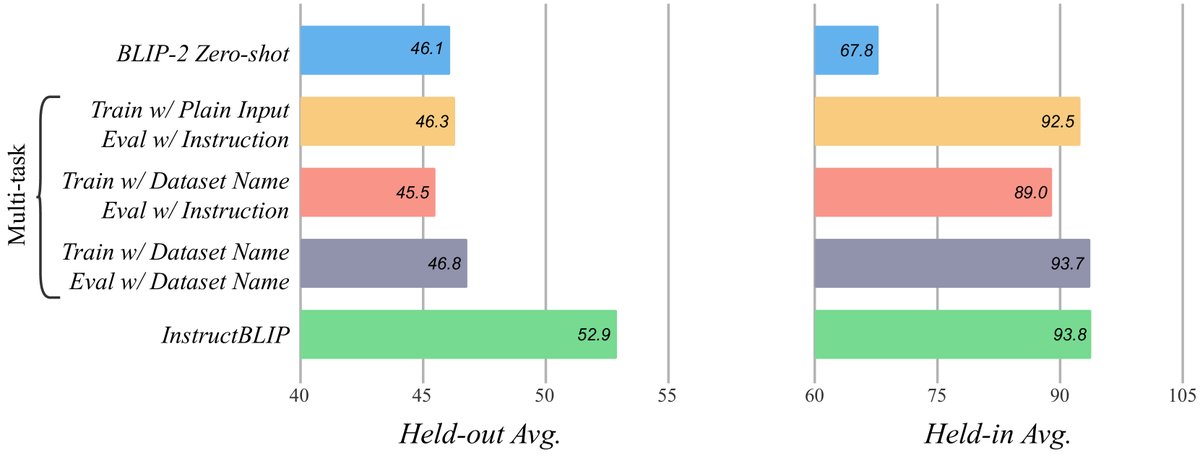
与多任务学习的对比
实验证明,指令微调是提升零样本泛化能力的关键。与不带指令的多任务学习相比,虽然两者在训练集内数据集上表现相似,但在未见过的Held-out数据集上,指令微调的效果远超多任务学习。这表明,自然语言指令本身为模型提供了泛化到新任务的必要线索。
下游任务微调
- InstructBLIP不仅零样本能力强,作为下游任务的预训练模型也更优越。在对特定任务进行微调时,InstructBLIP的性能全面超越BLIP-2,并在ScienceQA、OCR-VQA、A-OKVQA等数据集上刷新了SOTA记录。
- 值得注意的是,这一成果是在冻结图像编码器、仅微调Q-Former(188M参数)的情况下实现的,极大地提高了微调效率。
| 模型 | ScienceQA IMG | OCR-VQA | OKVQA (Test) | A-OKVQA (Test) |
|---|---|---|---|---|
| BLIP-2 (FlanT5XXL) | 89.5 | 72.7 | 57.1 | 76.2 |
| InstructBLIP (FlanT5XXL) | 90.7 | 73.3 | 57.1 | 76.7 |
| BLIP-2 (Vicuna-7B) | 77.3 | 69.1 | 60.0 | 69.0 |
| InstructBLIP (Vicuna-7B) | 79.5 | 72.8 | 64.0 | 73.4 |
总结
本文通过系统性的研究和实验,证明了视觉语言指令微调是构建通用多模态模型的有效路径。其提出的InstructBLIP框架,特别是指令感知的Q-Former,有效提升了模型对未见任务的零样本泛化能力,并在多个基准上取得了SOTA性能,为未来的通用多模态AI研究开辟了新的方向。