Internalizing World Models via Self-Play Finetuning for Agentic RL
-
ArXiv URL: http://arxiv.org/abs/2510.15047v1
-
作者: Zian Wang; Tongyao Zhu; Shiqi Chen; Junxian He; Siyang Gao; Yee Whye Teh; Kangrui Wang; Manling Li; Teng Xiao; Jinghan Zhang
-
发布机构: Allen Institute for AI; City University of Hong Kong; National University of Singapore; Northwestern University; Oxford University; The Hong Kong Polytechnic University; The Hong Kong University of Science and Technology; University of Washington
TL;DR
本文提出了一种名为 SPA (Self Play Agent) 的智能体强化学习框架,它通过自我博弈(Self-Play)有监督微调(SFT),让大语言模型智能体在策略优化前先内化一个世界模型(World Model),从而显著提升其在分布外(OOD)环境中的学习性能和泛化能力。
关键定义
- 世界模型 (World Model): 指智能体对环境底层规则的结构化理解。本文将其分解为两个部分:对当前状态的准确表征(状态估计),以及对行为如何改变状态的理解(转移建模)。
- SPA (Self Play Agent): 本文提出的核心框架。它采用一个两阶段流程:首先,通过自我博弈和有监督微调(SFT)进行“冷启动”,让智能体学习环境的世界模型;然后,利用这个预训练好的模型进行后续的强化学习(RL)策略优化。
- 状态估计 (State Estimation): 世界模型的组成部分之一。指将环境的原始、符号化观测(如纯文本棋盘)转换为结构化的、包含关键信息(如对象坐标)的自然语言描述。此举旨在降低模型理解状态的困惑度(Perplexity),增强其对环境的“接地”(Grounding)能力。
- 转移建模 (Transition Modeling): 世界模型的另一组成部分。指通过学习状态转移核函数 $p_{\theta}(s_{t+1}\mid s_{t},a_{t})$ 来预测在当前状态 $s_t$ 执行动作 $a_t$ 后,环境将转换到的下一状态 $s_{t+1}$。本文通过在自我博弈数据上进行 SFT 来实现这一点。
- Pass@k: 一项关键评估指标,衡量在 $k$ 次采样轨迹中至少有一次成功的概率。它反映了智能体生成多样化成功解法的能力,与仅衡量最高概率路径成功率的 Pass@1 形成对比。
相关工作
目前,基于强化学习(RL)的智能体微调已成为优化大型语言模型(LLM)的主流框架,在工具使用、网页搜索等领域取得了成功。
然而,当这些智能体被部署到其预训练数据之外的分布外(Out-of-Distribution, OOD)环境(如 Sokoban、FrozenLake 等)时,其性能会急剧下降。在这些环境中,模型难以将其内部知识与陌生的环境动态相结合。标准的 RL 训练往往会失败,表现为 \(Pass@k\) 指标在训练过程中不升反降,这揭示了现有方法的根本局限性:智能体仅学会了在一两条狭窄的路径上进行“利用”(Exploitation),提高了 \(Pass@1\),但未能形成对环境规则的广泛理解,导致探索能力弱,泛化性差。
本文旨在解决的核心问题是:如何让 LLM 智能体在 OOD 环境中,通过自我探索(自我博弈)先构建起对环境动态的“世界知识”,然后利用这些知识来有效行动,从而克服现有 RL 方法的局限性。
本文方法
本文提出了 SPA (Self Play Agent) 框架,其核心思想是在进行策略学习之前,先通过一个专门的阶段为 LLM 智能体构建一个内部世界模型。该框架不依赖外部知识或更强的教师模型,完全通过基础模型自身的经验来学习。
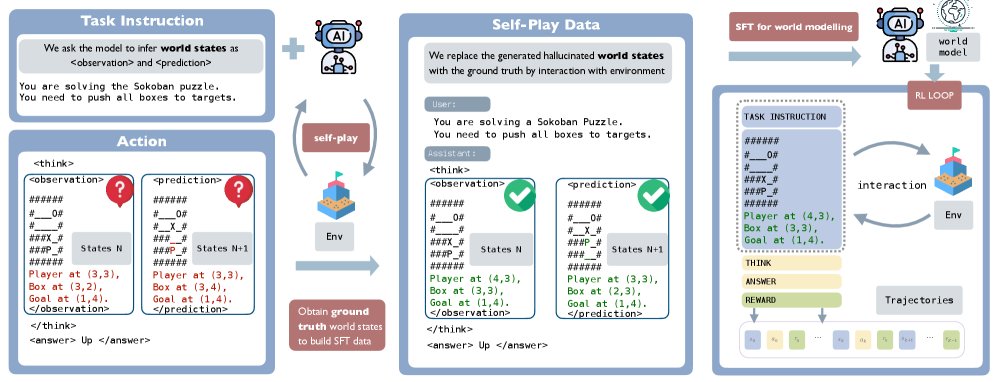
世界模型被分解为两个关键部分:状态估计和转移建模。整个流程分为三个阶段:状态估计优化、通过自我博弈微调注入转移模型、以及最终的强化学习训练。
状态估计优化
LLM 在处理 OOD 环境时的一大障碍是状态表征的分布偏移。原始的符号化状态描述(如将 Sokoban 棋盘表示为一长串字符)对于 LLM 来说难以解析,尤其是在理解空间关系时,导致状态描述的困惑度(PPL)很高。
| 任务 | PPL | 状态数(随机猜测PPL) |
|---|---|---|
| Sokoban | 163.9 | 7 |
| Frozen Lake | 187.1 | 6 |
| Sudoku | 15.5 | 5 |
| ALFWorld | 6.0 | $ \mid V \mid $ |
| WebShop | 11.7 | $ \mid V \mid $ |
为了解决这个问题,本文提出优化状态表征。具体方法是,在原始状态 $s’_{t}$ 的基础上,拼接一个结构化的、包含关键实体坐标的自然语言描述 $b_{t}$。例如,在 Sokoban 游戏中,明确描述出玩家、箱子和目标点的坐标。最终的状态表示为 $s_{t}=\text{Concat}(s’_{t},b_{t})$。这种方式能显著降低状态 PPL,为智能体提供更好的环境感知基础。
通过自我博弈微调注入转移模型
这是 SPA 框架的创新核心。在优化了状态表征后,通过一个自我博弈(Self-Play)的 SFT 过程,将环境的动态规律(即转移模型)注入到 LLM 中。
自我博弈数据生成
首先,让基础模型在环境中自由探索,生成交互轨迹 $\tau$。在每一步,模型被要求在生成可执行动作 $\hat{a}_{t}$ 之前,先进行一步“思考” $z_t$。这个思考过程被特别设计为包含了对世界模型的显式推理,即要求模型描述当前状态并预测执行动作后的下一状态:
\[z_{t} \rightarrow \text{"Think: I am at state } \hat{s}_{t}\text{. If I take action } \hat{a}_{t}\text{, I will be in state } \hat{s}_{t+1}\text{."}\]世界建模 (SFT)
数据生成后,最关键的一步是:将模型在思考过程中自己“想象”的当前状态 $\hat{s}_{t}$ 和下一状态 $\hat{s}_{t+1}$,替换为从环境中获得的真实(Ground-Truth)状态 $s_{t}$ 和 $s_{t+1}$。
然后,对这些被真实动态修正过的轨迹进行有监督微调(SFT)。训练目标是最小化一个掩码交叉熵损失,损失函数只计算“思考”部分(\(<think>\)…\(</think>\))和“答案”部分(\(<answer>\)…\(</answer>\))的 token,从而迫使模型学习环境的真实动态。
\[\mathcal{L}_{\text{W}}(\theta)=-\frac{1}{\sum_{i=1}^{T}M_{i}}\sum_{i=1}^{T}M_{i}\log p_{\theta}(\tau_{i}\mid\tau_{<i}),\]其中掩码 $M_{i}=\mathbf{1}_{[\tau_{i}\in(\text{span}(\texttt{
经过这个阶段,模型便内化了一个关于环境如何响应动作的世界模型,为后续的 RL 训练提供了一个非常强大的“冷启动”模型。
强化学习训练
在通过 SFT 获得一个具备良好世界模型的智能体后,再使用 Proximal Policy Optimization (PPO) 算法进行标准的强化学习。此时,智能体使用前面优化的状态表征 $s_t$ 来与环境交互。PPO 的目标是最大化任务奖励,其损失函数为:
\[\mathcal{J}^{\text{PPO}}(\theta)=\frac{1}{\sum_{i}M_{i}}\sum_{i}M_{i}\cdot\min\left(u_{i}(\theta)A_{i},\text{clip}(u_{i}(\theta),1-\varepsilon,1+\varepsilon)A_{i}\right),\]其中 $A_i$ 是优势函数,$u_i(\theta)$ 是新旧策略的比率。由于智能体已经对环境动态有了先验知识,RL 训练过程变得更加高效和稳定。
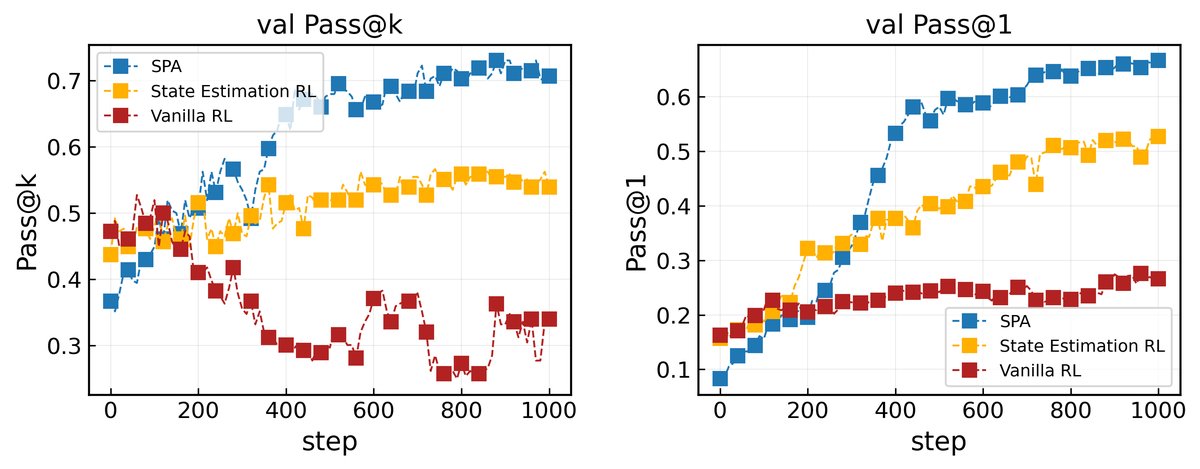
实验结论
本文在 Sokoban、FrozenLake 和 Sudoku 等多个 OOD 环境中,使用不同尺寸的模型(从 0.5B到 3B)对 SPA 框架进行了评估。
主要结果
- SPA 性能卓越:在所有评估的模型和环境中,SPA 均显著优于基线方法(Vanilla RL、仅 state-estimation 的 RL)。例如,使用 Qwen2.5-1.5B-Instruct 模型,SPA 将 Sokoban 的成功率从 25.6% 提升至 59.8%,将 FrozenLake 的分数从 22.1% 提升至 70.9%。
- 小模型超越大模型:搭载了 SPA 框架的小模型(如 1.5B)在特定任务上的表现甚至超过了强大的 20B 模型(GPT-OSS-20B),证明了内化世界模型的有效性。
- 优于在线世界模型方法:与在 RL 过程中通过奖励信号来学习世界模型的 VAGEN 方法相比,SPA 的两阶段方法(先 SFT 学模型,再 RL 学策略)表现更优。这表明将世界模型学习和策略优化解耦,可以避免多目标优化带来的干扰。
| 模型 | 方法 | Sokoban Pass@1 | Sokoban Pass@8 | FrozenLake Pass@1 | FrozenLake Pass@8 | Sudoku Pass@1 | Sudoku Pass@8 |
|---|---|---|---|---|---|---|---|
| Qwen2.5-0.5B | Vanilla RL | 10.6 | 13.9 | 10.3 | 24.1 | 5.8 | 15.6 |
| State Estimation RL | 30.2 | 34.2 | 22.1 | 48.0 | 7.9 | 19.3 | |
| SPA (本文) | 40.3 | 44.9 | 50.5 | 63.4 | 17.2 | 31.7 | |
| Qwen2.5-1.5B | Vanilla RL | 25.6 | 34.0 | 22.1 | 51.1 | 8.8 | 21.0 |
| State Estimation RL | 52.7 | 53.9 | 60.5 | 72.8 | 9.0 | 25.2 | |
| SPA (本文) | 59.8 | 69.5 | 70.9 | 83.3 | 23.5 | 45.5 | |
| … | … | … | … | … | … | … | … |
| GPT-OSS-20B | Vanilla RL | 58.7 | 63.8 | 65.6 | 73.1 | 33.3 | 52.2 |
消融研究:成功的关键因素
- 转移建模是核心:实验证明,如果在 SFT 阶段不学习状态转移(即不强制模型预测下一状态),则对后续 RL 训练没有任何提升。同时,如果 SFT 仅依赖模型自身的信念状态而非环境的真实状态,性能甚至会下降。这表明学习正确的环境动态至关重要。
- 真实状态表征不可或缺:如果为模型提供格式正确但内容随机的坐标信息,RL 训练会完全失败。这证实了准确、接地的状态表征是智能体进行空间推理和行动的基础。
- 高质量的探索策略很重要:使用随机动作生成的轨迹进行 SFT 训练,其效果远不如使用智能体自身策略生成的轨迹。这说明有目的性的探索对于收集高质量的世界模型训练数据是必要的。
- 更长的 SFT 训练有益:在世界模型 SFT 阶段投入更多的计算资源(训练更多 epochs),能持续提升后续 RL 阶段的性能和效率。

泛化与探索
- 探索-利用动态:SPA 训练过程展现出清晰的“先探索后利用”的动态。在训练早期,\(Pass@k\) 持续上升,表明智能体在广泛探索不同的解决方案;后期则转为利用,\(Pass@k\) 略有下降但仍保持高位。
- “从易到难”的泛化:在简单环境(如 4x4 的 FrozenLake)中学到的世界模型,可以被成功地迁移到更复杂的同类环境(6x6 的 FrozenLake)中,并加速其 RL 训练。这证明了世界模型具有一定的泛化能力。
最终结论 本文的 SPA 框架通过将世界模型学习(通过自我博弈 SFT)与策略优化(通过 RL)分离,为解决 LLM 智能体在 OOD 环境中的学习困境提供了一个简单而高效的解决方案。通过预先内化一个关于环境动态的内部模型,智能体获得了更强的接地能力、探索效率和泛化能力,从而在后续的 RL 任务中表现更佳。