Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
-
ArXiv URL: http://arxiv.org/abs/2302.06476v3
-
作者: Jiaao Chen; Diyi Yang; Michihiro Yasunaga; Aston Zhang; Zhuosheng Zhang; Chengwei Qin
-
发布机构: Georgia Institute of Technology; Nanyang Technological University; Shanghai Jiao Tong University; Stanford University
TL;DR
本文通过在覆盖7大类任务的20个NLP数据集上进行全面的零样本(zero-shot)评估,系统性地剖析了ChatGPT作为通用自然语言处理任务解决器的能力,发现其在推理密集型任务上表现出色,但在序列标注等特定任务上仍面临挑战,且综合性能通常不及为特定任务微调的模型。
关键定义
本文沿用了现有研究中的关键概念,对理解其评估框架至关重要:
- 零样本学习 (Zero-shot Learning): 指模型在没有任何针对下游任务的训练样本的情况下,仅通过任务指令(prompt)来解决新任务的能力。这是评估ChatGPT通用能力的核心设定。
- 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF): 训练ChatGPT所采用的关键技术。它通过收集人类对模型输出的偏好数据来训练一个奖励模型,然后使用强化学习算法优化语言模型,使其生成更符合人类偏好的内容。这是理解ChatGPT行为特性的基础。
- 思维链提示 (Chain-of-Thought (CoT) Prompting): 一种引导大语言模型在给出最终答案前,先生成中间推理步骤的方法。本文在评估推理任务时,采用了零样本CoT(例如,通过加入“Let’s think step by step”指令)来激发模型的推理潜力。
相关工作
目前,大语言模型(LLMs)已展现出强大的零样本学习能力,但其表现不稳定且高度依赖提示词设计,尚未成为真正的通用语言系统。近期发布的ChatGPT因其卓越的对话能力和基于RLHF的训练方式,引起了学术界的广泛关注。然而,它相对于现有LLMs在广泛NLP任务上的零样本泛化能力究竟如何,尚不明确。
本文旨在系统性地回答以下问题:
- ChatGPT是否是一个通用的NLP任务解决器?
- 它在哪些类型的任务上表现优异,在哪些上表现不佳?
- 如果ChatGPT在某些任务上落后,其背后的原因是什么?
本文方法
本文的核心是一种系统性的、大规模的实证评估方法,而非提出新的模型架构。其目的是全面地、公平地刻画ChatGPT的零样本能力。
评估对象与设定
- 模型: 主要比较ChatGPT (\(gpt-3.5-turbo\)) 和其前身GPT-3.5 (\(text-davinci-003\))。
- 设定: 严格采用零样本学习设置,即不为模型提供任何任务相关的训练示例。
评估任务与数据集
为了全面评估,本文选取了覆盖7个代表性任务类别的20个流行NLP数据集,具体包括:
- 推理: 算术推理、常识推理、符号推理和逻辑推理。
- 自然语言推断 (NLI)
- 问答 (QA)
- 对话
- 摘要
- 命名实体识别 (NER)
- 情感分析
 图1: 六类任务(情感分析、自然语言推断、命名实体识别、问答、对话、摘要)的指令和输入格式示例。
图1: 六类任务(情感分析、自然语言推断、命名实体识别、问答、对话、摘要)的指令和输入格式示例。
 图2: 推理任务的指令示例(以AQUA-RAT数据集为例)。对于推理任务,本文同时进行了标准的零样本实验和零样本思维链(zero-shot-CoT)实验。
图2: 推理任务的指令示例(以AQUA-RAT数据集为例)。对于推理任务,本文同时进行了标准的零样本实验和零样本思维链(zero-shot-CoT)实验。
提示词设计
- 标准提示: 对于大多数任务,模型接收由任务指令 \(P\) 和测试问题 \(X\) 拼接而成的输入,并生成目标文本 \(Y\)。
- 思维链提示 (CoT): 针对推理任务,采用两阶段提示法。第一阶段使用“Let’s think step by step”作为指令,引导模型生成推理过程 \(R\);第二阶段将 \(P\)、\(X\) 和 \(R\) 一同作为输入,并用一个触发句(如“Therefore, the answer is”)引导模型得出最终答案。
创新点
本文的核心贡献在于其评估的广度与深度。它是首批对ChatGPT在如此多样化的NLP任务上进行系统性零样本能力基准测试的研究之一。通过严谨的实验设计和细致的案例分析,为理解ChatGPT的优势与局限性提供了一个全面的实证画像。
实验结论
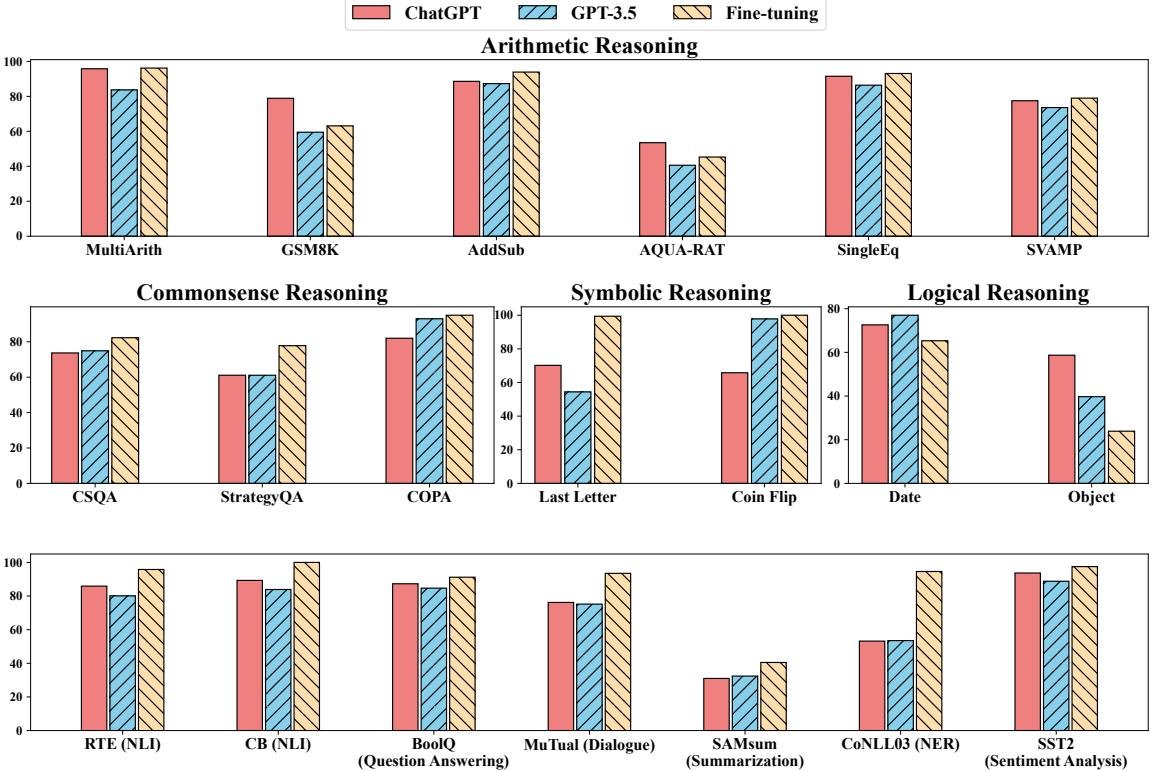 该图宏观展示了ChatGPT在20个数据集上的表现,并与GPT-3.5及在特定任务上微调过的模型进行了对比。
该图宏观展示了ChatGPT在20个数据集上的表现,并与GPT-3.5及在特定任务上微调过的模型进行了对比。
综合表现
- 通用性与局限: 尽管ChatGPT展现出作为通用模型处理多种任务的潜力,但在大多数任务上,其性能仍显著低于经过任务数据微调(fine-tuned)的模型,表明它距离成为完美的通用任务解决器还有差距。
分任务表现与洞察
推理任务
-
算术推理: ChatGPT表现出极强的算术推理能力,在6个数据集中的5个上超越了GPT-3.5,尤其在使用CoT时性能提升显著。这证明其通过RLHF获得了更强的遵循指令和步骤化思考的能力。
模型 MultiArith GSM8K AddSub AQUA-RAT SingleEq SVAMP ChatGPT (Zero-Shot) 79.8 23.8 78.9 88.6 83.5 28.0 ChatGPT (w/ CoT) 95.8 78.9 88.6 53.5 91.5 77.5 GPT-3.5 (Zero-Shot) 24.2 12.6 59.5 87.3 81.3 28.0 GPT-3.5 (w/ CoT) 83.7 12.5 40.6 86.4 73.6 33.5 -
常识、符号与逻辑推理: 与算术推理相反,ChatGPT在这些任务上通常弱于GPT-3.5。这表明RLHF训练带来的能力提升并非在所有推理类型上都是一致的。
自然语言推断 (NLI)
- ChatGPT在NLI任务上显著优于GPT-3.5及其他零样本LLMs。
- 深入分析发现,ChatGPT在判断“蕴含”(entailment)关系时准确率极高(92.5%),远超GPT-3.5(70.6%),但在判断“非蕴含”关系时则稍逊一筹。这可能与RLHF使其更倾向于处理事实一致性输入有关。
问答 (QA)
- 与NLI结果一致,ChatGPT在BoolQ数据集上的表现优于GPT-3.5。
- 同样地,它在回答“Yes”时准确率更高,再次印证了其在处理事实性输入上的优势。但有时它会生成“不清楚”等非指定格式的答案,影响了整体分数。
对话
- 正如预期,ChatGPT在多轮对话推理任务(MuTual)上优于GPT-3.5,这与其为对话优化的设计初衷相符。它能更有效地进行上下文推理,避免无关信息干扰。
摘要
- 出乎意料的是,ChatGPT在摘要任务上的ROUGE分数低于GPT-3.5。
- 原因是ChatGPT生成的摘要过于冗长(平均36.6词 vs GPT-3.5的23.3词和标准答案的20.0词),包含了大量冗余信息。
- 实验表明,在零样本指令中显式加入长度限制(如“不超过25词”)反而会损害摘要质量,导致ROUGE分数进一步下降。
命名实体识别 (NER)
- ChatGPT和GPT-3.5在NER任务上的表现均不理想, F1分数远低于微调模型。
- 这突出表明,当前的LLMs在解决序列标注(sequence tagging)这类需要精确定位和分类边界的任务时仍面临巨大挑战。
情感分析
- ChatGPT的表现优于GPT-3.5,尤其在识别“负面”情感时优势明显。
- 然而,与FLAN等模型相比,其性能较差的部分原因在于它不总是严格遵守指定的输出格式(“positive”或“negative”),有时会生成“neutral”或“mixed”等答案。
最终结论
ChatGPT是一个强大的通用语言模型,在推理(尤其是算术推理)和对话任务上展现出卓越的能力。这很可能得益于其RLHF训练。然而,它并非万能的NLP任务解决器,在序列标注等特定任务上能力有限,并且其性能通常无法企及为特定任务量身定制的微调模型。此外,它的行为(如输出冗长、偏好事实性)也反映了RLHF可能带来的特定偏见。