Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation
-
ArXiv URL: http://arxiv.org/abs/2305.01210v3
-
作者: Yuyao Wang; Chun Xia; Jiawei Liu; Lingming Zhang
-
发布机构: Nanjing University; University of Illinois Urbana-Champaign
TL;DR
本文提出了一个名为 EvalPlus 的代码合成评估框架,通过大规模自动生成测试用例(结合 LLM 和变异测试策略)来严格评估大语言模型(LLM)生成代码的真实功能正确性,揭示了现有基准(如 HumanEval)因测试不足而严重高估了模型的性能。
关键定义
- EvalPlus: 本文提出的一个代码合成评估框架。它通过自动测试输入生成引擎来增强现有的代码基准,旨在更严格、更精确地评估 LLM 合成代码的真实功能正确性。
- HumanEval+: 使用 EvalPlus 框架对流行的 HumanEval 基准进行增强后得到的新数据集。它将原有的测试用例数量扩展了 80 倍,并修正了原始基准中的错误参考答案。
- 类型感知变异 (Type-aware mutation): EvalPlus 中用于大规模生成测试用例的核心技术之一。它检查有效种子输入的变量类型,并根据类型信息进行变异,以高效生成大量结构相似但可能触发边缘情况的新测试输入。
- 程序输入契约 (Program Input Contracts): 一种通过代码断言(如 \(assert n > 0\))来系统性地标注函数前置条件的方法。这有助于过滤掉自动生成的无效输入,并为 LLM 提供更明确的任务约束,以减少对问题描述的模糊解读。
相关工作
当前,评估大语言模型代码生成能力的主流方法(SOTA)是使用编程基准,如 HumanEval。这些基准提供一系列编码问题和手动编写的测试用例,通过 \(pass@k\)(即生成 k 个解中至少有一个通过所有测试的概率)等指标来衡量模型性能。
然而,这些现有基准存在关键瓶颈:
- 测试不足 (Insufficient testing):每个问题的测试用例平均数量很少(通常少于10个),且测试场景过于简单,难以覆盖代码的各种功能和边缘情况。这导致逻辑上错误的代码也能通过所有测试,从而被错误地判定为正确。
- 问题描述不精确 (Imprecise problem description):任务的自然语言描述往往很模糊,没有明确定义输入域或异常处理方式,导致 LLM 可能对程序功能做出与测试意图不符的解读。
因此,本文旨在解决的问题是:如何克服现有基准测试不充分的缺陷,从而能够更严格、更准确地评估 LLM 生成代码的真实功能正确性,避免对模型能力的错误高估。

本文方法
EvalPlus 框架的核心是一个自动测试输入生成引擎,旨在通过增强现有代码基准来精确评估 LLM 生成代码的函数正确性。其工作流程如下图所示。
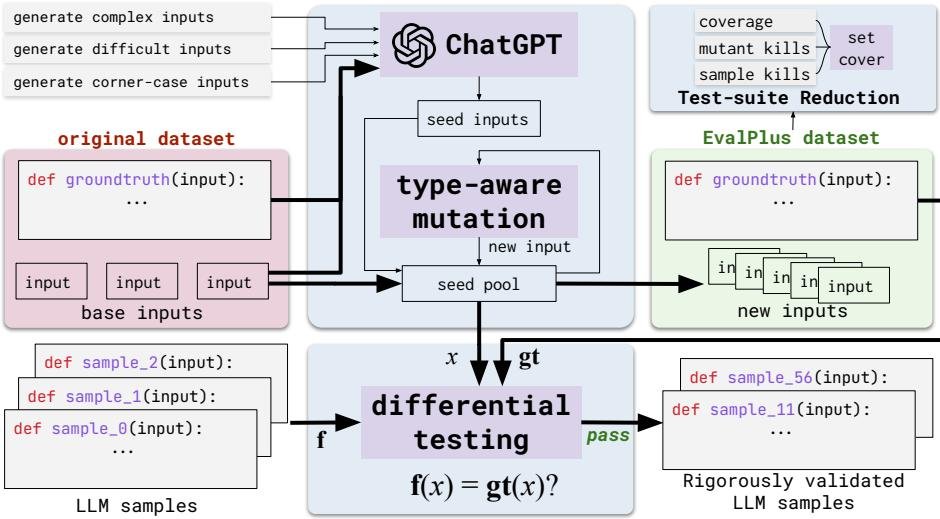
自动化测试输入生成
该过程结合了 LLM 和传统的变异测试方法,分为两个阶段:
-
通过 ChatGPT 初始化种子输入:首先,EvalPlus 构建一个提示(Prompt),其中包含问题的参考正确实现(ground-truth solution)、现有数据集中的示例测试输入以及鼓励生成“有趣”输入的特定指令。利用 ChatGPT 强大的代码理解能力,生成一批高质量的、旨在测试困难角落和边缘情况的种子输入。这些输入在格式上是有效的,并且能满足一些传统生成器难以处理的语义约束(例如,输入必须是回文)。
-
类型感知输入变异:由于直接用 LLM 大规模生成测试成本高且速度慢,EvalPlus 以 ChatGPT 生成的种子输入为起点,进行类型感知的输入变异。该方法遵循典型的基于变异的模糊测试(fuzzing)工作流,对种子输入进行随机选择和变异,以高效生成海量新测试。变异操作会考虑数据的类型,如下表所示。例如,对整数进行加/减一操作,对列表进行元素移除、重复或递归变异。这种方法能够保持输入结构有效性的同时,大规模扩展测试用例的数量。
| 类型 | 变异规则 | 类型 | 变异规则 |
|---|---|---|---|
| int | float | 返回 \(x±1\) | List | 移除/重复随机项 \(x[i]\) 插入/替换 \(x[i]\) 为 \(Mutate(x[i])\) |
| bool | 返回一个随机布尔值 | Tuple | 返回 \(Tuple(Mutate(List(x)))\) |
| NoneType | 返回 \(None\) | Set | 返回 \(Set(Mutate(List(x)))\) |
| str | 移除/重复一个子字符串 \(s\) 用 \(Mutate(s)\) 替换 \(s\) | Dict | 移除键值对 \(k→v\) 更新 \(k→v\) 为 \(k→Mutate(v)\) 插入 \(Mutate(k)→Mutate(v)\) |
最终,所有生成并通过有效性检查的测试用例都将用于通过差分测试(differential testing)来评估 LLM 生成的代码,即将其输出与参考实现的输出进行对比。
测试套件规约
为了在保持高测试强度的同时降低评估成本,EvalPlus 提供了一个可选的测试套件规约(Test-Suite Reduction)功能。该问题被形式化为集合覆盖问题(set covering problem),目标是找到一个最小的测试子集,使其能够满足与完整测试集相同的测试要求。本文定义了以下三种测试要求:
- 代码覆盖率 (Code coverage):保留能够达到与完整测试集相同分支覆盖率的最小测试子集。
- 变异体杀死 (Mutant killings):通过对参考代码进行微小修改(如将 \(<\) 改为 \(≤\))创建大量人造的错误程序(变异体),保留能够“杀死”(即检测出)与完整测试集相同数量变异体的最小测试子集。该指标比代码覆盖率更能评估测试的缺陷检测能力。
- LLM 样本杀死 (LLM sample killings):根据经验,保留能够检测出由其他 LLM 生成的已知错误代码样本的最小测试子集。
此外,本文还探索了合并上述所有三种要求的策略。
程序输入契约
为了解决原始问题描述模糊性的问题,本文引入了“按契约编程”的思想,通过代码断言(assertions)的形式为每个函数手动标注输入前置条件。这样做有双重好处:
- 在测试生成阶段,它可以自动过滤掉所有不满足契约的无效输入,避免产生误报。
- 这些契约可以作为对自然语言描述的补充,为 LLM 提供更清晰、无歧义的功能约束。
实验结论
本文基于 EvalPlus 框架构建了 HumanEval+ 和 HumanEval+-MINI 数据集,并对 26 个主流 LLM 进行了广泛评估。
| 平均测试数 | 中位测试数 | 最小测试数 | 最大测试数 | 任务数 | |
|---|---|---|---|---|---|
| HUMANEVAL | 9.6 | 7.0 | 1 | 105 | 164 |
| HUMANEVAL+ | 764.1 | 982.5 | 125 | 21,100 | 164 |
| HUMANEVAL+-MINI | 16.1 | 13.0 | 1 | 110 | 164 |
关键实验结果
-
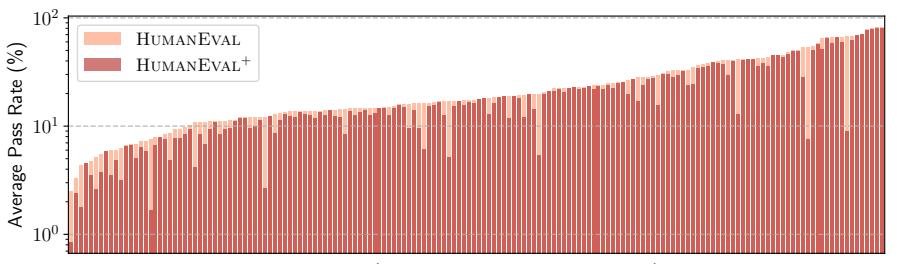
显著降低模型分数,揭示真实性能:与原始的 HumanEval 相比,在 HumanEval+ 上进行评估时,所有 LLM 的 \(pass@k\) 分数都出现了显著下降,最大降幅达到 19.3%-28.9%。这包括 GPT-4(下降13.1%)和 ChatGPT(下降12.6%)等顶级模型,证实了先前评估确实高估了模型的代码生成能力。
-
纠正模型排名错误:更严格的测试改变了模型的相对排名。例如,在原始 HumanEval 上,WizardCoder-CodeLlama 和 Phind-CodeLlama 的性能不敌 ChatGPT;但在 HumanEval+ 上,它们均反超 ChatGPT。这表明测试不足可能导致对模型能力的错误判断。
-
测试套件规约的有效性:HumanEval+-MINI 数据集虽然比 HumanEval+ 小 47 倍,但在评估中取得了几乎相同的效果,证明了测试套件规约策略的有效性,它可以在保证测试强度的同时大幅提高评估效率。在所有规约策略中,基于“LLM样本杀死”的策略效果最好。
-
揭示 HumanEval 自身缺陷:EvalPlus 不仅检测出 LLM 生成代码的错误,还发现了原始 HumanEval 数据集中 18 个(占11%)参考实现本身就存在缺陷,包括未处理边缘情况、逻辑错误和性能问题。这进一步凸显了现有基准质量堪忧的问题。

总结
实验结果有力地证明,当前广泛使用的代码生成基准由于测试不充分,无法准确反映 LLM 的真实编程能力。本文提出的 EvalPlus 框架及其产出的 HumanEval+ 数据集,通过自动化的、大规模的、高质量的测试生成,提供了一种更严格、更可靠的评估方法,是未来评估和研究 LLM 代码生成能力的重要工具。