Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
-
ArXiv URL: http://arxiv.org/abs/2306.05685v4
-
作者: Siyuan Zhuang; Ying Sheng; Yonghao Zhuang; Haotong Zhang; Zhanghao Wu; Joseph E. Gonzalez; Wei-Lin Chiang; Lianmin Zheng; Zi Lin; Dacheng Li; 等3人
-
发布机构: Carnegie Mellon University; MBZUAI; Stanford; UC San Diego; University of California, Berkeley
TL;DR
本文提出使用强大的大语言模型(如GPT-4)作为裁判(LLM-as-a-Judge)来评估聊天机器人,并通过新提出的基准 MT-Bench 和 Chatbot Arena 的实验证明,该方法的评判结果与人类偏好具有超过80%的一致性,达到了人类之间的一致性水平,为自动化评估提供了一种可扩展且可解释的方案。
关键定义
- LLM-as-a-Judge (用作裁判的LLM):一种评估方法,利用强大的大语言模型(LLM)作为代理裁判,来评判其他聊天机器人在开放式问题上的回答质量,以模拟人类的偏好。
- MT-Bench:本文提出的一个多轮对话基准测试集。它包含80个精心设计的多轮问题,覆盖写作、推理、数学等8个核心能力类别,旨在评估模型在多轮对话中的指令遵循和对话能力。
- Chatbot Arena:本文开发的一个众包基准测试平台。用户在该平台上与两个匿名的聊天机器人同时对话,并投票选出更优的回答。它通过真实世界的用户交互来收集大规模、无限制场景下的人类偏好数据。
- 位置偏见 (Position Bias):LLM裁判倾向于偏爱特定位置(如第一个出现)的回答,而与其内容质量无关。
- 冗长偏见 (Verbosity Bias):LLM裁判倾向于偏爱更长、更详细的回答,即使这些回答的准确性或质量并不更高。
- 自我提升偏见 (Self-enhancement Bias):LLM裁判可能倾向于给自家模型(或风格相似的模型)生成的回答打出更高的分数。
相关工作
当前评估大语言模型(LLM)的主流基准,如 MMLU 和 HELM,主要集中在衡量模型在封闭式、知识驱动任务上的核心能力。然而,随着模型通过指令微调和人类反馈强化学习(RLHF)变得更善于对话和遵循指令,这些传统基准已无法有效评估模型与人类偏好的一致性,尤其是在开放式、多轮对话场景中。例如,一个在传统基准上得分很高的基础模型,其对话能力可能远不如经过对齐微调的模型,但现有基准无法捕捉这种差异。
因此,本文旨在解决的核心问题是:如何建立一个既鲁棒又可扩展的自动化方法,来评估LLM在开放、多轮对话中与人类偏好的一致性。

本文方法
评估基准
为了系统性地研究LLM评估,本文首先构建了两个以人类偏好为核心的评估基准.
MT-Bench
MT-Bench 是一个包含80个高质量多轮问题的测试集,旨在评估模型的多轮对话和指令遵循能力。这些问题被精心设计,以挑战并区分最先进的模型。问题覆盖了8个常见用例类别:写作、角色扮演、信息提取、推理、数学、编码、知识I(STEM)和知识II(人文社科)。
| 类别 | 示例问题 |
|---|---|
| 写作 | 第一轮:写一篇关于夏威夷旅行的博客文章,突出文化体验和必看景点。 |
| 第二轮:重写你的上一篇回答。每个句子都以字母A开头。 | |
| 数学 | 第一轮:给定 $f(x)=4x^{3}-9x-14$,求 $f(2)$ 的值。 |
| 第二轮:求 $x$ 使得 $f(x)=0$。 | |
| 知识 | 第一轮:提供关于GDP、通货膨胀和失业率等经济指标之间相关性的见解。解释财政和货币政策如何… |
| 第二轮:现在,像对一个五岁小孩一样再解释一遍。 |
Chatbot Arena
Chatbot Arena 是一个众包基准平台,采用匿名“对战”模式。用户同时与两个匿名模型进行对话,然后投票选出更好的模型。这种方式能收集到来自广泛真实世界场景的、多样化的用户偏好数据。
LLM-as-a-Judge
本文的核心方法是使用LLM作为人类裁判的代理,来自动化评估流程。
裁判类型
本文提出了三种LLM裁判的实现方式:
- 成对比较 (Pairwise comparison):向LLM裁判提供一个问题和两个模型的回答,让其判断哪个更好或宣布平局。
- 单个回答评分 (Single answer grading):让LLM裁判直接对单个回答进行打分(例如1-10分)。
- 参考答案引导评分 (Reference-guided grading):在评分时,向LLM裁判提供一个高质量的参考答案,以辅助其判断,尤其适用于有标准答案的问题(如数学)。
优点
该方法主要有两个优点:
- 可扩展性 (Scalability):自动化评估流程,无需大量人工参与,可以快速迭代和大规模部署。
- 可解释性 (Explainability):LLM裁判不仅能给出分数,还能提供详细的评判理由,使得评估结果易于理解和分析。
局限性
本文系统地研究了LLM裁判的几种局限性:
-
位置偏见:实验发现,包括GPT-4在内的多个LLM裁判都表现出明显的位置偏见,倾向于选择第一个出现的答案。如下表所示,当面对两个相似答案时,GPT-4的评判一致性(交换顺序后结果不变)也仅为65%左右。 不同LLM裁判的位置偏见
裁判 提示词 一致性 偏向第一个 偏向第二个 错误 Claude-v1 default 23.8% 75.0% 0.0% 1.2% rename 56.2% 11.2% 28.7% 3.8% GPT-3.5 default 46.2% 50.0% 1.2% 2.5% rename 51.2% 38.8% 6.2% 3.8% GPT-4 default 65.0% 30.0% 5.0% 0.0% rename 66.2% 28.7% 5.0% 0.0% -
冗长偏见:实验通过“重复列表”攻击(将原文列表内容换一种说法再重复一遍,使回答变长但信息量不变)发现,LLM裁判容易偏爱更长的回答。GPT-4对此类攻击的抵抗力较强,但仍有8.7%的失败率,而Claude-v1和GPT-3.5的失败率则高达91.3%。 “重复列表”攻击下的裁判失败率
裁判 Claude-v1 GPT-3.5 GPT-4 失败率 91.3% 91.3% 8.7% -
自我提升偏见:有迹象表明,LLM裁判可能偏爱自己或同系列模型生成的答案。例如,GPT-4作为裁判时,GPT-4模型的胜率比人类裁判给出的胜率高约10%。但由于数据有限,该结论尚不确定。
-
数学与推理能力有限:LLM裁判在评估其自身能力不足的领域(如复杂数学和推理)时会犯错。更有趣的是,即使对于它能解决的简单数学问题,也可能被错误的答案误导,从而做出错误判断。
局限性的解决方案
为缓解上述偏见和限制,本文提出了一些解决方案:
- 交换位置:通过交换两个回答的顺序进行两次评估,只有在两次评估中都胜出的才算作胜利,否则记为平局。这是一种保守但有效消除位置偏见的方法。
-
思维链 (Chain-of-thought) 和参考引导:为了提升在数学等问题上的评分准确性,可以提示LLM裁判先自己思考并解决问题(思维链),或者直接提供一个正确的参考答案。实验表明,参考引导能将GPT-4在数学问题上的评分失败率从70%(14/20)大幅降低到15%(3/20)。 不同提示词对数学问题评分失败率的影响
Default CoT Reference 失败率 14/20 6/20 3/20 - 处理多轮对话:在评估多轮对话时,将完整的对话历史呈现给裁判,而不是将每一轮拆开评估。这能让裁判更好地理解上下文,避免因指代不清而做出错误判断。
实验结论
高度一致性
本文的核心实验结论是,强大的LLM裁判(特别是GPT-4)与人类专家的偏好具有高度一致性。
- 在MT-Bench上,GPT-4裁判与人类专家在非平局情况下的一致性达到85%,这甚至略高于人类之间的一致性(81%-82%)。这表明GPT-4的判断标准与人类主流偏好非常接近。
-
如下表所示,无论是成对比较(G4-Pair)还是单个回答评分(G4-Single),GPT-4都表现出与人类(Human)的高度一致性。 MT-Bench上不同裁判间的一致性(第二轮)
设置 S1 (随机=33%) S2 (随机=50%) 裁判 G4-Single Human G4-Single Human G4-Pair 70% 66% 95% 85% G4-Single - 59% - 84% Human - 67% - 82% -
在规模更大的Chatbot Arena数据集上,也观察到了类似的趋势,GPT-4与众包用户的偏好一致性达到87%。 Chatbot Arena上不同裁判间的一致性
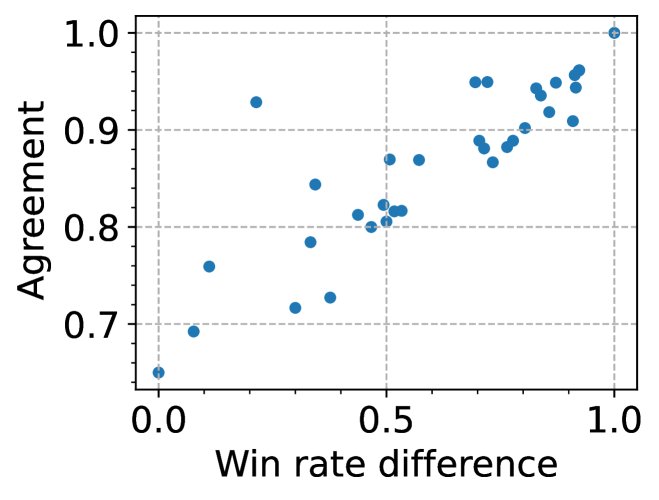
设置 S1 (随机=33%) S2 (随机=50%) 裁判 H 裁判 H G4 64% G4 87% G4-S 60% G4-S 85% G3.5 54% G3.5 83% C 53% C 84% - 进一步分析发现,当两个被评估模型的性能差距越大时,GPT-4与人类的一致性就越高,从70%逼近100%。
模型表现与基准互补性
-
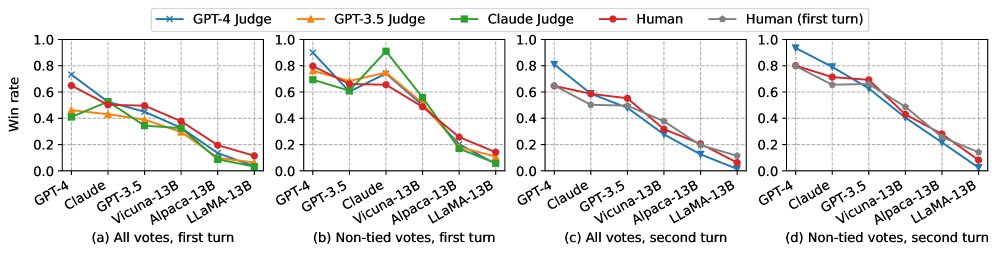
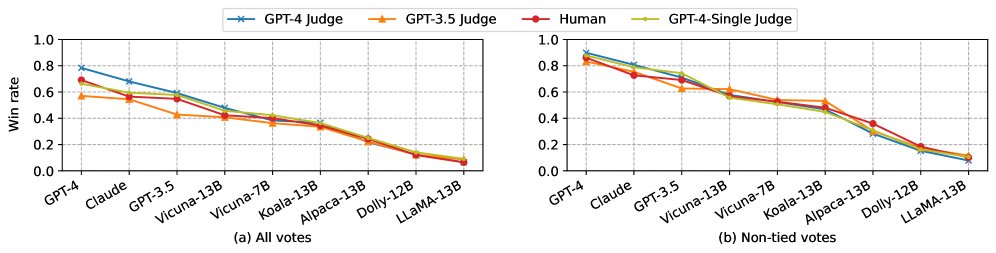
LLM裁判和人类裁判对各个模型的排名趋势高度一致。GPT-4在所有模型中表现最佳,其后是GPT-3.5和Claude。Vicuna-13B在推理、数学和编码方面明显弱于GPT-3.5。
-
实验证明,MT-Bench这类偏好基准与MMLU等传统能力基准是互补的。如下表所示,仅用少量高质量对话数据微调的Vicuna-7B (selected),其MT-Bench分数大幅提升(从2.74到5.95),但MMLU分数提升不明显。这说明偏好基准能捕捉到传统基准无法衡量的人机交互质量提升。 模型在不同基准上的表现
模型 #训练Token MMLU (5-shot) TruthfulQA (0-shot) MT-Bench Score (GPT-4) LLaMA-13B 1T 47.0 0.26 2.61 Alpaca-13B 4.4M 48.1 0.30 4.53 Vicuna-7B (selected) 4.8M 37.3 0.32 5.95 Vicuna-13B (all) 370M 52.1 0.35 6.39 GPT-3.5 - 70.0 - 7.94 GPT-4 - 86.4 - 8.99
最终结论
本文的系统性研究表明,使用强大的LLM(如GPT-4)作为裁判是一种可扩展、可解释且可靠的聊天机器人评估方法。它与人类偏好的一致性达到了人类之间的水平,为未来自动化评估LLM的对齐能力和交互质量奠定了坚实的基础。