KAN: Kolmogorov-Arnold Networks
-
ArXiv URL: http://arxiv.org/abs/2404.19756v5
-
作者: Max Tegmark; James Halverson; Thomas Y. Hou; Ziming Liu; Yixuan Wang; Sachin Vaidya; Fabian Ruehle; Marin Soljacic
-
发布机构: California Institute of Technology; Massachusetts Institute of Technology; NSF Institute for Artificial Intelligence and Fundamental Interactions; Northeastern University
TL;DR
本文提出了一种名为科尔莫戈罗夫-阿诺德网络(Kolmogorov-Arnold Networks, KANs)的新型神经网络架构,其将可学习的激活函数置于网络边缘(“权重”)而非节点上,从而在函数拟合等任务中,相比于传统的多层感知机(MLPs),展现出更高的精度和可解释性。
关键定义
- 科尔莫戈罗夫-阿诺德网络 (Kolmogorov-Arnold Networks, KANs):一种受科尔莫戈罗夫-阿诺德表示定理启发的新型神经网络架构。与在节点上使用固定激活函数的MLPs不同,KANs在网络的边上使用可学习的一维激活函数,而节点仅执行简单的求和操作。
- KAN层 (KAN Layer):KAN的基本构建单元,定义为一个由 $n_{\rm in} \times n_{\rm out}$ 个可学习的一维函数组成的矩阵 $\mathbf{\Phi}$,其中每个函数 $\phi_{q,p}$ 将第 $p$ 个输入特征映射到一个值,该值将贡献给第 $q$ 个输出。通过堆叠这些层,可以构建深度KANs。
- B样条 (B-spline):用于参数化KAN中可学习激活函数的技术。每个激活函数被表示为一组B样条基函数的线性组合,其系数是可学习的。这种表示方法使得函数可以被灵活地、局部地调整。
- 网格扩展 (Grid Extension):一种提升KANs精度的技术。通过在训练过程中增加B样条的网格点数量(从粗到细),可以在不从头开始训练的情况下,逐步提升模型对函数的拟合精度。
- 外部与内部自由度 (External vs Internal degrees of freedom):KANs中的两种参数类型。外部自由度指网络的拓扑结构(节点如何连接),负责学习变量间的组合关系(类似MLPs)。内部自由度指每个边上激活函数的参数(如B样条的系数),负责精确学习一维函数。
相关工作
当前,多层感知机(MLPs)是深度学习中用于逼近非线性函数的默认模型,其能力由通用逼近定理(Universal Approximation Theorem)保证。然而,MLPs也存在显著缺陷,例如在Transformer模型中,MLPs占据了大量参数且可解释性较差。此外,虽然MLPs能够学习高维函数,但它们在逼近简单的一维函数时效率不高。另一方面,样条(splines)拟合在一维情况下非常精确,但遭遇严重的维度灾难(Curse of Dimensionality, COD)。
本文旨在解决MLPs在精度和可解释性上的瓶颈,同时避免样条拟合的维度灾难问题。具体而言,本文的目标是设计一种新的网络架构,能够结合MLPs学习组合结构的能力和样条精确拟合一维函数的能力,从而在保证精度的前提下,获得更好的可解释性和更优的缩放性质(scaling laws)。
本文方法
KAN架构的灵感与设计
本文的架构设计灵感来源于科尔莫戈罗夫-阿诺德表示定理。该定理指出,任何多元连续函数 $f(x_1, \dots, x_n)$ 都可以表示为一维连续函数和加法的有限组合:
\[f(\mathbf{x})=f(x_{1},\cdots,x_{n})=\sum_{q=1}^{2n+1}\Phi_{q}\left(\sum_{p=1}^{n}\phi_{q,p}(x_{p})\right)\]这个定理表明,高维函数的学习本质上可以分解为学习一组一维函数。
基于此,本文提出了KAN架构。与将固定的非线性激活函数放在节点上的MLP不同,KAN将可学习的激活函数放在了网络的边上。 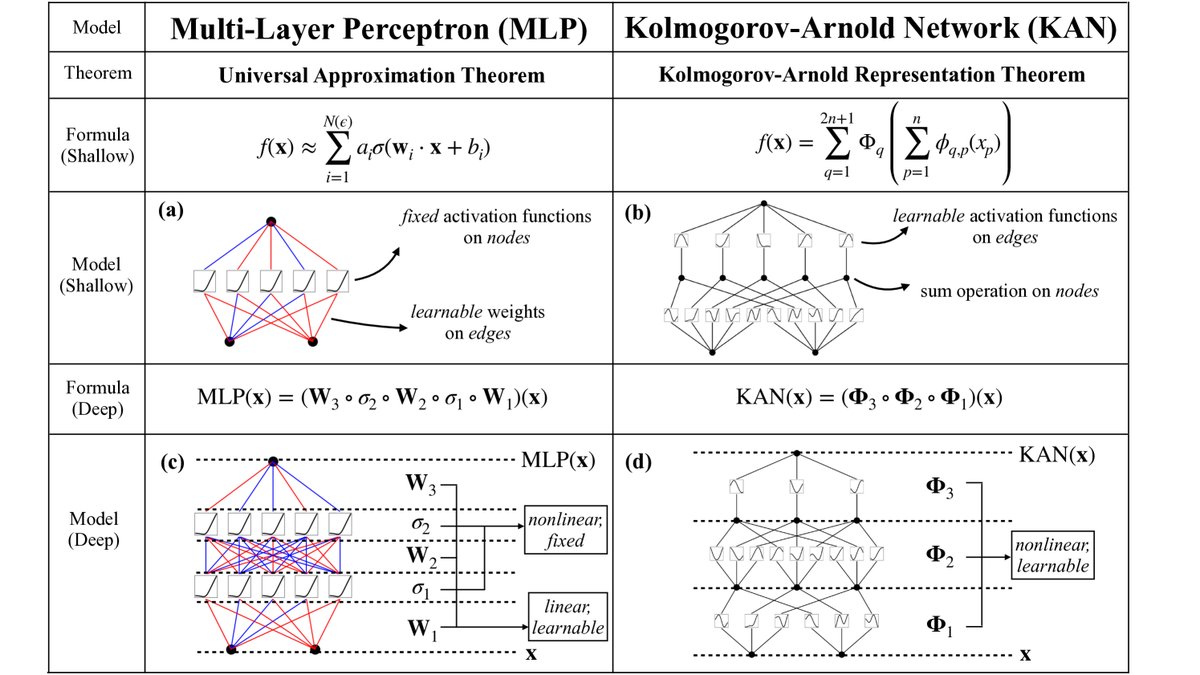 图1:多层感知机(MLPs)与科尔莫戈罗夫-阿诺德网络(KANs)的对比。
图1:多层感知机(MLPs)与科尔莫戈罗夫-阿诺德网络(KANs)的对比。
一个KAN网络由多个KAN层堆叠而成。一个从 $n_{\rm in}$ 维输入到 $n_{\rm out}$ 维输出的KAN层,是一个由 $n_{\rm in} \times n_{\rm out}$ 个一维激活函数 $\phi_{q,p}$ 组成的矩阵。对于第 $l$ 层的第 $i$ 个节点,其输出 $x_{l,i}$ 作为输入,传递给连接第 $l$ 层和第 $l+1$ 层的边上的激活函数 $\phi_{l,j,i}$。第 $l+1$ 层的第 $j$ 个节点的输入值是所有传入信号经过激活函数后的总和:
\[x_{l+1,j}=\sum_{i=1}^{n_{l}}\phi_{l,j,i}(x_{l,i})\]一个完整的KAN网络是多层这种操作的组合:
\[{\rm KAN}(\mathbf{x})=(\mathbf{\Phi}_{L-1}\circ\mathbf{\Phi}_{L-2}\circ\cdots\circ\mathbf{\Phi}_{0})\mathbf{x}\] 图2:左图为网络中激活流的符号表示。右图展示了一个激活函数如何被参数化为B样条,允许在粗细网格间切换。
图2:左图为网络中激活流的符号表示。右图展示了一个激活函数如何被参数化为B样条,允许在粗细网格间切换。
创新点
KAN最本质的创新在于将学习的重心从线性权重转移到了自适应的激活函数上。MLP的结构是固定的线性变换(权重矩阵)与固定的非线性激活函数交织,而KAN将这两者统一为边上的可学习函数。
优点
这个设计的核心优点是它巧妙地结合了MLPs和样条的优势:
- 克服维度灾难:像MLPs一样,KANs通过堆叠层来学习数据的组合结构(外部自由度),从而避免了传统样条拟合的维度灾难。
- 高精度拟合:像样条一样,KANs的每个激活函数可以非常精确地学习一维函数(内部自由度),这使得它们在拟合具有内在低维结构的高维函数时比MLPs更高效、更精确。
实现细节与理论保证
- 激活函数参数化:每个边上的激活函数 $\phi(x)$ 被参数化为B样条基函数的线性组合,并叠加一个残差基函数(如SiLU):$\phi(x)=w_{b}b(x)+w_{s}{\rm spline}(x)$。B样条的系数是可学习的。
- 理论保证:本文证明了(定理 2.1),如果一个函数可以被一个光滑的KAN表示,那么使用有限网格点的B样条进行逼近时,其逼近误差的衰减速度与维度无关,衰减指数为 $k+1$($k$是B样条的阶数),从而在理论上战胜了维度灾难。对于常用的三次B样条($k=3$),KANs的神经缩放指数 $\alpha=4$,远优于现有理论中MLPs的缩放指数。
 图3:论文组织结构图,展示了KANs的数学基础、精度和可解释性。
图3:论文组织结构图,展示了KANs的数学基础、精度和可解释性。
提升KANs精度与可解释性的技术
精度:网格扩展
为了进一步提升精度,本文提出了网格扩展技术。模型可以从一个具有少量网格点(参数较少)的粗糙样条开始训练。当训练进入平台期时,可以通过在现有样条函数上拟合一个新的、具有更密集网格点的样条,来增加模型容量,而无需重新从头训练。这个过程可以重复进行,使得损失呈现阶梯式下降。  图4:通过网格扩展可以提升KANs的精度。损失曲线呈现阶梯式下降,且测试RMSE随网格大小G呈现幂律缩放。
图4:通过网格扩展可以提升KANs的精度。损失曲线呈现阶梯式下降,且测试RMSE随网格大小G呈现幂律缩放。
可解释性:简化与交互
为了让KANs更具可解释性,本文提出了一套简化流程,使用户可以与模型交互,从而发现数据背后隐藏的符号公式。
- 稀疏化:通过L1范数和熵正则化,鼓励网络中的大部分激活函数变为零,从而使网络结构稀疏化。
- 可视化:将学习到的激活函数绘制出来,其幅度大小通过透明度表示,不重要的连接会淡出。
- 剪枝:根据激活函数的输入和输出得分,自动剪除不重要的节点,从而得到一个更小的、与问题结构更匹配的KAN架构。
- 符号化:当用户通过可视化发现某个激活函数形似已知的数学函数(如 \(sin\), \(x^2\))时,可以手动或通过系统建议将其固定为该符号形式。系统会自动拟合仿射变换参数以匹配尺度和平移。
下图展示了一个用户如何通过这个流程,从一个[2,5,1]的KAN逐步简化,最终发现目标函数 $f(x,y)=\exp(\sin(\pi x)+y^2)$ 的符号表达式。 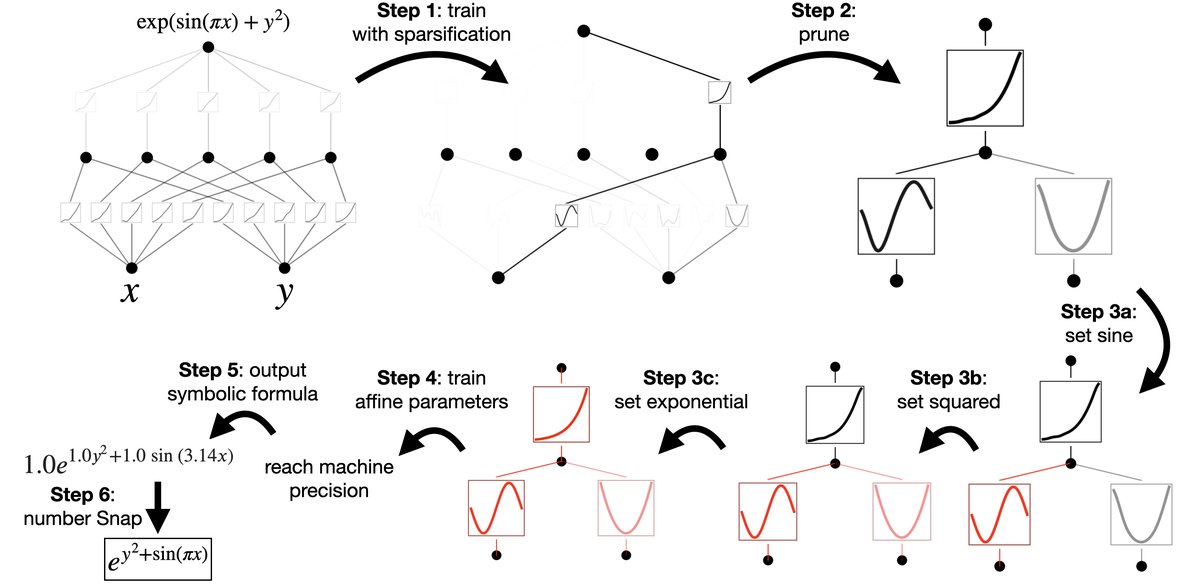 图5:一个与KAN交互进行符号回归的示例。
图5:一个与KAN交互进行符号回归的示例。
实验结论
虽然完整的实验细节在论文后续章节,但根据已提供的内容和引用可以总结出以下结论:
- 更高的精度和更好的缩放性:在函数拟合任务中,更小的KANs可以达到比更大的MLPs相当甚至更好的精度。实验(如图2.3)表明,KANs的测试误差随参数数量(网格点数G)的增加而下降,其缩放指数(接近-3)显著优于MLPs。
- 小网络泛化更好:实验发现,使用与问题内在结构相匹配的更小的KAN架构(例如,用[2,1,1] KAN拟合$f(x,y)=g(h_1(x)+h_2(y))$形式的函数)可以获得比过度参数化的大型KAN更低的测试误差和更好的泛化能力。
- 出色的可解释性:通过稀疏化、剪枝和符号化等交互式步骤,KANs能够被简化,从而清晰地揭示出数据背后隐藏的数学公式。这在科学发现任务中极具应用潜力,例如本文在数学(纽结理论)和物理(安德森局域化)两个领域的案例研究中,展示了KANs可以作为科学家的“合作者”来辅助(重新)发现物理和数学定律。
- 适用场景:本文的方法在小规模的“AI+科学”任务上展现了巨大潜力,尤其是在需要高精度和强可解释性的场景中,KANs是MLPs的一个非常有前景的替代方案。