KCM: KAN-Based Collaboration Models Enhance Pretrained Large Models
-
ArXiv URL: http://arxiv.org/abs/2510.20278v1
-
作者: Siliang Tang; Guangyu Dai; Yueting Zhuang
-
发布机构: Zhejiang University
TL;DR
本文提出了一种名为 KCM (KAN-Based Collaboration Models) 的大-小模型协同框架,它利用一个基于 Kolmogorov-Arnold Network (KAN) 的小型判断模型,智能地将输入样本分配给高效的小模型或强大的预训练大模型处理,并通过提示修改和知识蒸馏机制实现两个模型间的协同增强,从而在接近大模型性能的同时,显著降低了推理成本。
关键定义
- KCM (KAN-Based Collaboration Models):本文提出的核心方法。一个大-小模型协同框架,通过一个判断模型来动态分配任务。对于判断为“简单”的样本,由小模型直接处理;对于“困难”的样本,则交由大模型处理,同时利用小模型的输出来辅助大模型(提示修改),并利用大模型的输出来反哺小模型(知识蒸馏),形成一个闭环学习系统。
- KAN (Kolmogorov-Arnold Network):一种替代传统多层感知机 (MLP) 的神经网络架构。其核心特点是,可学习的激活函数位于网络的“边”(edges)上,而非像 MLP 那样在“节点”(nodes)上使用固定的激活函数。这使得 KAN 能够用更少的参数学习到更复杂的函数,具有更好的可解释性和精度潜力。在 KCM 中,KAN被用于构建核心的“判断小模型”。
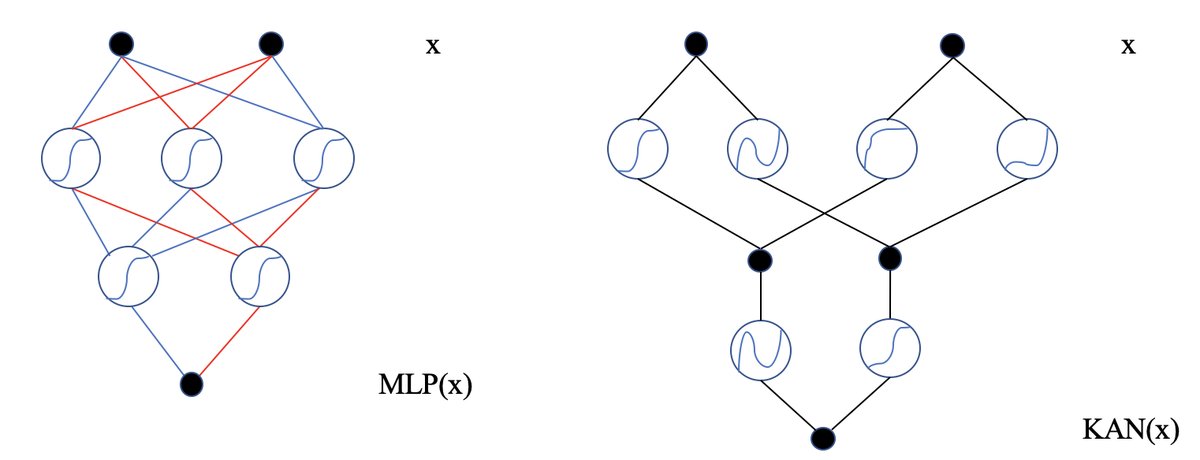
- 判断小模型 (Judgment Small Model):KCM 框架中的一个关键组件,基于 KAN 构建。它的作用是接收输入样本 \(x\),并输出一个置信度分数 \(C_x\),用于判断该样本应该由小模型处理还是大模型处理。高置信度意味着样本适合小模型,低置信度则意味着需要大模型的“介入”。
相关工作
当前,为了平衡大模型的强大性能与高昂的计算成本,大-小模型协同成为一个重要的研究方向。现有方法尝试结合两者的优势,但关键的瓶颈在于如何设计一个高效且智能的调度机制,以决定何时以及如何利用每个模型。
本文旨在解决这一具体问题:设计一个通用的、高效的协同框架,它不仅能智能地将任务在大小模型间进行分配以降低成本,还能通过模型间的双向互动(即小模型辅助大模型、大模型指导小模型)来共同提升整个系统的性能。
本文方法
KCM 的核心思想是构建一个智能的、自适应的协同系统。其训练和推理过程如下图所示,通过一个判断模型来决定数据流向,并结合提示修改与知识蒸馏,实现两个模型的共同进化。
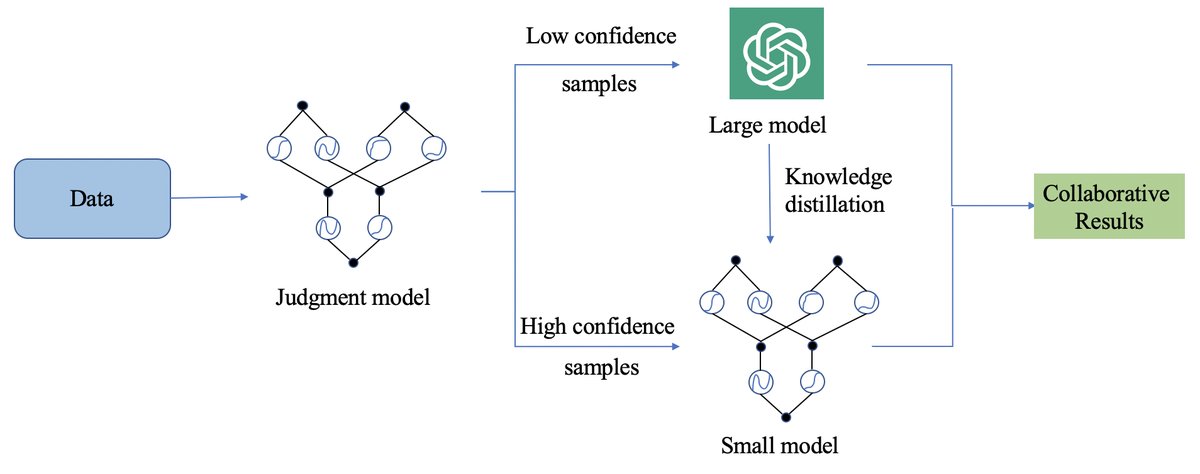
创新点
本文方法的创新主要体现在以下几个方面:
KAN-Based 判断小模型
系统的核心是一个判断小模型 $F_j$,它负责评估每个输入样本 $x$ 的“难度”。与传统的基于 MLP 的判断器不同,本文创新性地采用了 KAN 架构。KAN 将学习的重点从节点转移到边上,通过学习边上的激活函数,能以更少的参数实现更高的精度和更好的泛化能力。
该模型对输入 $x$ 进行处理,输出一个置信度分数 $C_x$,该分数通过对模型输出 logits $y_i$ 进行 softmax 计算得到:
\[C_{x} = \frac{e^{y_{i}}}{\Sigma e^{y_{n}}}, y_{i} \in F_{j}(x)\]当 $C_x$ 高于预设阈值 $\epsilon$ 时,样本被认为是“简单的”,交由小模型 $F_s$ 处理;反之,则被认为是“困难的”,交由大模型 $F_l$ 处理。
小模型提示修改
对于被判断为“困难”并发送给大模型 $F_l$ 的样本,KCM 并非简单地直接调用大模型。相反,它利用小模型 $F_s$ 对该样本的初步预测结果来构建或修改给大模型的提示(prompt)。
\[R_{l} = F_{l}(x_{i}, prompt), y_{i} \in F_{s}(x)\]这种方式相当于为大模型提供了一个“初步参考答案”或“上下文”,可以帮助大模型更快、更准确地聚焦于问题的关键点,从而提高其处理疑难样本的效率和效果。
大模型知识蒸馏
为了让小模型也能从大模型的“智慧”中学习,KCM 采用知识蒸馏机制。当大模型 $F_l$ 处理一个困难样本 $x$ 并产生输出 $C_l$ 时,该输出被用作“教师”信号,通过 KL 散度损失函数来指导小模型 $F_s$ 的学习。这使得小模型能够学习大模型在处理复杂问题时的“思维模式”。
\[L_{ls} = KL(F_{s}(x), C_{l}), \quad \text{when } C_{l} > \epsilon\]此外,判断模型 $F_j$ 的置信度输出 $C_x$ 也可以作为一种蒸馏信号,帮助优化小模型 $F_s$。
\[L_{js} = KL(F_{s}(x), C_{x}), \quad \text{when } C_{x} > \epsilon\]这种双向的知识流动形成了一个良性循环:小模型变得越来越强,能够处理更多样本,从而进一步降低了对昂贵大模型的调用频率。
算法流程
训练阶段:
- 对于每个样本,首先由判断模型 $F_j$ 计算置信度 $C_x$。
- 如果 $C_x$ 低于阈值 $\epsilon$,样本被标记为“困难”,并送入大模型 $F_l$。
- 大模型的输出 $C_l$ 用于计算蒸馏损失 $L_{ls}$,以更新小模型 $F_s$。
- 整个过程不断迭代,小模型 $F_s$ 在判断模型和大小模型的共同指导下不断优化。
推理阶段:
- 对于新样本,判断模型 $F_j$ 计算置信度 $C_x$。
- 如果 $C_x > \epsilon$,直接使用小模型 $F_s$ 的结果。
- 如果 $C_x \le \epsilon$,则调用大模型 $F_l$(可能结合了小模型的提示修改)得到最终结果。
实验结论
实验在语言、视觉和多模态任务上验证了 KCM 框架的有效性和通用性,并将阈值 $\epsilon$ 设为 0.98。
-
语言任务:在 APD 数据集上,无论是结合 BERT 还是 ChatGPT,KCM 都显著提升了基线模型的准确率,并优于其他协同方法。
BERT+KCM 在 APD 数据集上的准确率
| 模型 | IER | IED | Trigger | Role 1 | Role 2 | 平均 |
|---|---|---|---|---|---|---|
| BERT | 88.5% | 85.3% | 87.2% | 81.3% | 79.8% | 84.42% |
| BERT+D | 89.2% | 85.9% | 87.8% | 82.2% | 80.5% | 85.12% |
| BERT+KD | 89.9% | 86.2% | 88.3% | 82.5% | 80.9% | 85.56% |
| BERT+MCM | 90.5% | 86.8% | 88.8% | 83.2% | 81.5% | 86.16% |
| BERT+KCM | 91.1% | 87.2% | 89.5% | 83.9% | 82.3% | 86.80% |
**ChatGPT+KCM 在 APD 数据集上的准确率**
| 模型 | IER | IED | Trigger | Role 1 | Role 2 | 平均 |
|---|---|---|---|---|---|---|
| ChatGPT | 92.5% | 90.3% | 91.2% | 85.3% | 84.8% | 88.82% |
| ChatGPT+D | 92.9% | 90.8% | 91.8% | 85.9% | 85.2% | 89.32% |
| ChatGPT+KD | 93.3% | 91.2% | 92.3% | 86.3% | 85.9% | 89.80% |
| ChatGPT+MCM | 93.8% | 91.8% | 92.9% | 86.9% | 86.5% | 90.38% |
| ChatGPT+KCM | 94.3% | 92.3% | 93.5% | 87.5% | 87.3% | 90.98% |
-
视觉任务:在长尾图像分类数据集 CIFAR-100-LT 上,KCM 同样提升了多种视觉骨干网络(如 ResNet)的性能。
在 CIFAR-100-LT 数据集上的准确率
| 模型 | Many | Medium | Few | Overall |
|---|---|---|---|---|
| ResNet-32 | 65.2% | 46.1% | 20.3% | 46.8% |
| ResNet-32+KCM | 70.3% | 51.5% | 23.8% | 52.3% |
| BBN | 73.5% | 51.2% | 26.5% | 53.5% |
| BBN+KCM | 78.4% | 56.8% | 29.3% | 58.7% |
-
多模态任务:在 MSCOCO 数据集上,KCM 增强了 CLIP 模型在图文检索任务上的表现。
在 MSCOCO 数据集上的实验准确率
| 模型 | I2T R@1 | I2T R@5 | I2T R@10 | T2I R@1 | T2I R@5 | T2I R@10 |
|---|---|---|---|---|---|---|
| CLIP | 73.2% | 91.5% | 96.8% | 54.7% | 79.5% | 87.2% |
| CLIP+KCM | 75.4% | 93.1% | 97.8% | 57.2% | 81.6% | 89.1% |
-
消融实验:为了验证使用 KAN 作为判断模型的优越性,本文直接比较了 KCM(基于 KAN)与 MCM(基于 MLP)的性能。结果显示,在所有测试任务上,KCM 均优于 MCM,平均性能提升约 6%,证明了 KAN 在构建高效判断模型方面的优势。
MCM 与 KCM 的消融实验准确率
| 模型 | APD(%) | CIFAR(%) | MSCOCO(%) |
|---|---|---|---|
| MCM | 90.38 | 57.6 | 77.2 |
| KCM | 90.98 | 58.7 | 78.2 |
结论
实验结果有力地证明,KCM 是一个灵活且高效的大-小模型协同框架。它通过基于 KAN 的智能路由、提示修改和知识蒸馏的组合,在多种模态的任务上都取得了显著的性能提升,同时成功地降低了对大模型的依赖。该方法不仅在效果上超越了基线模型和传统的协同方法,也验证了 KAN 网络在构建此类协同系统中的价值。