Kimi k1.5: Scaling Reinforcement Learning with LLMs
-
ArXiv URL: http://arxiv.org/abs/2501.12599v4
-
作者: Huabin Zheng; Haochen Ding; Xingzhe Wu; Han Zhu; Weiran He; Jin Zhang; Yibo Liu; Y. Charles; Zhengxin Zhu; Yingbo Yang; 等84人
TL;DR
本文提出了一种通过强化学习(RL)扩展大型语言模型(LLM)能力的方法,其核心是利用长上下文(long context)和改进的策略优化算法,构建了一个无需蒙特卡洛树搜索等复杂技术的简化框架,从而在多项推理基准上取得了顶尖性能。
关键定义
- 长思维链 (Long Chain-of-Thought, Long-CoT): 本文的核心概念,指模型在长达128k的上下文窗口中生成非常长的、包含规划、评估、反思和探索等复杂认知过程的推理路径。与传统的思维链(CoT)相比,它不仅是步骤的罗列,更是一种在长文本中模拟搜索和试错的隐式规划过程。
- 部分 Rollout (Partial Rollout): 一种为长上下文强化学习设计的关键训练优化技术。它将长的生成轨迹(rollout)分解成多个片段,在不同的训练迭代中分步完成。这避免了单次生成过长序列带来的高昂计算成本和资源垄断,使得对超长上下文进行强化学习训练成为可能。
- 在线策略镜像下降 (Online Policy Mirror Descent): 本文采用的核心策略优化算法。它是一种离策略(off-policy)强化学习算法,通过最大化奖励的同时,用相对熵(KL散度)来约束新策略与旧策略(参考策略)之间的距离,从而保证训练的稳定性。
- 长文转短文 (Long2short): 一种模型压缩或知识蒸馏技术,旨在将强大的长思维链(Long-CoT)模型所具备的复杂推理能力,迁移到一个在推理时仅使用短思维链(Short-CoT)的高效模型中,从而在保证高性能的同时,降低实际部署成本。
相关工作
当前,通过下一词元预测(next token prediction)来预训练语言模型是主流方法,但其效果受限于高质量训练数据的数量。强化学习(RL)为持续提升人工智能开辟了一个新方向,它让模型能够通过奖励信号进行探索性学习,从而摆脱对静态数据集的依赖。
然而,以往将RL应用于LLM的工作尚未取得具有竞争力的结果。本文旨在解决这一问题,即如何设计一个有效且可扩展的RL框架,使其能够充分利用LLM的能力,特别是在复杂推理任务上,并且在框架设计上比依赖蒙特卡洛树搜索(MCTS)、价值函数等传统规划算法的方案更为简洁。
本文方法
本文提出的Kimi k1.5模型的训练流程包含多个阶段:预训练、常规监督微调(SFT)、长思维链监督微调(Long-CoT SFT)以及核心的强化学习(RL)。报告重点阐述了RL阶段。
RL准备工作
在进行强化学习之前,需要进行两个关键的准备步骤:
- RL提示集构建: 构建一个高质量的RL提示集至关重要。本文遵循三个原则:
- 多样性覆盖: 提示应涵盖STEM、编程、通用推理等多个领域。
- 难度均衡: 通过一个基于模型的评估方法(让SFT模型多次生成答案,根据成功率判断难度)来确保问题难度分布均衡。
- 可准确评估: 排除容易“奖励 hacking” 的问题(如选择题、判断题),并设计方法过滤掉那些无需推理也能轻易猜对答案的问题,确保奖励信号的有效性。
- 长思维链监督微调 (Long-CoT SFT): 在正式RL训练前,本文使用一个精心构建的小规模、高质量的Long-CoT数据集对模型进行轻量级的SFT。该数据集通过提示工程(prompt engineering)生成,包含了模拟人类规划、评估、反思和探索等认知过程的推理路径。这一“预热”步骤旨在让模型初步掌握生成结构化、长篇推理的能力。
强化学习
问题设定
本文将复杂的推理过程视为一个RL问题。给定问题 $x$,策略模型 $\pi_{\theta}$ 需要自回归地生成一系列中间思考步骤 $z$(即CoT)和最终答案 $y$。目标是最大化一个奖励函数 $r(x,y,y^{*})$ 的期望值,该函数根据模型答案 $y$ 和标准答案 $y^{*}$ 判断正确性(奖励为0或1)。
\[\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D},(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]\]本文的核心洞见在于,利用LLM的长上下文能力,可以将显式的规划算法(如树搜索)转化为模型内部的隐式搜索过程。模型在长长的思维链中进行试错、回溯和修正,其效果类似于规划算法的搜索,但实现方式仅为简单的自回归生成。
策略优化
本文采用了一种在线策略镜像下降的变体算法。在每次迭代中,该算法优化一个带相对熵正则化的目标函数,以当前策略 $\pi_{\theta_i}$ 为参考,防止策略更新步子过大:
\[\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E}_{(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]-\tau\mathrm{KL}(\pi_{\theta}(x) \mid \mid \pi_{\theta_{i}}(x))\right]\]最终的梯度更新形式如下,它类似于一个带基线(baseline)的策略梯度,但样本来自离策略的参考模型 $\pi_{\theta_i}$,并增加了一个 $l_2$ 正则项:
\[\frac{1}{k}\sum_{j=1}^{k}\left(\nabla_{\theta}\log\pi_{\theta}(y_{j},z_{j} \mid x)(r(x,y_{j},y^{*})-\overline{r})-\frac{\tau}{2}\nabla_{\theta}\left(\log\frac{\pi_{\theta}(y_{j},z_{j} \mid x)}{{\pi}_{\theta_{i}}(y_{j},z_{j} \mid x)}\right)^{2}\right)\]值得注意的是,该框架没有使用价值网络 (value function)。作者假设,在长思维链生成中,传统的信用分配(credit assignment)是有害的。探索错误的路径并最终从中恢复,对于学习复杂问题的解决模式至关重要。若使用价值函数,会过早地惩罚这些有价值的探索行为。
关键技术与策略
- 长度惩罚: 为了解决模型在RL训练中倾向于生成过长回复(“过度思考”)的问题,本文引入了长度奖励。在所有正确的回答中,它奖励较短的回答;同时会惩罚错误的、且冗长的回答。
- 采样策略:
- 课程学习采样 (Curriculum Sampling): 从易到难地对问题进行采样,以提高训练初期的效率。
- 优先采样 (Prioritized Sampling): 追踪模型在每个问题上的成功率 $s_i$,并以 $1-s_i$ 的概率进行采样,从而重点训练模型表现不佳的问题。
- 多模态与领域特定方法:
- 编码: 设计了一套自动化流程,利用 CYaRon 等工具为没有测试用例的编程题生成高质量的测试用例,作为奖励信号。
- 数学: 训练了一个基于CoT的奖励模型(Chain-of-Thought RM),它不仅给出对错判断,还能生成判断依据的推理过程,准确率高达98.5%,远超传统RM。
- 视觉: RL训练数据涵盖了真实世界数据、合成视觉推理数据和文本渲染数据三大类,以提升模型处理图表、真实场景和图文混合内容的能力。
长文转短文 (Long2short)
为了让模型在保持高性能的同时变得更高效,本文提出了几种将Long-CoT模型能力迁移到Short-CoT模型的方法:
- 模型合并 (Model Merging): 直接将Long-CoT模型和Short-CoT模型的权重进行平均。
- 最短拒绝采样 (Shortest Rejection Sampling): 对一个问题多次采样,选择其中最短的正确回答作为SFT数据。
- DPO: 将最短的正确答案作为正例,将其他较长的(无论对错)答案作为负例,构建偏好对进行DPO训练。
- Long2short RL: 在标准RL后,进行一个专门的RL阶段,施加更强的长度惩罚并限制rollout的最大长度。
基础设施创新
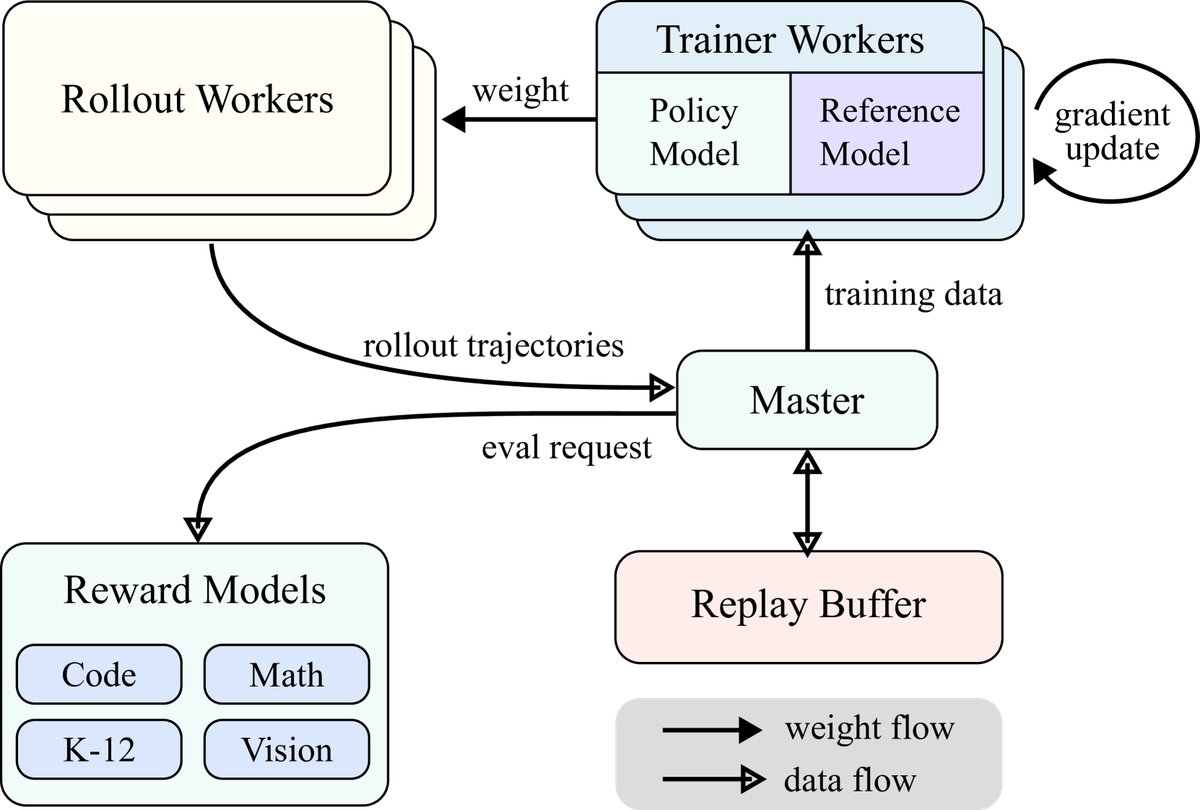
- 大规模RL训练系统: 本文构建了一个同步迭代的RL训练系统。系统包含一个中央主节点(central master)、rollout工作节点和训练工作节点。Rollout节点负责生成经验存入Replay Buffer,训练节点则从中取数据更新模型。
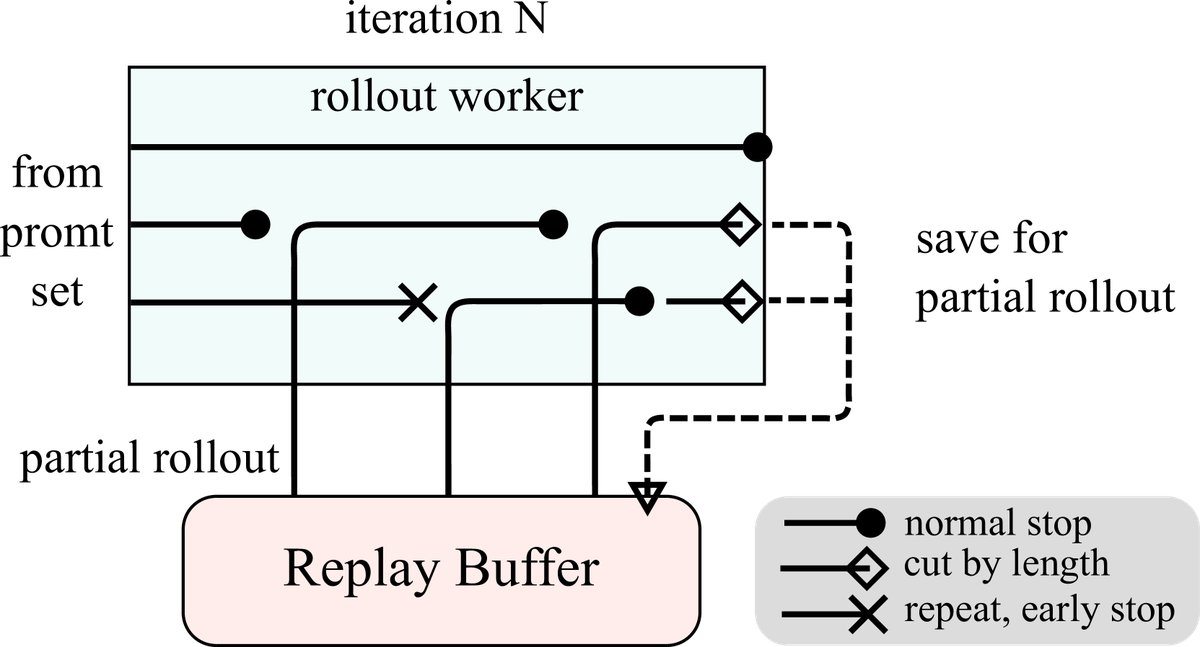
- 部分Rollout (Partial Rollouts): 这是支持长上下文RL的核心技术。系统为每次rollout设定一个固定的Token预算。如果一次生成没有完成,未完成的部分会被存入Replay Buffer,在下一次迭代中继续生成。这样,前序内容可以被高效复用,极大地降低了生成长序列的计算开销。
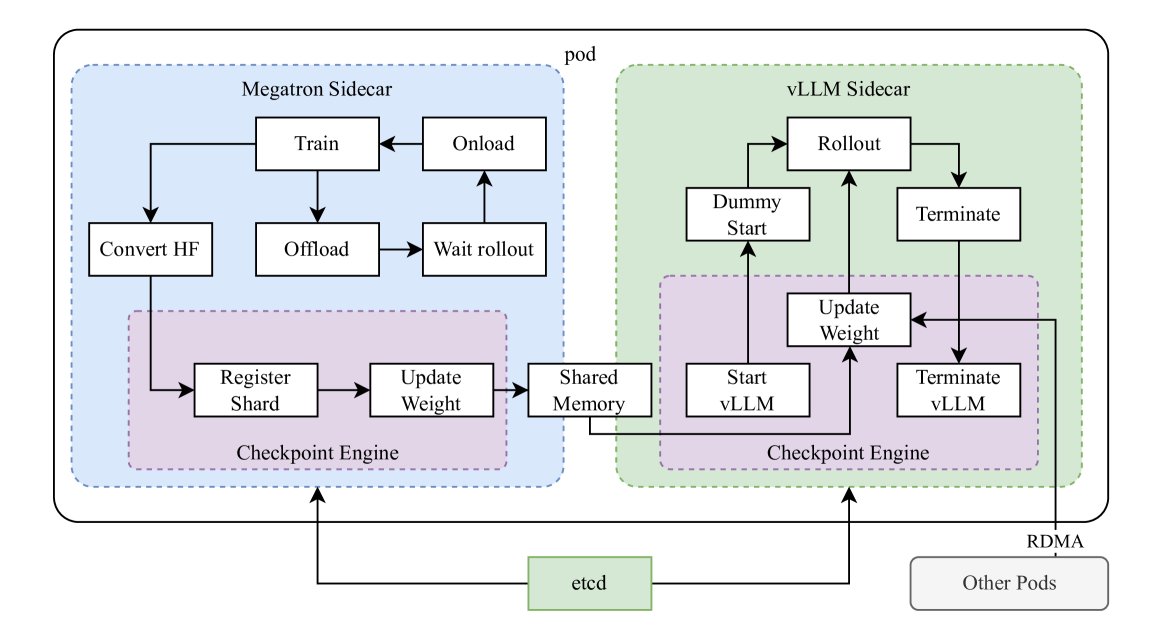
- 训练与推理的混合部署: 为了极致地利用GPU资源,本文设计了一个混合部署框架。该框架利用Kubernetes Sidecar容器,在同一个Pod中同时部署训练框架(Megatron)和推理框架(vLLM)。在RL的训练阶段,GPU用于Megatron;在rollout(推理)阶段,模型权重通过内存高效传递给vLLM执行,训练进程则暂停。这避免了在On-Policy RL中因等待推理而导致的训练GPU闲置问题。
实验结论
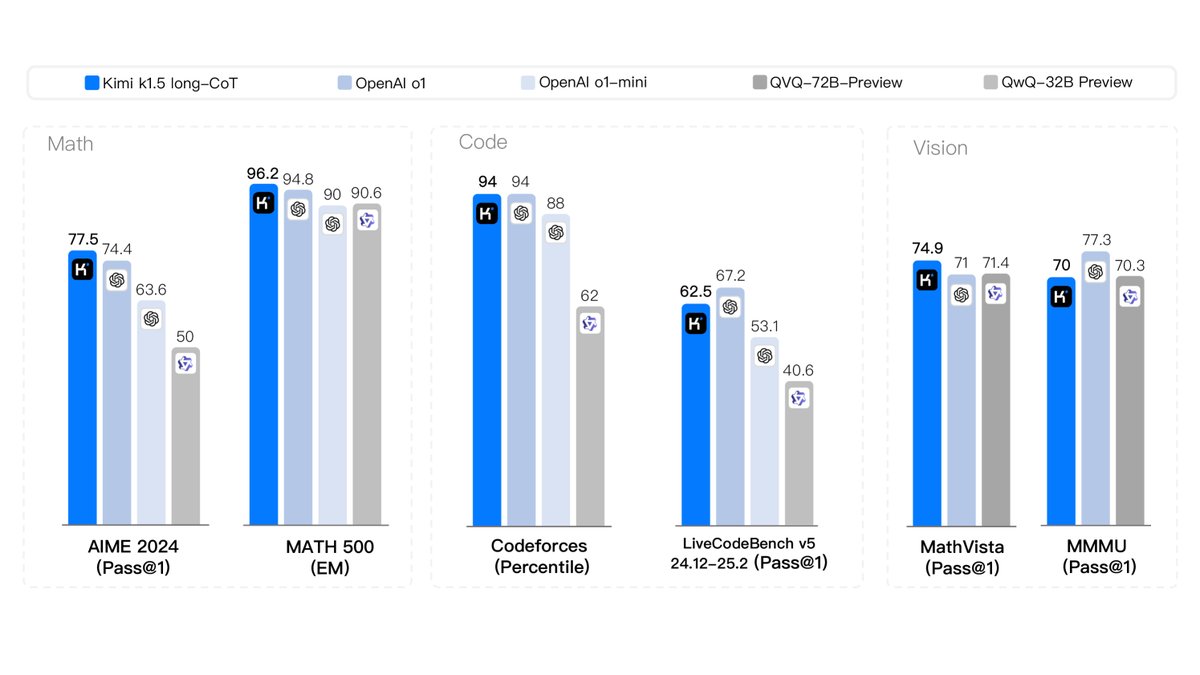
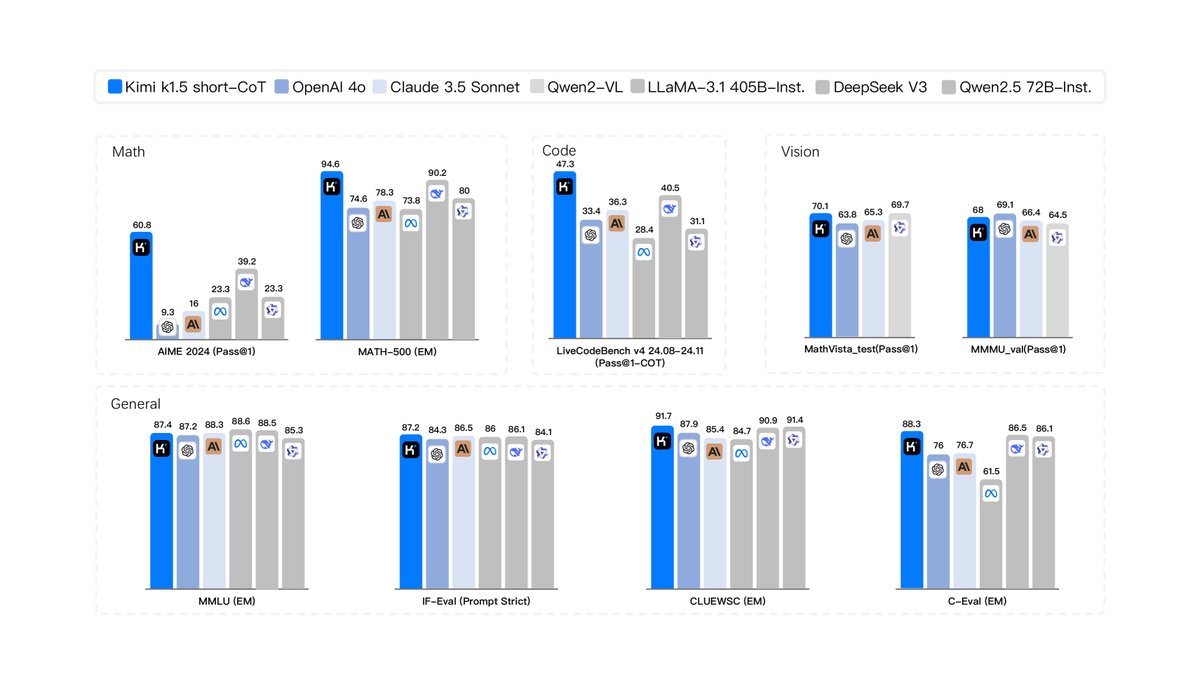
本文通过在多个权威基准测试上进行评估,验证了所提出方法的有效性。
- 主要优势与SOTA表现:
- Long-CoT模型: Kimi k1.5 在多个高难度的推理基准上取得了业界顶尖的性能,与OpenAI的o1模型表现相当。例如,在AIME上达到77.5分,在MATH 500上达到96.2分,在Codeforces上达到94百分位,在多模态推理MathVista上达到74.9分。
- Short-CoT模型: 通过本文提出的long2short技术,得到的Short-CoT模型同样取得了SOTA性能,并且大幅超越了现有的同类模型(如GPT-4o、Claude Sonnet 3.5)。例如,在AIME上达到60.8分,在MATH500上达到94.6分,在LiveCodeBench上达到47.3分。
- 验证的结论:
- 实验结果有力地证明,将RL与长上下文扩展相结合,是提升LLM推理能力的有效路径。
- 本文提出的简化RL框架(无价值网络、无MCTS)是可行的,并且能够达到顶尖性能。
- Long2short技术被证明是一种有效的知识蒸馏方法,能够成功地将大型、高成本模型的强大能力迁移到小型、高效的模型上,兼顾了性能与实用性。
- 表现平平或不佳的场景:
- 论文中未明确提及方法表现不佳或存在明显短板的场景,主要聚焦于其取得的SOTA成果。