Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
-
ArXiv URL: http://arxiv.org/abs/2509.16189v1
-
作者: Martin Engelcke; James L. McClelland; Arslan Chaudhry; Andrew Kyle Lampinen; Yuxuan Li
-
发布机构: Google DeepMind
TL;DR
- 本文认为当前AI系统的一个核心泛化缺陷是无法进行“潜在学习”(即学习与当前任务无关但可能对未来有用的信息),并证明了通过模拟情景记忆的检索机制可以弥补这一缺陷,使模型能更灵活地重用过往经验。
关键定义
本文的核心论点建立在对认知科学概念的借鉴和对机器学习泛化能力的重新审视之上。以下是理解本文至关重要的核心概念:
-
潜在学习 (Latent Learning): 指系统学习那些与当前任务没有直接关系,但可能在未来不同任务中有用的信息的能力。例如,一个智能体在不饿的时候探索迷宫,虽然没有寻找食物的动机,但它记住了食物的位置,以便在未来饥饿时能快速找到。本文认为,现有AI系统在大多数情况下缺乏这种能力,它们只学习与当前任务相关的信息。
-
互补学习系统 (Complementary Learning Systems): 这是一个源于神经科学的理论,认为大脑中存在两种互补的学习系统。一种是位于新皮层(neocortex)的慢速、参数化学习系统,它通过整合大量经验来形成泛化的知识;另一种是位于海马体(hippocampus)的快速学习系统,负责形成情景记忆(episodic memory),能够快速编码单个经验。本文认为,情景记忆(通过检索实现)可以补充参数化学习的不足,特别是在支持潜在学习方面。
-
潜在学习的形式化表述: 本文将潜在学习问题形式化。假设模型处理一个输入序列 $x=[x_{0},…,x_{k}]$ 和一个任务提示 $t$,并学习输出 $f(x,t)$。如果存在另一个与 $t$ 不同的任务 $t’$,模型虽然拥有在上下文中解决任务 $t’$ 的能力(即给定 $x$ 和 $t’$,能输出 $f(x,t’)$),但在训练时只见过 $[x,t,f(x,t)]$,那么仅靠参数化学习通常无法泛化到在没有上下文 $x$ 的情况下解决任务 $t’$(即无法解决 $[x’, t’, f(x’,t’)]$,其中 $x’$ 是空上下文)。情景记忆通过在需要时将原始上下文 $x$ 检索回来,将困难的无上下文泛化问题转化为简单的有上下文学习问题。
相关工作
-
研究现状与瓶颈:当前的AI系统,特别是深度学习模型如语言模型(LMs),虽然在许多任务上表现出强大的泛化能力,但也存在一些令人困惑的失败案例。例如,“逆转诅咒”(Reversal Curse),即模型从“A是B的父亲”学习后,无法推断出“B是A的儿子”。这些失败表明,模型的参数化学习(parametric learning)过程高度依赖于训练数据的表面形式和任务目标,难以学习和灵活应用数据中“潜在”的逻辑关系或信息。系统只在信息被当前任务明确或关联地提示时,才会应用它。
-
本文待解决的问题:本文旨在识别并解决AI系统与自然智能在泛化能力上的一个关键差距——缺乏潜在学习能力。具体来说,本文要阐明为什么AI系统无法将在一个任务中获得的特定信息灵活地应用到另一个足够不同的新任务中,并探索如何通过借鉴认知科学中的情景记忆概念来弥补这一差距。
本文方法
创新点
本文的核心创新并非提出一个全新的模型架构,而是提供了一个新的理论视角来解释现有AI系统的泛化缺陷,并验证了一个受认知科学启发的解决方案。
-
理论框架创新:首次将认知心理学中的“潜在学习”概念系统地引入AI泛化问题的讨论中,认为这是当前AI与自然智能的关键差距。这一框架统一了解释了从“逆转诅咒”到智能体导航失败等一系列看似不相关的泛化问题。
-
解决方案的重新诠释:本文将检索增强生成(Retrieval Augmented Generation, RAG)等现有技术置于“互补学习系统”的理论框架下。它论证了检索(作为情景记忆的模拟)不仅仅是提供额外知识,其根本优势在于能够将被动、固化的参数化知识(parametric knowledge)转化为主动、灵活的上下文内推理(in-context reasoning),从而解决参数化学习难以应对的潜在学习挑战。
-
揭示关键成功要素:本文发现,为了让检索机制有效发挥作用,一个关键因素是模型需要在训练数据中接触到能够促进“样本内上下文学习”(within-example in-context learning)的例子。这意味着,模型需要先学会在单个样本内部利用上下文信息解决问题,才能泛化到利用从“外部”(即其他样本)检索来的信息。
模型与机制
本文的方法是为标准的参数化模型(如Transformer)配备一个理想化的“神谕”情景检索系统(oracle episodic retrieval system)。
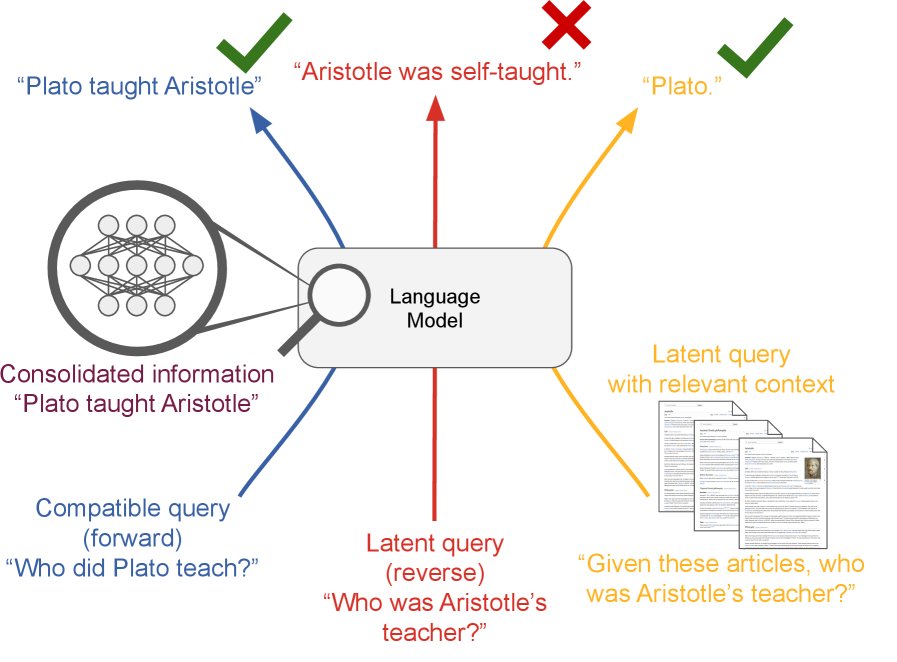
- 基本架构:在训练和测试期间,当模型处理一个任务时,系统会从过去的经验库(如训练数据集)中检索一个或多个相关的样本(文档或情节)。
- 信息整合:这些被检索到的相关样本会作为额外的上下文,被前置拼接到当前任务的输入序列中。
- 学习过程:模型(例如,一个decoder-only的Transformer)在包含检索内容的增强上下文上进行标准的自回归预测训练。 Importantly,模型不被训练去预测被检索到的内容本身,检索到的内容只作为上下文存在,但梯度会流过这部分上下文。
- 作用机制:通过这种方式,一个困难的、需要“无中生有”进行推断的潜在学习任务(如图1中的(d)),被转化成一个简单的、信息已在上下文中的读取和推理任务(如图1中的(c))。例如,对于逆转问题“谁教了亚里士多德?”,即使模型参数没有直接学到这个反向关系,但通过检索到原始句子“柏拉图教了亚里士多德”,模型就能在当前上下文中轻松回答。
 (a) 训练时,模型学习一个任务 t(例如,正向关系)。(b) 在没有上下文的情况下,模型无法泛化到潜在任务 t’(例如,逆转关系)。(c) 如果将包含原始信息的上下文 x 检索回来,模型就可以在上下文中解决任务 t’。(d) 这表明,检索机制可以弥补参数化学习在潜在学习上的不足。
(a) 训练时,模型学习一个任务 t(例如,正向关系)。(b) 在没有上下文的情况下,模型无法泛化到潜在任务 t’(例如,逆转关系)。(c) 如果将包含原始信息的上下文 x 检索回来,模型就可以在上下文中解决任务 t’。(d) 这表明,检索机制可以弥补参数化学习在潜在学习上的不足。
 本文通过一系列基准测试(从代码使用到迷宫导航)来展示潜在学习的挑战以及检索的优势。
本文通过一系列基准测试(从代码使用到迷宫导航)来展示潜在学习的挑战以及检索的优势。
实验结论
本文设计了四大类基准测试(Benchmarks)来系统地验证其核心假设。这些测试环境覆盖了从简单的语言事实推理到复杂的智能体导航任务。
 (a) Codebooks, (b) Simple Reversals, (c) Semantic Structure, (d) Latent Gridworld
(a) Codebooks, (b) Simple Reversals, (c) Semantic Structure, (d) Latent Gridworld
基准测试与核心发现
- Codebooks & Simple Reversals (简单任务)
- 任务描述:Codebooks任务要求模型学习并使用从未在编码示例中出现过的代码对。Simple Reversals任务测试模型能否回答在训练中未见过的反向关系问题。
- 实验结果:在这些任务中,标准的Transformer模型在常规泛化测试上表现良好,但在关键的“潜在学习”测试(如使用未见过的代码对、回答反向问题)上则完全失败。然而,当配备了神谕检索系统后,模型在这些潜在测试上的表现接近完美。
- 结论:这清晰地证明了参数化学习在潜在信息提取上的局限性,以及检索作为一种非参数化方法的强大补充作用。
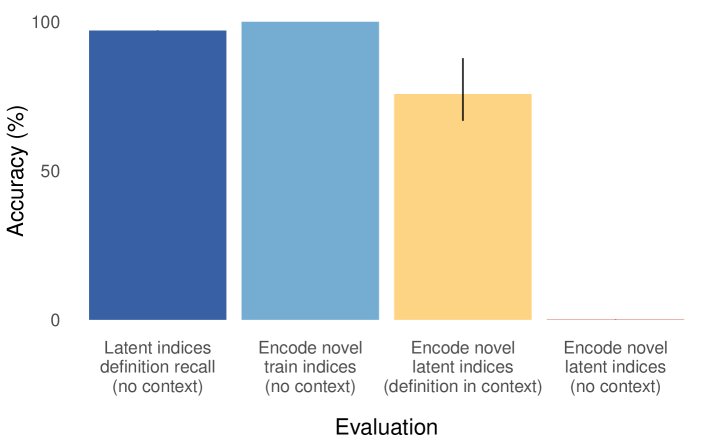 基线模型(左)能回忆定义(recall_def)、在上下文中编码(encode_ic-def)等,但无法在无上下文时对潜在代码对进行编码(encode_latent)。
基线模型(左)能回忆定义(recall_def)、在上下文中编码(encode_ic-def)等,但无法在无上下文时对潜在代码对进行编码(encode_latent)。 基线模型(左)能回答训练过的正向问题(trained_forward),但无法回答未训练的反向问题(held_out_reversal)。
基线模型(左)能回答训练过的正向问题(trained_forward),但无法回答未训练的反向问题(held_out_reversal)。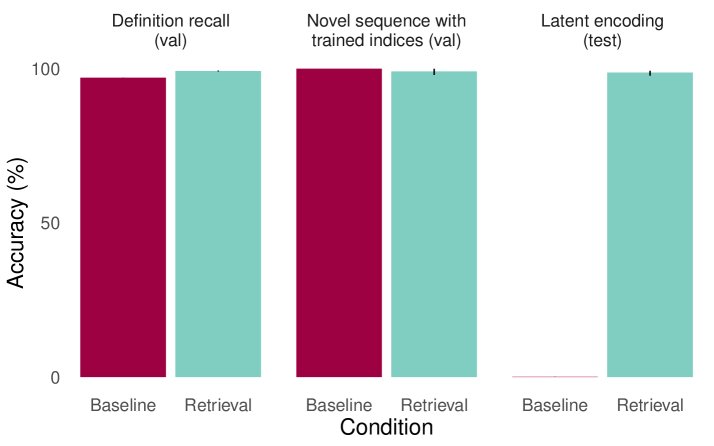 配备检索的模型(右)成功解决了潜在编码问题(encode_latent)。
配备检索的模型(右)成功解决了潜在编码问题(encode_latent)。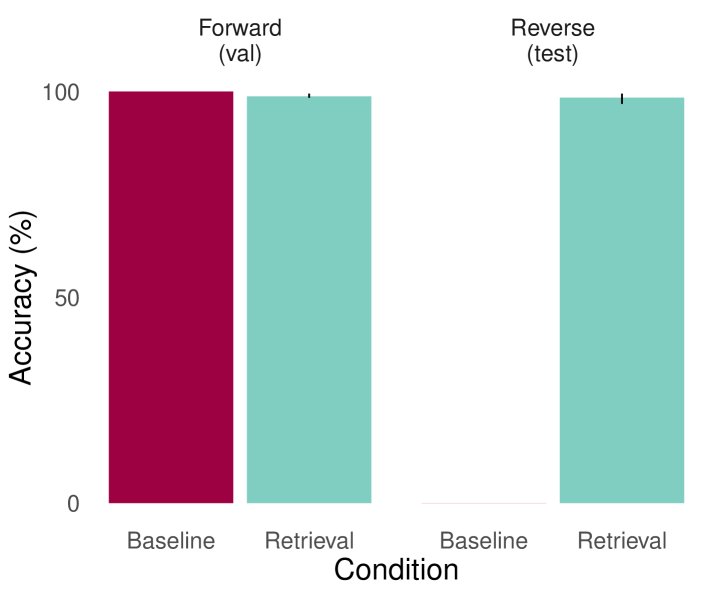 配备检索的模型(右)成功解决了反向问题(held_out_reversal)。
配备检索的模型(右)成功解决了反向问题(held_out_reversal)。 - Semantic Structure (复杂语义推理)
- 任务描述:该任务在一个复杂的语义知识图谱上测试模型的重述、逆转、三段论推理等能力。
- 实验结果:当存在强关联线索时(例如,“老鹰”和“翅膀”通过“鸟”强相关),基线模型也能表现出一定的泛化能力。但当这些关联线索被削弱后,基线模型性能大幅下降,而检索模型的优势变得更加明显。不过,在此任务上检索带来的提升相对有限,作者推测这是因为训练数据中缺乏清晰的、能促进模型学习如何利用上下文信息的ICL(In-Context Learning)样本。
- 结论:关联线索可以成为参数化泛化的一条捷径,但检索提供了一种更鲁棒的泛化路径。同时,这也揭示了有效利用检索需要模型具备相应的“上下文使用能力”。
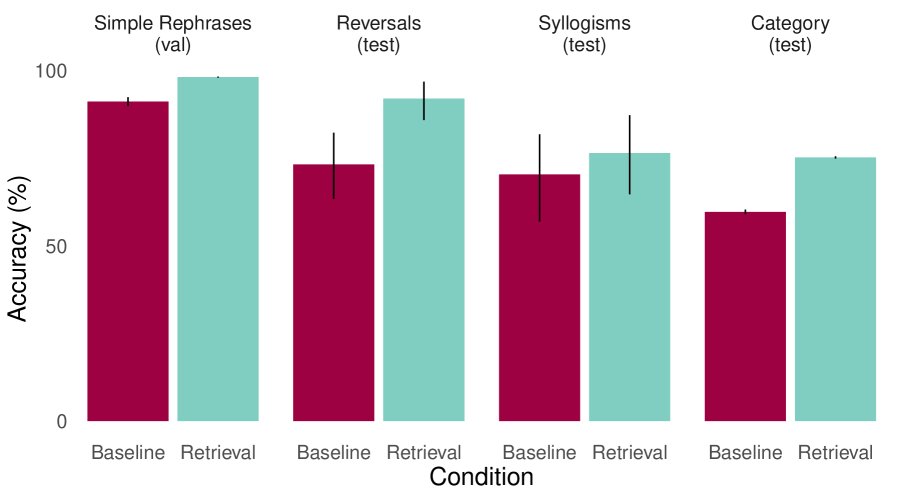 (上) 强关联线索下,基线和检索模型表现接近。 (下) 弱关联线索下,检索模型的优势在逆转(reversals)和三段论(syllogisms)等任务上更明显。
(上) 强关联线索下,基线和检索模型表现接近。 (下) 弱关联线索下,检索模型的优势在逆转(reversals)和三段论(syllogisms)等任务上更明显。 - Latent Gridworld Navigation (智能体导航)
- 任务描述:模拟经典的动物潜在学习实验。智能体在迷宫中为一些目标进行导航训练,但途中会经过一些从未被设为目标的“潜在物体”。测试时,要求智能体导航到这些潜在物体。
- 实验结果:无论是在基于强化学习(RL)还是行为克隆(BC)的设定下,配备了神谕检索(检索过去经过潜在物体附近的轨迹)的智能体在导航到潜在目标任务上的成功率都显著高于基线智能体。
- 结论:潜在学习的挑战不仅存在于语言模型中,同样存在于智能体学习中。情景记忆(通过检索实现)对于智能体灵活重用环境探索经验至关重要。
 (左图) RL Gridworld 任务中,检索模型在潜在目标(latent object)任务上成功率更高。 (右图) BC Gridworld 任务中,同样观察到检索在潜在目标任务上的显著优势。
(左图) RL Gridworld 任务中,检索模型在潜在目标(latent object)任务上成功率更高。 (右图) BC Gridworld 任务中,同样观察到检索在潜在目标任务上的显著优势。
总结
- 方法优势验证:实验结果在多种任务和学习范式中一致表明,标准的参数化模型存在“潜在学习”缺陷。而通过神谕检索来模拟情景记忆,可以有效弥补这一缺陷,显著提升模型在需要灵活重用过往经验的泛化任务上的表现。
- 关键因素识别:实验还发现,训练数据中包含促进“样本内上下文学习”的结构,对于模型学会如何利用“跨样本”的检索信息至关重要。没有这种基础能力,即使提供了相关信息,模型也无法有效利用。
- 最终结论:本文认为,与自然智能相比,当前AI系统数据效率较低的一个可能原因就是其无法进行有效的潜在学习。情景记忆检索提供了一条有前景的路径,它通过将固化的参数知识转化为灵活的上下文推理,补充了纯参数化学习的不足,从而实现更强大的泛化能力。这为理解RAG等技术的有效性提供了新的理论视角,并指明了为AI发展更有效的情景记忆系统是未来的一个重要研究方向。