Latent Traits and Cross-Task Transfer: Deconstructing Dataset Interactions in LLM Fine-tuning
-
ArXiv URL: http://arxiv.org/abs/2509.13624v1
-
作者: Taesung Lee; Shambhavi Krishna; Haw-Shiuan Chang; Atharva Naik
-
发布机构: Anthropic; University of Massachusetts Amherst
TL;DR
本文提出了一个基于性能矩阵和主成分分析(PCA)的分析框架,旨在系统性地解构大语言模型(LLM)微调过程中的跨任务迁移学习效应,并发现任务性能更多地受源数据集中隐藏的统计特征(如输出长度、类别分布)和特定语言特征的影响,而非表面上的领域相似性。
关键定义
本文主要沿用现有概念,但其核心贡献在于通过其分析框架识别并解释了以下影响迁移学习的“潜在特质 (Latent Traits)”:
- 推理能力 (Reasoning Ability):通过主成分分析识别出的一个潜在维度,关联了数学推理(GSM8K)、代码生成(Magicoder)和部分自然语言理解任务。这表明某些微调任务能同时提升模型在这些看似不同领域的逻辑推理和结构化输出能力。
- 分类能力 (Classification Ability):另一个主成分,主要关联了情感分类(Flipkart, Amazon, IMDB)、毒性检测(Pile)和释义识别(PAWS)等任务。这表明模型可以学习到一个通用的分类“元技能”,并将其在不同分类任务间迁移。
- 通用自然语言理解 (General NLU Performance):一个涵盖了数学、代码、自然语言推断和情感分析等多个任务的主成分,代表了模型在处理和理解多样化自然语言方面的基础能力提升。
- 大数算术能力 (Large Number Arithmetic):一个特定的主成分,主要在区分处理大数算术的Goat数据集和处理小数算术的GSM8K数据集时表现突出,表明算术能力可以被细分为不同的子技能,并且这些子技能的习得具有任务特异性。
相关工作
目前,关于语言模型微调中的迁移学习研究,大多集中于源任务和目标任务处于相同或相似领域的场景,通常采用完全微调 (full fine-tuning) 的方式。研究普遍认为,使用相似的域内数据能为目标任务带来积极的迁移效果。
然而,随着参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) 方法如低秩适应 (Low-Rank Adaptation, LoRA) 的普及,模型在实际部署中经常面临分布外 (Out-of-Distribution, OOD) 的请求。LoRA虽然被认为“学得更少,忘得也更少”,能更好地保留基座模型的通用能力,但其跨领域迁移的效果常常是反直觉且不可预测的:在一个任务上微调可能会意外提升或降低在另一个完全不相关任务上的性能。
本文旨在解决这一具体问题:如何系统性地理解和预测LoRA微调中源数据集对目标任务(特别是OOD任务)性能产生的复杂甚至反直觉的影响,从而为从业者在资源有限的情况下选择最优的微调数据集提供指导。
本文方法
本文提出了一个用于分析LLM微调中跨任务迁移效应的系统性框架。其核心思想不是提出一种新的模型架构,而是提供一种解构和理解现有微调方法(如LoRA)行为的分析流程。
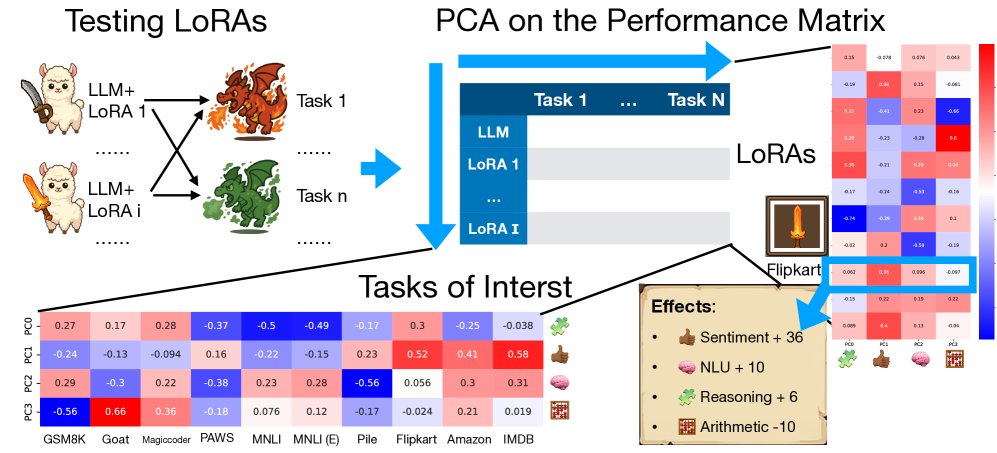
该框架主要包含以下步骤:
- 构建性能矩阵:首先,选择 $I$ 个源数据集对一个基础LLM进行微调,得到 $I$ 个不同的LoRA适配器。然后,在 $N$ 个目标任务(评估数据集)上测试这 $I$ 个微调后模型的性能。将所有结果整理成一个 $I \times N$ 的性能矩阵 $M$,其中 $M_{ij}$ 代表在第 $i$ 个数据集上微调的模型在第 $j$ 个任务上的性能得分。
- 应用主成分分析 (PCA):对构建的性能矩阵进行PCA分解。PCA能够识别出性能数据中的主要变化方向,即主成分 (Principal Components)。每个主成分可以被看作一个“潜在特质”或“能力组合”的抽象表示。在主成分对应的特征向量中,数值较高的任务意味着它们在该“潜在特질”上的表现高度相关。
- 解释潜在特质与分析:通过分析每个主成分中权重较高的任务的共同属性,对这些抽象的数学向量进行人工语义标注(例如,将其解释为“推理能力”或“分类能力”)。然后,可以将每个LoRA适配器投影到这些主成分上,得到一组权重,这组权重描绘了该LoRA在不同潜在特质上的“能力图谱”。例如,一个在情感分类数据集上训练的LoRA,其在“分类能力”特质上的权重会很高。
- 深入探究异常现象:利用PCA揭示的宏观模式和发现的异常点(例如,某个LoRA在看似不相关的任务上表现出奇的好或差),进行更深入的归因分析,探究是源数据集的哪些“隐藏”统计属性(如输出长度分布、类别不平衡度、特定语言结构等)导致了这些迁移效果。
创新点
- 视角创新:与传统关注任务语义或领域相似性的研究不同,本文将分析焦点转移到源数据集的隐藏统计特征上。它证明了这些底层特征(如文本长度、标签分布)是比表面任务描述更关键的迁移驱动因素。
- 方法创新:创造性地将PCA应用于跨任务性能矩阵,将复杂的、多对多的迁移关系分解为一组可解释的、低维的潜在特质。这种方法为量化和理解“副作用”和“意外增益”提供了一个系统性的数学工具。
优点
- 可解释性强:该框架不仅揭示了“什么”发生了迁移,还通过后续分析深入探究了“为什么”会发生,将抽象的性能变化与数据集中具体的、可度量的属性联系起来。
- 实践指导性:通过揭示不同数据集微调带来的潜在能力变化,该框架为开发者选择微调数据或预训练LoRA适配器提供了超越“领域匹配”的更深层次决策依据,有助于实现更可预测和高效的模型适配。
实验结论
本文通过在Llama 3.2 3B模型上进行一系列LoRA微调实验,系统性地验证了其分析框架的有效性,并揭示了多个反直觉的迁移学习现象。

PCA结果
对10个不同任务微调后的模型在所有任务上的性能矩阵进行PCA分析,发现前四个主成分(PCs)解释了大约75%的性能方差,并可被解释为不同的“潜在特质”:
- PC0 (通用性能): 在GSM8K(数学)、Goat(数学)、Magicoder(代码)和Flipkart(情感)上均有高正值,似乎代表了LoRA带来的普遍性能提升。
- PC1 (分类特质): 主要关联PAWS(NLI)、Pile(毒性)、Flipkart、Amazon和IMDB(情感),清晰地指向了分类任务的能力。
- PC2 (通用NLU性能): 关联了GSM8K, Magicoder, MNLI等多种任务,代表了更广泛的自然语言理解能力。
- PC3 (大数算术特质): 在Goat(大数算术)上为高正值,在GSM8K(小数算术)上为负值,表明模型区分并学习了不同类型的算术能力。
跨任务副作用系统分析
长度分布
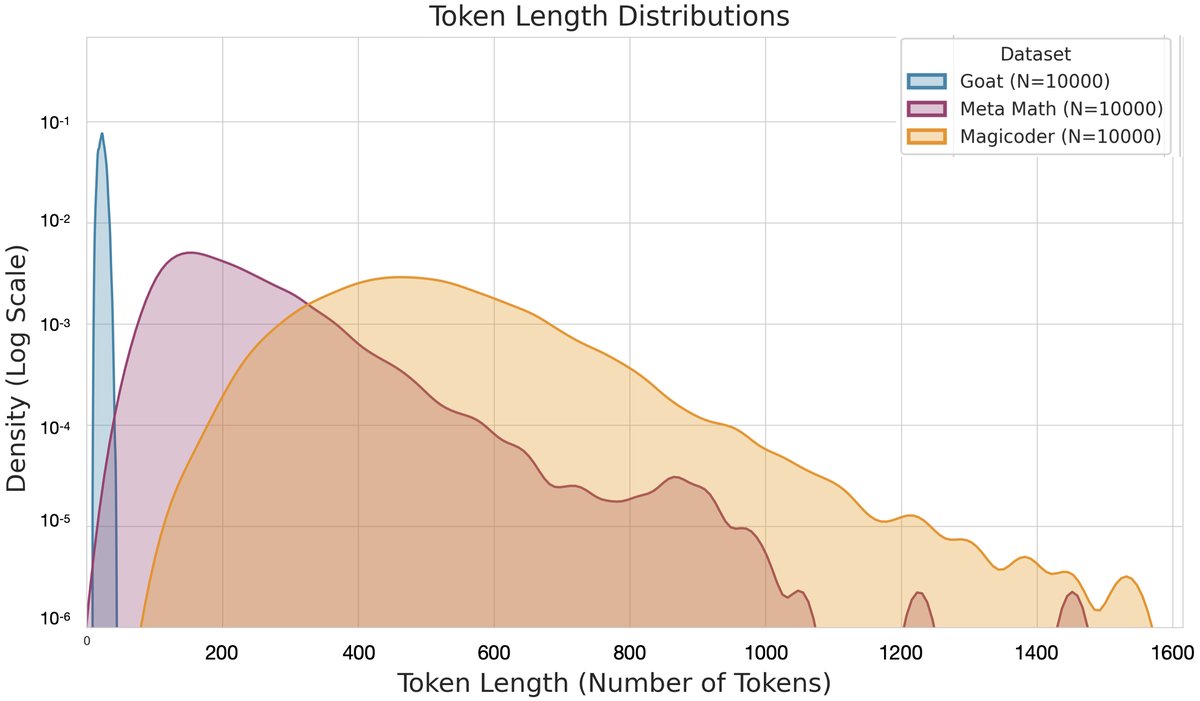
实验发现,模型在微调过程中会学习源数据集的输出长度倾向,并将其迁移到目标任务。一个显著的例子是,在GSM8K(数学推理)任务上,使用Magicoder(代码生成)进行微调的效果(+9.4%)远好于使用同为数学领域的Goat数据集(+3.64%)。深入分析发现,Magicoder的输出长度分布与GSM8K更相似,而Goat的输出则短得多。这表明,匹配的生成长度偏好是实现正向迁移的关键因素之一。模型似乎在基座模型的固有长度习惯和微调数据的新习惯之间进行“插值”。
类别分布
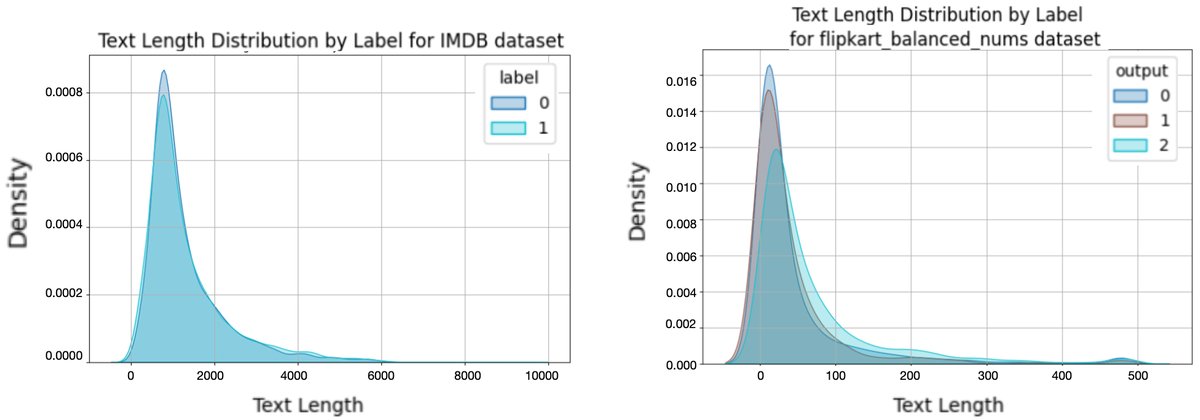
vs. [Pile](右)。](/images/2509.13624v1/cm2.jpg)
在分类任务中,源数据集的类别分布(标签不平衡性)会被模型学习并迁移。例如,在一个三分类的情感任务(Flipkart)上,使用IMDB(二分类)微调的模型倾向于做出明确的“积极/消极”判断,而使用Pile(毒性检测)微调的模型则更频繁地预测“中性”,这可能反映了Pile数据中存在更多模棱两可的语言。
为了进一步验证,本文构建了平衡与不平衡版的Flipkart数据集。实验表明,在需要无偏信号的任务(如毒性检测Pile)上,使用平衡数据集微调效果更好;而在与源数据具有相似不平衡分布的OOD任务(如IMDB)上,使用不平衡数据集微调反而更有利。这证明了类别分布本身就是一个可迁移的潜在特质。
vs. [Flipkart(Imbalanced)](右):0=负面,1=正面。](/images/2509.13624v1/flipkart_balanced_imb_imdb.jpg)
从分类到数学的迁移
一个最令人惊讶的发现是,在分类数据集上微调能显著提升数学推理能力。例如,在Flipkart(情感分类)上微调的模型在GSM8K任务上取得了14.59%的准确率,远高于基座模型的9.78%。
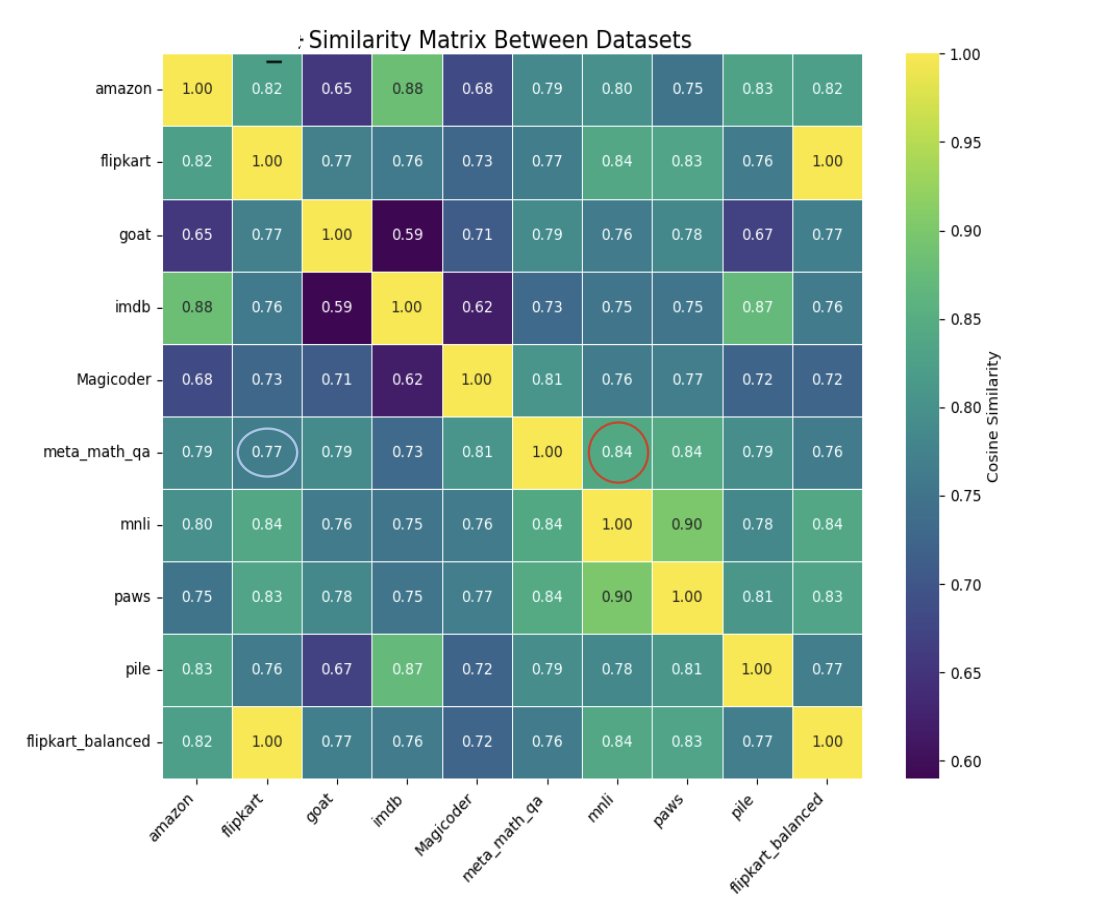
- 原因并非表面相似性:通过计算数据集间的文体相似性和语义相似性矩阵发现,这种性能提升与这些宏观相似度指标无关。例如,与数学数据文体最相似的MNLI数据集几乎没有带来性能提升。
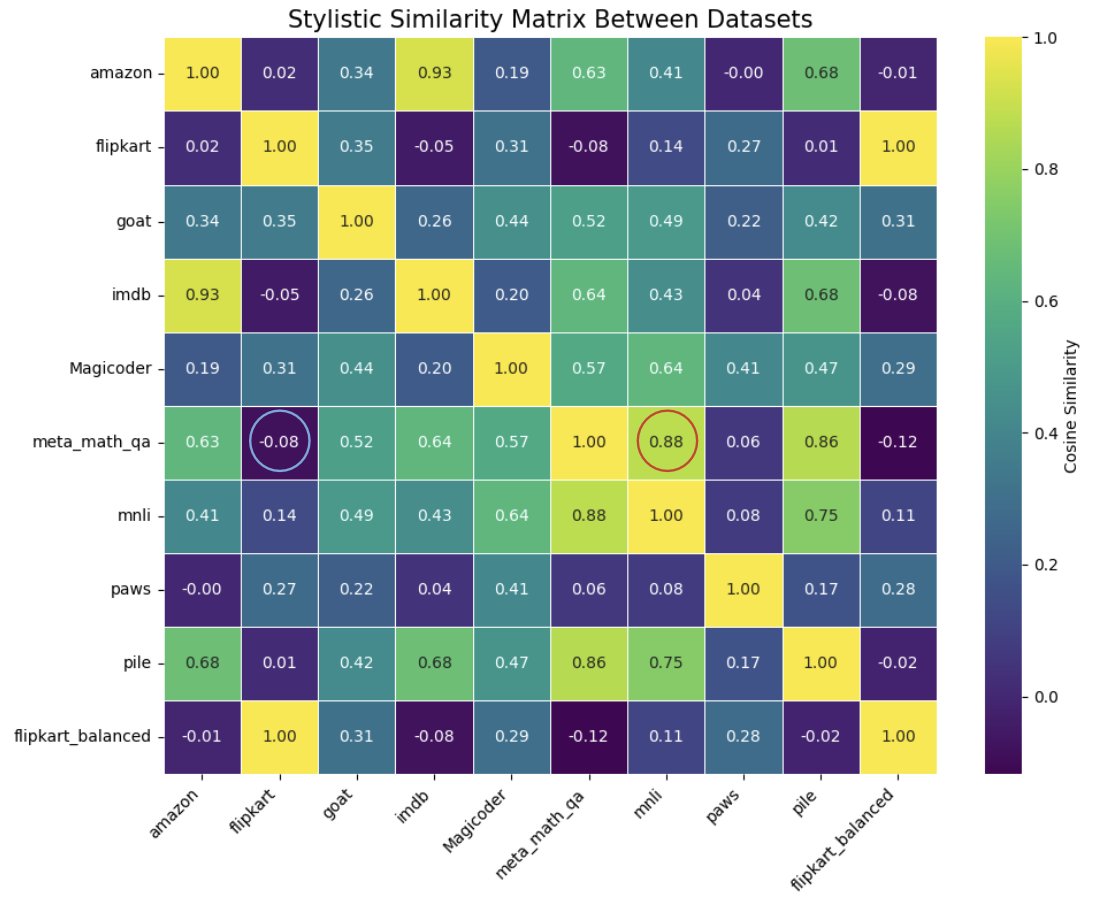
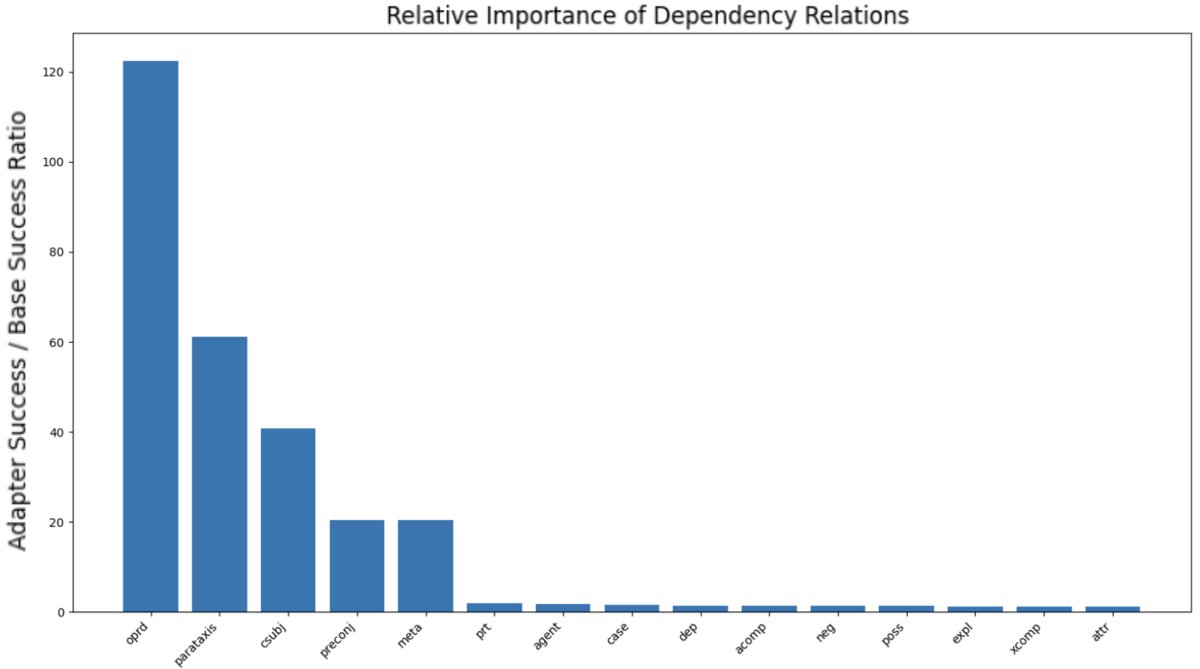
- 真正的原因:深入分析表明,提升源于模型增强了对特定语言结构(尤其是语法依存关系)的解析能力。分类任务的训练似乎迫使模型更精细地理解句子结构,以便做出正确判断。这种能力被迁移到数学应用题上,帮助模型更准确地将文本问题分解为正确的数学运算。例如,模型在识别标志运算对象的\(oprd\)依存关系上能力显著提高。
- 非对称迁移:这种技能迁移是非对称的。在分类任务上训练能提升数学能力,但反过来,在数学任务上训练却对分类任务性能有负面影响。
标签的重要性
为了探究模型到底学到了什么,本文还进行了在错误标签上进行微调的实验。结果发现,即使在标签完全错误的Amazon评论数据上进行微调,模型在IMDB和GSM8K等OOD任务上的表现与使用正确标签微调的模型相当,甚至略好。
| GSM8K | IMDB | Amazon | |
|---|---|---|---|
| [Amazon] | 15.85% | 48.65% | 79.50% |
| [Amazon-mislabeled] | 16.75% | 48.80% | 4.02% |
这表明,模型能够从数据中学习到超越表面标签的深层结构和模式。这些从输入文本本身学到的语言结构特征,可能比标签本身对OOD泛化更为重要。
总结
本文的研究证实,LLM的迁移学习行为远比传统认识复杂和反直觉,其性能表现并非由任务领域的表面相似性决定,而是深受源数据集所蕴含的潜在统计和语言特质的驱动。本文提出的分析框架为系统性地解构这些复杂的交互作用提供了有效工具。研究的核心结论是,诸如输出长度倾向、类别分布、以及对特定语法结构的敏感性等“隐藏”特征,是决定微调模型在OOD任务上成败的关键。这些发现为未来构建更加可预测、模块化的LLM适配策略(例如,为智能体系统动态加载“简洁性适配器”或“句法解析适配器”)铺平了道路。