Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
-
ArXiv URL: http://arxiv.org/abs/2304.13705v1
-
作者: Tony Zhao; Chelsea Finn; Vikash Kumar; S. Levine
-
发布机构: Meta; Stanford University; University of California, Berkeley
TL;DR
本文提出了一套名为 ALOHA 的低成本开源双臂遥操作硬件系统,并结合一种名为 ACT 的新型模仿学习算法,通过预测动作序列(Action Chunking)而非单步动作,成功地让低成本机器人学会了多种以往需要昂贵设备才能完成的精细操作任务。
关键定义
- ALOHA (A Low-cost Open-source Hardware System for Bimanual Teleoperation):一套作者构建的低成本(<$20k)双臂遥操作硬件。它使用现成的机器人臂(ViperX 和 WidowX)和3D打印组件,通过关节空间映射(joint-space mapping)的方式,让操作员能够直观地控制机器人,以收集高质量、高频率的精细操作演示数据。
- 动作分块 (Action Chunking):本文提出的核心算法思想。传统方法一次预测一个动作,而动作分块是指策略模型一次性预测未来 \(k\) 个时间步的动作序列。这种方法将任务的有效时域缩短了 \(k\) 倍,从而显著缓解了模仿学习中的“误差累积”问题。
- 时序集成 (Temporal Ensembling):一种在推理阶段使用的技术,用于平滑机器人动作。系统在每个时间步都查询策略模型(而非每 \(k\) 步),从而产生重叠的动作块。对于任意一个时间步,系统会汇集(加权平均)来自不同次预测中针对该时间步的动作指令,使得最终执行的动作更加平滑连贯。
- ACT (Action Chunking with Transformers):本文提出的模仿学习算法全称。该算法使用 Transformer 架构来实现动作分块,并采用条件变分自编码器(Conditional VAE, CVAE)进行训练,以有效建模人类演示数据中固有的多模态和噪声特性。
相关工作
当前,精细操作任务(如穿线、装电池)通常依赖于价格昂贵、精度极高的高端机器人和传感器。虽然模仿学习(Imitation Learning)为使用低成本硬件提供了可能,但它存在一个致命弱点:误差累积 (compounding errors)。策略在执行过程中产生的微小误差会随时间不断累积,导致机器人进入一个从未在训练数据中见过的陌生状态,最终导致任务失败,这个问题在需要高精度的精细操作中尤为严重。
现有的误差累积缓解方案,或需要繁琐的在线专家干预(如 DAgger),或局限于低维状态空间,不适用于直接从高维像素(图像)学习的场景。
因此,本文旨在解决的核心问题是:如何让低成本、低精度的机器人硬件,通过直接从图像学习的方式,成功执行高精度的、需要闭环反馈的复杂双臂操作任务?
本文方法
本文的贡献包含两个协同工作的部分:一个用于数据收集的低成本遥操作硬件系统 ALOHA,以及一个用于学习的创新算法 ACT。
ALOHA:低成本遥操作硬件系统
为了获取高质量的精细操作演示数据,本文设计并搭建了 ALOHA 系统。
- 设计原则:低成本、功能多样、用户友好、易于维修和搭建。
- 硬件构成:该系统由两对机器人臂组成,一对较大的 ViperX 6自由度机械臂作为“执行端”(follower),一对较小的同品牌 WidowX 机械臂作为“领导端”(leader)。操作员通过直接反向驱动(backdriving)领导端机械臂来控制执行端,两者之间采用关节空间映射,避免了逆运动学(IK)在奇异点附近失效的问题。
- 创新设计:为提升遥操作体验,作者设计了3D打印的“手柄与剪刀”机制,方便操作员控制夹爪的开合与机械臂的移动。同时,还设计了橡皮筋重力平衡装置,以减轻操作员的负担。
- 感知系统:系统配备了四台消费级网络摄像头,两台安装在机器人手腕上提供特写视角,另外两台提供全局的前方和顶部视角。
 图1:ALOHA系统,用户通过驱动领导臂来遥操作执行臂。该系统能够完成穿拉链扣、玩乒乓球等需要精确、动态和丰富接触的任务。
图1:ALOHA系统,用户通过驱动领导臂来遥操作执行臂。该系统能够完成穿拉链扣、玩乒乓球等需要精确、动态和丰富接触的任务。
 图3:ALOHA的多个摄像头视角、工作空间示意图、以及定制的夹爪和“手柄剪刀”操作装置。
图3:ALOHA的多个摄像头视角、工作空间示意图、以及定制的夹爪和“手柄剪刀”操作装置。
ACT:基于Transformer的动作分块算法
针对误差累积问题,本文提出了 ACT 算法,其核心思想是学习一个能生成动作序列的策略。
创新点
-
动作分块 (Action Chunking):算法的核心创新。策略 $\pi_{\theta}(a_{t:t+k} \mid s_t)$ 不再是根据当前状态 $s_t$ 预测单个动作 $a_t$,而是预测未来 \(k\) 个时间步的整个动作序列 $a_{t:t+k}$。这相当于将任务的决策频率降低了 \(k\) 倍,显著减少了误差累积的机会。此外,它还能更好地处理人类演示中常见的非马尔可夫行为(如暂时的停顿)。
-
时序集成 (Temporal Ensembling):为避免每 \(k\) 步才进行一次决策导致的动作卡顿,ACT在每个时间步都运行策略,生成重叠的动作块。对于当前时间步 \(t\) 的动作,会存在多个来自过去预测的候选动作。ACT通过加权平均(新预测的权重更高)将这些动作融合成一个指令,从而产生平滑且反应迅速的轨迹。
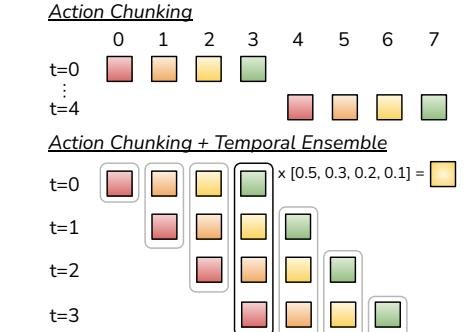 图5:ACT在推理时采用动作分块和时序集成。它并非“观察-执行”交替进行,而是在每个时间步都进行预测,并对重叠的动作块进行加权平均。
图5:ACT在推理时采用动作分块和时序集成。它并非“观察-执行”交替进行,而是在每个时间步都进行预测,并对重叠的动作块进行加权平均。
- 使用CVAE建模人类数据:人类演示天然存在噪声和多模TAI性(同一个状态下可能有多种有效操作)。为解决此问题,ACT被建模为一个条件变分自编码器 (CVAE)。
- 架构:模型包含一个CVAE编码器和一个CVAE解码器(即策略本身),均用Transformer实现。
- 训练:训练时,编码器将观测和真实的动作序列压缩为一个隐变量 $z$(代表动作“风格”),解码器(策略)则学习根据观测和 $z$ 重构出该动作序列。损失函数包含重构损失(L1 loss)和KL散度正则项。
- 推理:推理时,丢弃编码器,将隐变量 $z$ 固定为先验分布的均值(即0),从而使策略产生确定性的、高质量的动作序列。
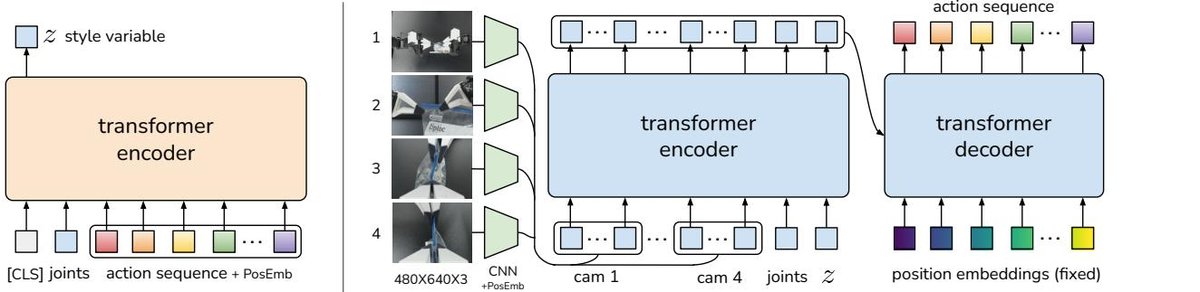 图4:ACT架构图。左侧是只在训练时使用的CVAE编码器,它将动作序列和关节状态压缩为隐变量z。右侧是CVAE解码器(即策略),它融合多视角图像、关节状态和隐变量z,通过Transformer编解码器来预测一个动作序列。
图4:ACT架构图。左侧是只在训练时使用的CVAE编码器,它将动作序列和关节状态压缩为隐变量z。右侧是CVAE解码器(即策略),它融合多视角图像、关节状态和隐变量z,通过Transformer编解码器来预测一个动作序列。
算法流程总结
- 训练 (Algorithm 1):从演示数据集 $\mathcal{D}$ 中采样观测 $o_t$ 和对应的未来 \(k\) 步动作序列 $a_{t:t+k}$。通过CVAE框架训练策略网络 $\pi_{\theta}$ 和编码器 $q_{\phi}$。
- 推理 (Algorithm 2):在每个时间步 \(t\),获取当前观测 $o_t$,令隐变量 $z=0$,调用策略 $\pi_{\theta}(\hat{a}_{t:t+k} \mid o_t, z)$ 预测未来 \(k\) 步的动作。将这些预测动作存入缓冲区,并通过时序集成计算出最终要执行的当前动作。
实验结论
本文在2个模拟任务和6个真实世界的精细操作任务(如拉开自封袋、安装电池、打开调料杯、穿魔术贴带等)上对ACT进行了评估。
| 任务 (数据来源) | BC-ConvMLP | BeT | RT-1 | VINN | ACT (本文) |
|---|---|---|---|---|---|
| 方块传递 (模拟, 脚本) | 34 | 60 | 44 | 13 | 97 |
| 方块传递 (模拟, 人类) | 3 | 16 | 4 | 17 | 82 |
| 双臂插入 (模拟, 脚本) | 17 | 51 | 33 | 9 | 90 |
| 双臂插入 (模拟, 人类) | 1 | 13 | 2 | 11 | 60 |
| 拉开自封袋 (真实) | 5 | 27 | 28 | 3 | 88 |
| 安装电池 (真实) | 0 | 1 | 20 | 0 | 96 |
表I: 4个任务上的成功率(%)对比。ACT在所有任务和数据类型上均大幅超越之前的方法。
| 任务 (真实世界) | Tip Over | Open Lid | — | Total | |
|---|---|---|---|---|---|
| BeT | 12 | 0 | — | 0 | |
| ACT (本文) | 100 | 84 | — | 84 | |
| 任务 (真实世界) | Lift | Grasp | Insert | Total | |
| BeT | 0 | 0 | 0 | 0 | |
| ACT (本文) | 96 | 92 | 20 | 20 | |
| 任务 (真实世界) | Grasp | Cut | Handover | Hang | Total |
| BeT | 24 | 0 | 0 | 0 | 0 |
| ACT (本文) | 96 | 72 | 100 | 64 | 64 |
| 任务 (真实世界) | Lift | Insert | Support | Secure | Total |
| BeT | 8 | 0 | 0 | 0 | 0 |
| ACT (本文) | 100 | 92 | 92 | 92 | 92 |
表II: 另外4个真实世界任务的子任务及最终成功率(%)对比。ACT表现优异,而表现最好的基线方法BeT在这些复杂任务上成功率为0。
- 验证的优势:
- 有效性:实验结果表明,ACT在所有8个任务上均以巨大优势(例如,在安装电池任务中成功率为96%,而其他方法接近0)超越了所有基线方法(包括BC-ConvMLP, BeT, RT-1, VINN)。这证明了本文提出的系统和算法能够有效学习并完成低成本硬件上的精细操作。
- 动作分块的重要性:消融实验证实,动作分块是性能提升的关键。随着分块大小 \(k\) 的增加,所有方法的性能都显著提升。这表明动作分块是一种普适且有效的技术,能有效缓解误差累积。
- CVAE的必要性:实验显示,在使用随机性更强的人类演示数据进行训练时,CVAE目标至关重要;若移除CVAE,模型性能会从35.3%骤降至2%。
- 高频控制的必要性:用户研究表明,50Hz的高频遥操作控制相比于5Hz的低频控制,能让任务完成时间平均缩短62%,证明了高频反馈对于精细操作的重要性。
-
表现不佳的场景: 在“穿魔术贴带 (Thread Velcro)”任务中,ACT的最终成功率较低(20%)。失败的主要原因是感知挑战:黑色的魔术贴带与黑色背景对比度低,且目标在图像中占比较小,导致系统难以精确定位,从而在空中抓取或对准插入时失败。
- 最终结论: 本文成功证明,通过将精心设计的低成本遥操作硬件(ALOHA)与创新的模仿学习算法(ACT)相结合,可以使廉价的机器人系统掌握以往只有高端设备才能完成的、对精度和闭环反馈要求极高的精细操作技能。其核心算法创新“动作分块”为解决模仿学习中的误差累积问题提供了强有力的方案。