Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
-
ArXiv URL: http://arxiv.org/abs/2510.08002v1
-
作者: Daocheng Fu; Pinlong Cai; Licheng Wen; Haifeng Li; Yufan Shen; Xuemeng Yang; Yu Qiao; Jianbiao Mei; Rong Wu; Cheng Yang; 等12人
-
发布机构: Central South University; Fudan University; Shanghai Artificial Intelligence Laboratory; Shanghai Innovation Institute; Zhejiang University
TL;DR
本文提出了MUSE,一个经验驱动的自进化智能体 (Agent) 框架,通过一个分层的记忆模块和“计划-执行-反思-记忆”的闭环系统,使智能体能够在执行长时程任务中持续学习、积累经验并实现自我进化。
关键定义
本文提出或沿用了以下对理解其核心思想至关重要的概念:
- MUSE (Memory-Utilizing and Self-Evolving):一个新颖的智能体框架,其核心是一个经验驱动的闭环系统。它使智能体能够通过与环境的交互动态积累经验,从而超越预训练模型的静态能力,实现持续学习和自我进化。
- 记忆模块 (Memory Module, $\mathcal{M}$):MUSE的核心组件,一个分层的记忆系统,由三种不同抽象级别的记忆组成,用于存储和组织从任务中学习到的经验。
- 策略记忆 (Strategic Memory, $\mathcal{M}_{\text{strat}}$):存储宏观层面的行为范式,以\(<困境, 策略>\)键值对的形式记录智能体在解决复杂挑战时的经验教训,用于指导全局任务策略。
- 程序化记忆 (Procedural Memory, $\mathcal{M}_{\text{proc}}$):以标准操作流程 (Standard Operating Procedures, SOPs) 的形式,归档智能体成功完成子任务的执行轨迹。它被组织成一个层级知识库,供智能体在处理类似任务时查询和复用。
- 工具记忆 (Tool Memory, $\mathcal{M}_{\text{tool}}$):作为智能体使用单个工具的“肌肉记忆”,包含工具的静态描述和动态指令,指导智能体在工具使用后的即时下一步行动,并随经验积累而优化。
- 计划-执行智能体 (Planning-Execution Agent, PE Agent):负责将复杂任务分解为一系列子任务,并使用增强的ReAct循环来执行这些子任务。它能够根据记忆模块中的知识进行决策,并通过与环境的交互完成具体操作。
- 反思智能体 (Reflect Agent):作为独立的监督者,在每个子任务执行后进行自主评估。它通过验证事实、交付物和数据保真度来判断任务成功与否,并将成功的轨迹提炼为新的记忆,或在失败时生成分析报告以指导PE智能体重新规划。
相关工作
目前,大型语言模型 (LLM) 驱动的智能体在问答、数学推理等特定领域取得了显著进展,但将它们应用于现实世界的长时程任务时仍面临严峻挑战。现有的评估环境(如OSWorld、WebArena)大多关注单一平台内的短时程任务,无法充分体现真实世界任务的复杂性,这些任务通常需要跨越多个应用、涉及上百个步骤。
最关键的瓶颈是,现有的大多数智能体在测试时是静态的 (test-time static)。它们的能力在模型训练完成后即被固定,无法从过去的成功或失败中学习,每次执行任务都像一个“失忆的执行者”。这种“一次性”的交互模式严重限制了它们在复杂动态环境中的表现,无法实现真正的“在职学习 (learning on the job)”。
本文旨在解决这一核心问题:如何让智能体摆脱静态限制,构建一个能够通过经验积累实现持续学习和自我进化的系统,以有效处理现实世界中的长时程、跨应用生产力任务。
本文方法
框架概述
本文提出了MUSE框架,旨在通过在测试时学习 (test-time learning) 来解决长时程生产力任务 ($\mathcal{T}_{\text{prod}}$),而无需微调LLM。MUSE的核心是一个“计划-执行-反思-记忆 (Plan-Execute-Reflect-Memorize)”的迭代闭环。其架构包含三个关键组件:记忆模块 ($\mathcal{M}$)、计划-执行智能体 (PE Agent) 和反思智能体 (Reflect Agent)。
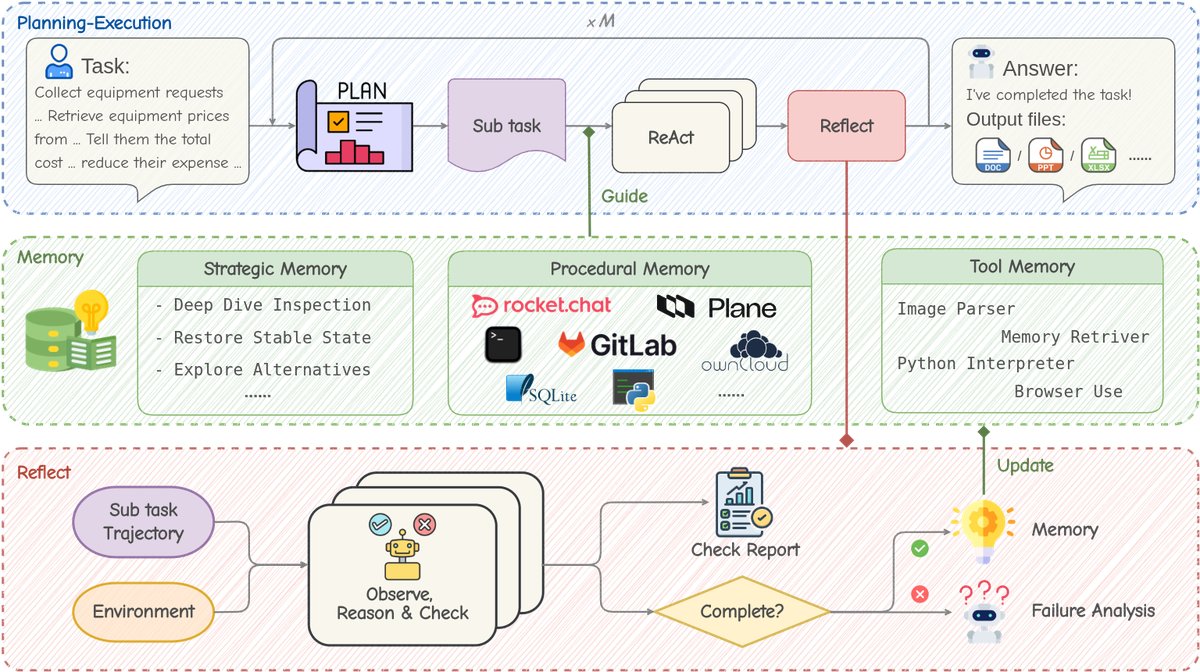
整个工作流程如下:
- 计划 (Plan):当接收到新任务时,PE智能体首先将任务分解为一个有序的子任务队列。
- 执行 (Execute):对于每个子任务,PE智能体查询记忆模块以获取相关经验指导,然后在一个包含多种软件(如聊天应用、代码编辑器、浏览器)的交互式环境 $\mathcal{E}$ 中,使用一套预定义的基础工具集 $\mathcal{A}_{\text{tool}}$ 执行一系列动作。
- 反思 (Reflect):在每个子任务尝试结束后,反思智能体无需人工干预,自主评估其执行轨迹。如果成功,它将轨迹提炼为新的经验;如果失败,它会生成失败分析,并指示PE智能体重新规划。
- 记忆 (Memorize):在整个任务完成后,反思智能体对完整的执行轨迹进行全面分析,将提炼出的程序化、策略性和工具层面的经验整合到记忆模块 $\mathcal{M}$ 中,从而增强智能体未来的任务处理能力。
记忆模块
记忆模块 ($\mathcal{M}$) 是MUSE实现在职学习的关键。它是一个复合记忆体 $\mathcal{M}={\mathcal{M}_{\text{strat}}, \mathcal{M}_{\text{proc}}, \mathcal{M}_{\text{tool}}}$,将经验分层存储,并以自然语言格式保存,使其与LLM无关,便于跨模型迁移。
-
策略记忆 ($\mathcal{M}_{\text{strat}}$):专注于从智能体多次尝试才解决的困境中提炼高层指导。反思智能体将这些“问题-解决方案”经验抽象为\(<困境, 策略>\)键值对。该记忆在智能体初始化时完全加载到系统提示中,以指导全局行为,并在每次任务后进行精简和更新,保持简洁高效。
-
程序化记忆 ($\mathcal{M}_{\text{proc}}$):将成功的子任务执行轨迹存档为标准操作流程 (SOPs),形成一个层级知识库。为平衡效率和性能,系统采用轻量级的主动检索机制:启动时只加载SOP索引,PE智能体可在需要时使用内置工具主动查询详细的SOP内容,模拟人类专家查阅案例的方式。
-
工具记忆 ($\mathcal{M}_{\text{tool}}$):作为智能体使用单个工具的“肌肉记忆”,由两部分组成:静态描述 ($D_{\text{static}}$),在启动时加载,解释工具核心功能;动态指令 ($I_{\text{dynamic}}$),在工具使用后随环境观察返回,指导下一步行动。该记忆在任务结束后由反思智能体更新,以持续优化工具使用效率。
计划-执行智能体
PE智能体负责管理和执行复杂的生产力任务。
-
任务分解与动态重规划:PE智能体首先将主任务 $\tau$ 分解为子任务队列 $Q=[st_1, st_2, \dots, st_M]$。在每个子任务执行后,它会根据新信息和反思智能体的评估,重新审视并更新队列 $Q$,确保计划的适应性和鲁棒性,有效防止错误累积。
-
基于记忆的ReAct循环:PE智能体使用一个记忆增强的ReAct循环来处理子任务。在每个“思考-行动-观察” ($\theta_t, a_t, o_t$) 的迭代中,智能体可以主动查询程序化记忆 $\mathcal{M}_{\text{proc}}$ 来获取指导。为防止卡在无效循环中,每个子任务尝试有最大动作数 $N$ 的限制。若达到上限,反思智能体介入评估并给予一次重试机会,鼓励智能体在重试时探索新方法。
-
最小化工具集:与追求集成大量专用API的思路不同,MUSE为智能体配备了一套最小但功能强大的通用工具集 $\mathcal{A}_{\text{tool}}$(如浏览器交互、代码解释器、Shell等)。本文认为,智能的核心在于创造性地组合基础工具,而非机械调用预定义函数。这一设计也旨在验证MUSE能否将成功的解决方案转化为可复用的程序化记忆,实现能力自进化。
反思智能体
反思智能体扮演着独立的第三方监督者角色,以应对PE智能体可能出现的幻觉或失败。
-
评估与验证:当PE智能体完成子任务或达到动作上限时,反思智能体被触发。它根据一个包含真实性验证、交付物验证和数据保真度的检查清单,通过两种方法进行评估:回溯式检查 (trace-back),将PE智能体的结论追溯到历史观察记录;以及主动式检查 (active-check),主动使用工具与环境交互以交叉验证关键信息。
-
记忆生成与更新:评估后,反思智能体输出成功/失败标志 $f$。若成功,它将有效的操作序列总结为新的SOP并存入 $\mathcal{M}_{\text{proc}}$。若失败,则生成失败原因分析报告。在整个大任务结束后,反思智能体对整个记忆系统 $\mathcal{M}$ 进行全面升级,包括提炼策略记忆、增强工具记忆,并对所有三类记忆进行去重、泛化和整合。
实验结论
本文在专为长时程生产力任务设计的TheAgentCompany (TAC) 基准上对MUSE框架进行了评估。该基准包含175个任务,模拟了真实企业环境,需要智能体在操作系统内使用多种应用完成复杂操作。
连续学习实验
为了验证MUSE的持续学习能力,本文选取了TAC中的18个任务构成子集 $\mathcal{T}_{\text{cl}}$ 进行实验。实验模拟了人类积累经验的过程:智能体连续三次迭代完成所有18个任务,每次迭代都继承前一次积累的记忆。
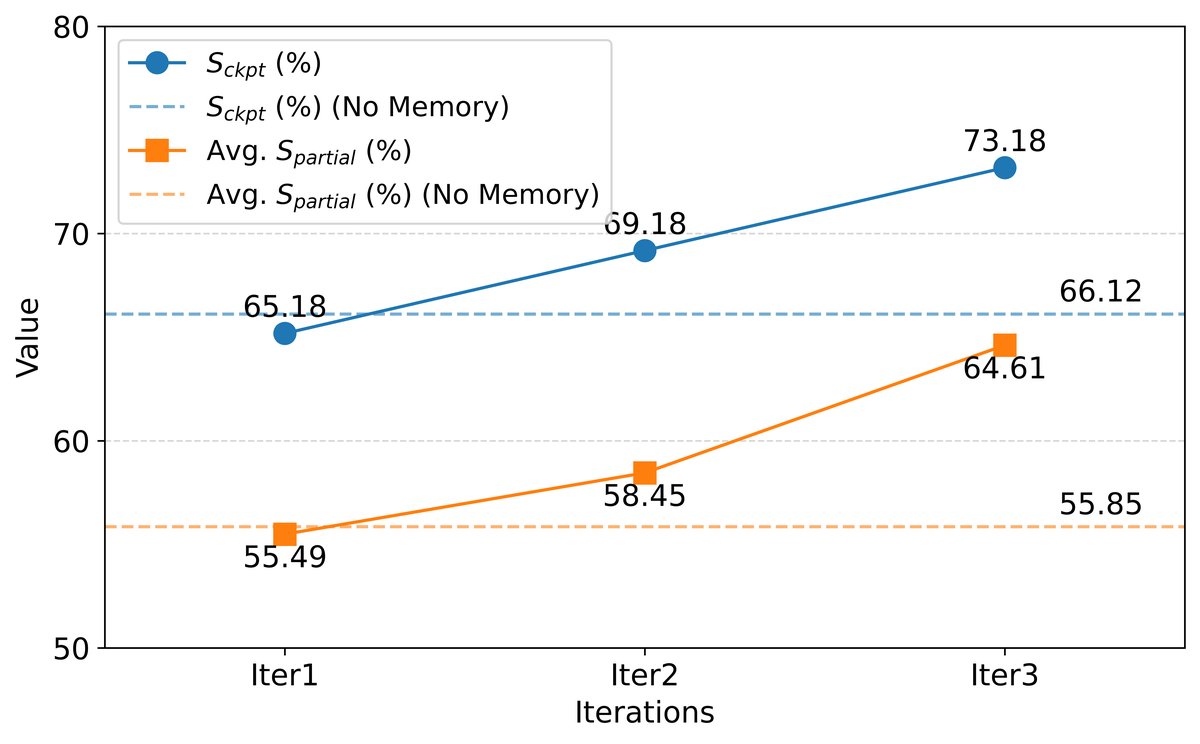
实验结果如上图所示。
- 性能持续提升:随着迭代次数的增加,MUSE的检查点完成率 ($S_{\text{ckpt}}$) 和平均部分完成分 ($S_{\text{partial}}$) 均呈现显著的稳步增长。这表明,随着智能体通过与环境交互自主积累经验,其任务完成能力和效率确实在不断提高。
- 超越基线:与不带记忆模块的基线模型相比,经过三轮学习的MUSE在性能上实现了巨大飞跃,有力地证明了经验驱动的自进化机制的有效性。
整体性能
- 达到新SOTA:在使用轻量级的Gemini-2.5 Flash模型的情况下,MUSE在完整的TAC基准测试中取得了51.78% 的部分完成分,相较于之前的SOTA实现了20%的相对提升,创造了新的纪录。
- 经验泛化:实验还表明,MUSE积累的经验具有很强的泛化能力,能够在新任务上实现零样本 (zero-shot) 性能提升。
最终结论是,MUSE框架通过其创新的经验驱动、自我进化的闭环设计,成功使智能体能够在执行长时程任务中“在职学习”,持续提升自身能力,为实现能够胜任真实世界生产力任务的AI智能体开辟了新的范式。