Less LLM, More Documents: Searching for Improved RAG
-
ArXiv URL: http://arxiv.org/abs/2510.02657v1
-
作者: Jamie Callan; Yibo Kong
-
发布机构: Carnegie Mellon University
TL;DR
本文通过系统性实验证明,在检索增强生成(Retrieval-Augmented Generation, RAG)系统中,扩大检索语料库的规模可以作为一种有效的替代方案来弥补使用较小语言模型(LLM)所带来的性能差距,为构建更高效、更易于部署的RAG系统提供了新的权衡思路。
关键定义
本文为量化语料库与生成器之间的权衡关系,提出了几个关键的分析指标:
-
语料库补偿阈值 ($n^{\star}$):指一个较小的模型($M_{x_{small}}$)需要多大的语料库规模($n$),才能达到一个较大的模型($M_{x_{large}}$)在基准语料库规模($n=1$)下的性能。该指标用于量化语料库规模对模型规模的“补偿”效应。其形式化定义为:
\[n^{\star}(x_{small}\!\to\!x_{large})\;:=\;\min_{m\in\{\text{F1},\,\text{EM}\}}\;\min\big\{n\,:\,P_{m}(n,x_{small})\,\geq\,P_{m}(1,x_{large})\big\}\] -
正确率提升(Correctness Boost, CB@n):衡量在提供 $n$ 个语料库分片(shards)后,那些在无检索($n=0$)情况下回答错误的问题中,有多大比例转为回答正确。该指标用于剥离模型自身记忆知识的影响,专注于衡量由检索带来的性能增益。
\[\mathrm{CB}@n\;:=\;\Pr\!\big(EM_{n\text{-shard}}=1\,\big \mid \,EM_{0\text{-shard}}=0\big)\] -
利用率(Utilization Ratio@n):衡量模型在多大程度上能够利用检索到的、包含正确答案的上下文来生成正确答案。它被定义为“正确率提升”与“黄金答案覆盖率”(即检索到的上下文中包含标准答案的概率)的比值。
\[\mathrm{Ratio}@n\;:=\;\frac{\mathrm{CB}@n}{\mathrm{Coverage}@n}\]这个比率反映了模型将“可用的证据”转化为“正确答案”的效率。
相关工作
当前,提升RAG系统性能的主流方法是扩大生成器(即LLM)的规模。虽然更大的模型确实能带来更高的准确率,但其高昂的计算成本和部署难度限制了其实用性。与此同时,检索模块作为RAG系统的另一关键部分,其作用是为生成器提供外部知识以保证事实性、减少幻觉,但语料库规模与生成器大小之间的关系尚未得到充分探索。
已有的研究大多孤立地分析模型大小、语料库或上下文长度等单一变量,缺乏对它们之间相互作用的系统性理解。特别是,关于扩大检索语料库能否替代扩大LLM规模这一核心权衡问题,仍然是一个悬而未决的开放问题。
因此,本文旨在解决这一具体问题:系统性地研究RAG系统中检索语料库规模与LLM模型大小之间的权衡关系,并探究在何种条件下,扩大语料库可以有效补偿使用较小LLM带来的性能损失。
本文方法
本文设计了一个系统性的实验框架来分析语料库与生成器之间的权衡关系。其核心思想是将语料库规模和模型大小作为两个可调变量,通过全因子实验设计来量化它们对RAG系统性能的综合影响。
创新点
本文的创新之处不在于提出一种新的模型架构,而在于建立了一套严谨的、可量化的实验方法学来研究RAG系统中一个基础且重要但被忽视的权衡问题。主要体现在以下几个方面:
-
可控的语料库扩展:为了模拟语料库的规模化,本文将一个大规模的固定语料库(ClueWeb22的一个子集)随机划分为 $N$ 个大小近似相等且不相交的分片(shards)。通过逐步激活 $n$(从1到 $N$)个分片,可以精确地控制和扩展检索范围,从而研究语料库规模的影响。
\[\Pi(\mathcal{C})\;\to\;\{S_{1},S_{2},\ldots,S_{N}\},\quad S_{i}\cap S_{j}=\varnothing\;\;\forall\,i\neq j,\quad\bigcup_{i=1}^{N}S_{i}=\mathcal{C}\]规模为 $n$ 的语料库定义为 $\mathcal{C}^{(n)}=\bigcup_{i=1}^{n}S_{i}$。
-
同源的模型家族:为了隔离模型架构差异带来的影响,本文选用了一个同源、多尺寸的开源模型家族(Qwen3),涵盖了从0.6B到14B的多个参数规模。这保证了模型大小是生成器侧唯一的变量。
-
权衡关系的量化:通过全因子实验(配对每个语料库规模 $n$ 和每个模型大小 $x$),本文能够绘制出性能曲线,并使用前面定义的关键指标,特别是 $n^{\star}$,来精确量化“需要多少额外的文档(语料库)来弥补模型参数的不足”。
优点
该方法的主要优点是其系统性和可解释性。它将“语料库规模”从一个通常被视为固定基础设施的组件,转变为一个与“模型大小”同等重要的、可调节的系统设计参数。这种方法使得研究人员和工程师能够:
- 做出有数据支撑的设计决策:在计算资源受限时,可以根据实验结论判断是应该投入更多资源来扩大语料库,还是升级LLM。
- 理解性能提升的来源:通过分析“黄金答案覆盖率”和“利用率”等中间指标,可以清晰地揭示性能增益是来自于检索到了更好的信息,还是模型更有效地利用了信息。这为针对性优化提供了方向。
实验结论
本文在一系列受控实验中系统评估了语料库规模与LLM大小的权衡关系,得出了清晰且具有实践指导意义的结论。
语料库规模可以补偿模型大小
实验结果明确表明,扩大检索语料库能够有效让较小的模型达到甚至超过较大模型的性能。
- 补偿效应显著:在中等到较大模型区间,补偿效果尤其明显。例如,在NQ数据集上,一个4B模型仅需将语料库扩大一倍($n^{\star}(4\text{B}!\to!8\text{B})=2$),其性能就能赶上8B模型;类似地,8B模型也只需扩大一倍语料库就能赶上14B模型。
- 小模型补偿成本高:对于非常小的模型(如0.6B),需要更大规模的语料库(在NQ上需要$5\times$,在TriviaQA上需要$10\times$)才能追赶上稍大的模型,这表明在模型能力过低时,仅靠扩大语料库效率不高。
- 趋势具有普遍性:这一发现在NQ、TriviaQA和WebQ三个标准问答数据集上都得到了一致的验证。
| 模型 | $M_{0.6B}$ | | $M_{1.7B}$ | | $M_{4B}$ | | $M_{8B}$ | | $M_{14B}$ | | :—: | :—: | :—: | :—: | :—: | :—: | :—: | :—: | :—: | :—: | | 语料库倍数 | F1 | EM | F1 | EM | F1 | EM | F1 | EM | F1 | EM | | 1$\times$ | 44.1 | 30.5 | 49.3 | 35.5 | 52.4 | 38.0 | 54.4 | 40.0 | 55.4 | 40.9 | | 2$\times$ | 46.8 | 32.7 | 51.5 | 37.5 | 54.6 | 40.3 | 56.4 | 41.9 | 57.3 | 42.6 | | 4$\times$ | 48.7 | 34.4 | 53.6 | 39.1 | 56.6 | 42.2 | 58.0 | 43.1 | 58.7 | 43.7 | | 5$\times$ | 49.3 | 35.1 | – | – | – | – | – | – | – | – | | 10$\times$| 50.8 | 36.3 | 55.1 | 40.5 | 58.1 | 43.4 | 59.4 | 44.4 | 60.1 | 44.9 | <p align="center">NQ数据集上的F1/EM得分。阴影单元格表示较小模型首次超越下一级别模型在1x语料库下的性能点($n^{\star}$)。</p>

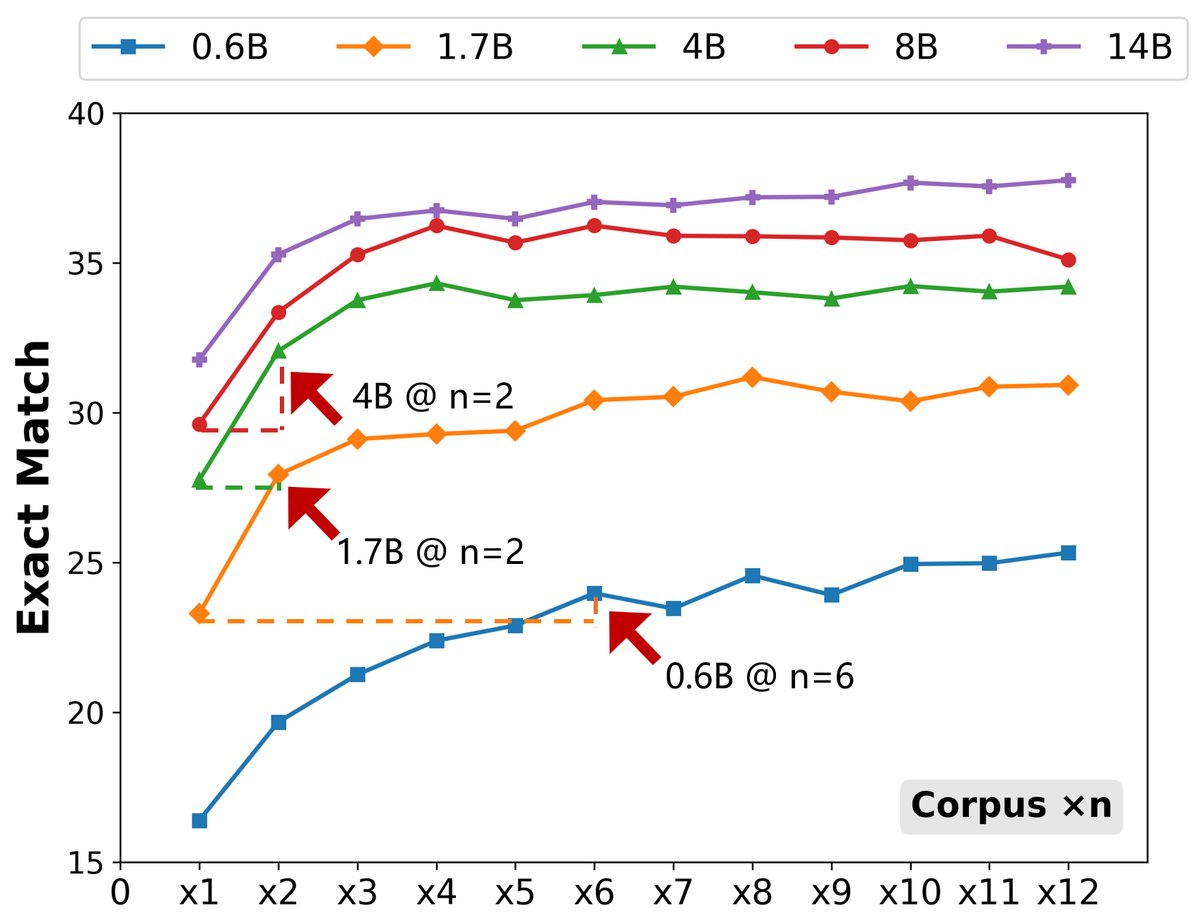
性能提升的根本原因
本文深入分析了性能提升的机制,发现其主要归因于检索质量的提高,而非模型利用效率的改变。
- 核心驱动力是覆盖率:扩大语料库显著提高了检索到的上下文中包含标准答案(Gold Answer)的概率。这意味着模型有更大的机会接触到回答问题所需的关键信息。
- 模型利用率保持稳定:实验表明,不同大小的模型在将可用信息转化为正确答案的效率(即利用率)上并没有随语料库规模的扩大而系统性提升。这个比率在不同模型和语料库规模下都保持在一个相对稳定的窄带内。
- 中等模型利用率更高:一个有趣的发现是,上下文利用率并非随模型规模单调递增。中等大小的模型(1.7B和4B)在某些情况下表现出比最大模型(14B)更高的利用率,这表明并非总是“模型越大,上下文利用得越好”。
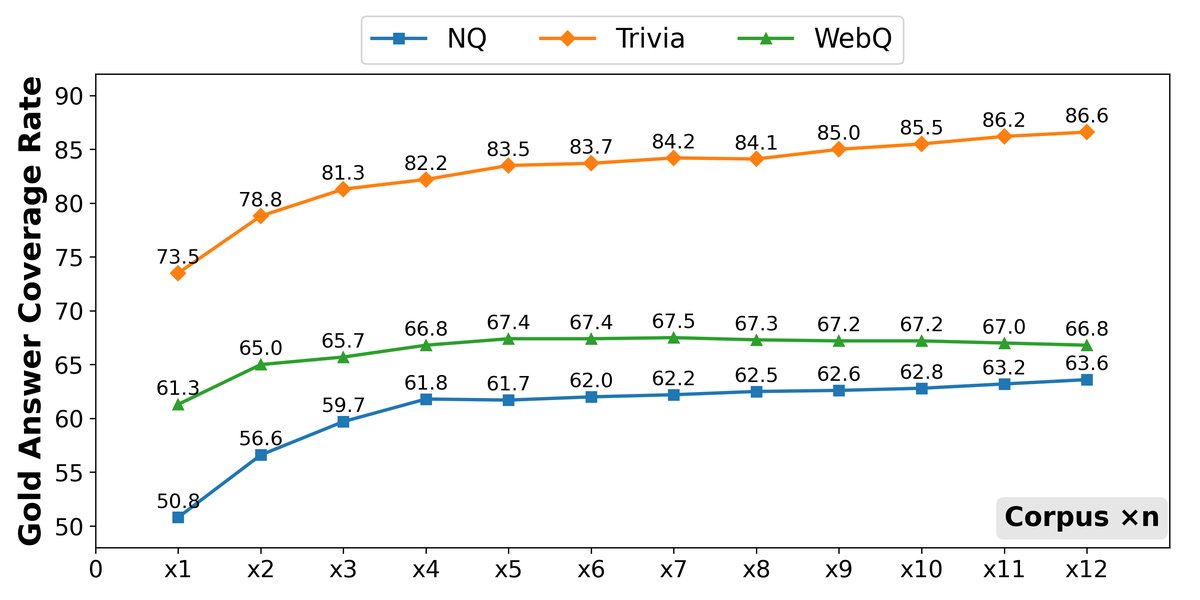
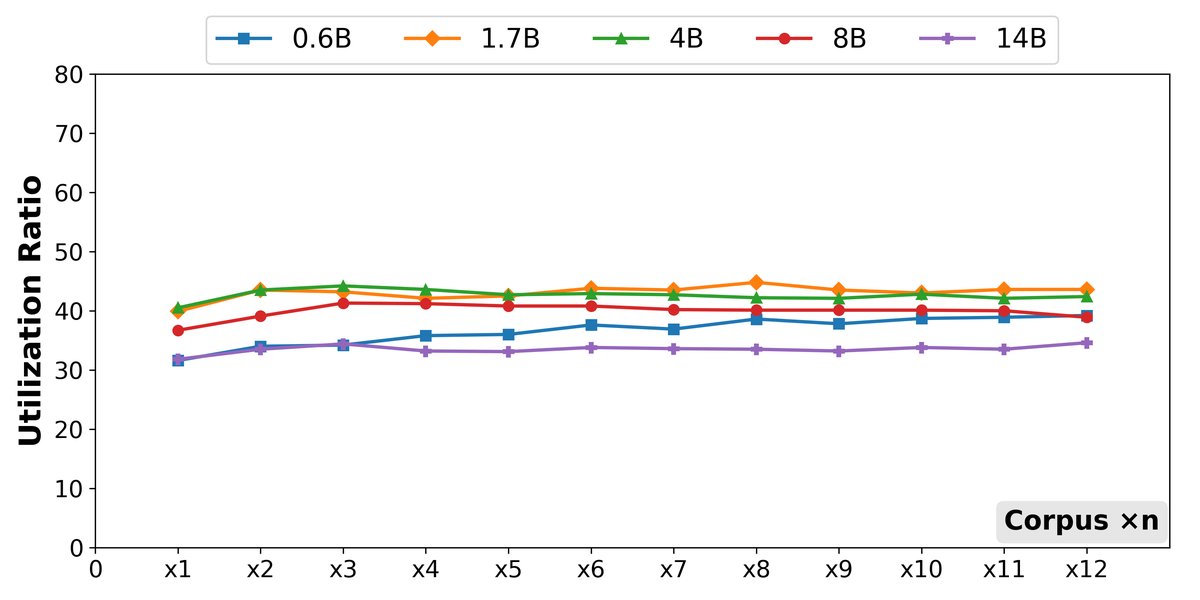
最终结论
本文的结论清晰而有力:在RAG系统中,“更多的文档”确实常常可以替代“更大的模型”。当面临推理成本或部署环境的限制时,投资于扩大和优化检索语料库是一个非常有效的策略。性能的提升主要源于语料库扩大后,为模型提供了更高质量(即包含答案)的证据。同时,研究也指出了其边界:语料库规模的收益会递减,通常在扩大5-6倍后趋于饱和。这一发现为设计兼顾性能与效率的RAG系统提供了重要的实践指导。