Let’s Verify Step by Step
-
ArXiv URL: http://arxiv.org/abs/2305.20050v1
-
作者: Teddy Lee; Harrison Edwards; Hunter Lightman; I. Sutskever; Yura Burda; K. Cobbe; Jan Leike; John Schulman; Bowen Baker; Vineet Kosaraju
-
发布机构: OpenAI
TL;DR
本文通过在极具挑战性的MATH数学数据集上进行实验,证明了过程监督 (Process Supervision) 在训练奖励模型方面显著优于结果监督 (Outcome Supervision),其训练出的模型能更可靠地解决复杂的多步推理问题。
关键定义
- 结果监督 (Outcome Supervision, ORM): 一种训练奖励模型的方法,仅根据模型生成的解题步骤链的最终结果(正确或错误)来提供反馈。
- 过程监督 (Process Supervision, PRM): 另一种训练奖励模型的方法,对解题步骤链中的每一个中间步骤都提供反馈(例如,标记该步骤是否正确)。
- PRM800K: 本文发布的一个大规模数据集,包含了80万个人工对模型生成的数学解题步骤进行的逐步反馈标签,用于训练过程监督奖励模型。
- 主动学习 (Active Learning): 在数据收集过程中,并非随机选取样本让标注员进行标注,而是策略性地选择那些最有可能“迷惑”当前最佳奖励模型的样本(即被模型高分评价但最终答案错误的解法),以提高标注效率。
相关工作
当前的大型语言模型虽然能够通过“思维链”等方式生成多步推理过程,但仍然频繁出现逻辑错误或“幻觉”。训练一个奖励模型来区分好的和坏的输出来引导模型生成或进行搜索,是提升其可靠性的有效方法。
先前已有工作(Uesato et al., 2022)对比了结果监督和过程监督,但在较为简单的数学任务上发现两者最终性能相近。这留下了几个关键问题:在更复杂的任务上,哪种监督方式更优?如何更高效地利用昂贵的人工反馈?
本文旨在解决这些问题,通过使用更强大的基础模型、更多的反馈数据、以及更具挑战性的MATH数据集,对这两种监督方法进行一次更详尽、更大规模的对比研究。
本文方法
本文的核心是比较两种训练奖励模型的方法:结果监督(ORM)和过程监督(PRM)。其评估标准是看哪个奖励模型能更好地从生成模型产生的N个解法中,挑选出正确的那个(Best-of-N)。
方法概览
本文的研究不涉及通过强化学习(RL)来优化生成器模型本身,而是专注于如何训练最可靠的奖励模型。实验分为两种规模:
- 大规模: 基于GPT-4进行微调,目标是训练出最强的ORM和PRM,以推动现有技术水平。
- 小规模: 为了进行更公平、可控的对比实验(如消融研究),使用大规模PRM作为“合成教师”(synthetic supervisor),为小规模模型的训练提供标签。
数据收集与PRM800K
为了获得过程监督所需的数据,本文雇佣了人类标注员对模型针对MATH问题生成的解法进行逐步骤的标注。
- 标注界面: 标注员为每个步骤打上“积极”(正确且合理)、“消极”(错误或不合理)或“中性”(模棱两可)的标签。
 Figure 1: 用于收集每个解题步骤反馈的界面截图。
Figure 1: 用于收集每个解题步骤反馈的界面截图。
- 主动学习策略: 为了最大化人工标注的价值,本文采用主动学习策略。优先选择那些被当前最佳PRM模型给予高分、但最终答案却错误的“有说服力的错误解法”(convincing wrong-answer solutions)进行标注。因为模型在这些解法上肯定犯了错,标注它们能提供最有价值的信息。
- 数据集: 最终收集了包含80万个步骤级标签的 PRM800K 数据集。
过程监督奖励模型 (PRM)
- 训练: PRM被训练用于预测每个解题步骤后的token是否正确。这个预测任务可以整合到标准的语言模型训练流程中。
- 评分: 在评估一个完整解法时,其PRM分数被定义为所有步骤都是正确的概率的乘积。
- 监督范围: 为了与结果监督进行更公平的比较,对于错误的解法,过程监督只提供到第一个错误步骤为止的标签。这样做统一了两种方法的信息量级(都只确认了至少存在一个错误),并控制了标注成本。
Figure 2: 由PRM评分的同一问题的两个解法。左侧正确,右侧错误。绿色背景表示PRM高分,红色表示低分。PRM成功识别了错误解法中的错误步骤。
结果监督奖励模型 (ORM)
- 训练: ORM被训练用于预测一个完整的解法是否正确。其标签通常通过自动检查最终答案来获得。
- 评分: 在评估时,使用ORM在最后一个token上的预测值作为整个解法的分数。
- 局限性: ORM的一个主要问题是,模型可能用错误的推理过程得到了正确的答案(“假阳性”),而ORM会错误地将其标记为好的解法。
实验结论
大规模实验对比
在大规模实验中,PRM使用了PRM800K数据集进行训练,而ORM在一个规模大一个数量级、均匀采样的数据集上训练。尽管训练集不完全对等,但都代表了各自监督方法下的最佳实践。
- 主要结果: 如图3所示,PRM的性能在所有采样数量(N)下都显著优于ORM和多数投票(Majority Voting)基线。并且随着N的增加,PRM的优势愈发明显,这表明PRM在大量候选解中进行搜索的能力更强。
- SOTA性能: 最终,本文的PRM模型在一个有代表性的MATH测试子集上解决了78.2%的问题。
 Figure 3: 不同奖励模型在best-of-N选择上的性能比较。PRM(蓝色)显著优于ORM(绿色)和多数投票(红色)。
Figure 3: 不同奖励模型在best-of-N选择上的性能比较。PRM(蓝色)显著优于ORM(绿色)和多数投票(红色)。
小规模合成监督实验
为了进行更严格的受控实验,本文使用训练好的大规模PRM(称为\(PRMlarge\))作为标注者,来模拟人类反馈。
- 过程 vs. 结果监督: 如图4a所示,在所有数据量下,过程监督的性能都远超两种形式的结果监督(一种是基于最终答案检查,另一种是基于\(PRMlarge\)的整体判断)。这证明了过程监督的内在优势。
- 主动学习效果: 如图4a中的虚线所示,采用主动学习策略的数据效率是均匀采样的2.6倍。这意味着达到相同的性能,主动学习需要的数据量要少得多。
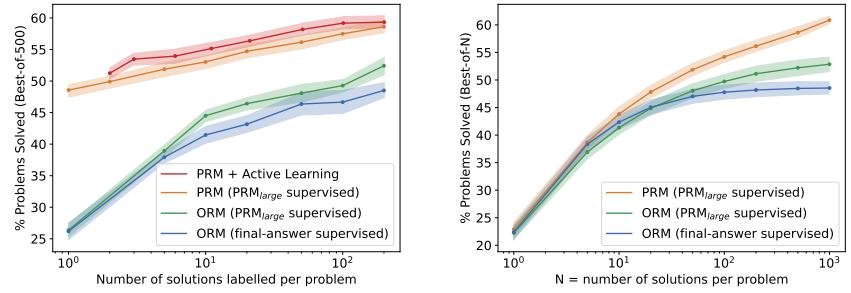 Figure 4: 不同形式监督方法的对比。(a)展示了随着数据量增加,各方法的性能变化,过程监督(蓝色)优势明显,主动学习(紫色虚线)效率更高。(b)展示了在不同N值下,各方法的best-of-N性能。
Figure 4: 不同形式监督方法的对比。(a)展示了随着数据量增加,各方法的性能变化,过程监督(蓝色)优势明显,主动学习(紫色虚线)效率更高。(b)展示了在不同N值下,各方法的best-of-N性能。
分布外泛化能力 (OOD)
在全新的、模型从未见过的STEM竞赛题(如AP物理、微积分,AMC10/12等)上进行测试,结果如下表所示。
- 结果: PRM的性能依然全面优于ORM和多数投票,证明了其强大的泛化能力,其优势并非仅限于MATH数据集。
| 领域 | ORM | PRM | 多数投票 | 问题数 |
|---|---|---|---|---|
| AP微积分 | 68.9% | 86.7% | 80.0% | 45 |
| AP化学 | 68.9% | 80.0% | 71.7% | 60 |
| AP物理 | 77.8% | 86.7% | 82.2% | 45 |
| AMC10/12 | 49.1% | 53.2% | 32.8% | 84 |
| 总计 | 63.8% | 72.9% | 61.3% | 234 |
核心结论
- 过程监督更优: 过程监督通过提供更精确的反馈,显著简化了模型的信用分配(credit assignment)问题,使其能够训练出比结果监督更可靠的奖励模型。
- 负“对齐税”: 过程监督不仅性能更强,而且本质上更安全、更可解释,因为它直接奖励人类认可的推理过程,而非仅仅一个结果。这意味着采用更安全的对齐方法(过程监督)反而带来了性能提升,作者称之为“负对齐税” (negative alignment tax)。
- 主动学习有效: 主动学习能显著提升数据标注效率,是降低过程监督应用成本的关键技术。