LIMI: Less is More for Agency
-
ArXiv URL: http://arxiv.org/abs/2509.17567v1
-
作者: Xiaojie Cai; Liming Liu; Jie Sun; Mohan Jiang; Jifan Lin; Wenjie Li; Dequan Wang; Jinlong Hou; Shijie Xia; Yang Xiao; 等17人
-
发布机构: GAIR; PolyU; SII; Shanghai Jiao Tong University; USTC
TL;DR
本文提出 LIMI 方法,证明通过极少量(仅78个)精心策划的高质量训练样本,即可训练出在智能体任务上超越使用海量数据训练的模型的强大AI智能体,从而确立了智能体开发的“少即是多”原则。
关键定义
本文提出或沿用了以下对理解其核心贡献至关重要的概念:
-
智能体能力 (Agency):本文将其定义为AI系统作为自主智能体运作的涌现能力——通过与环境和工具的自我导向互动,主动发现问题、形成假设并执行解决方案。这标志着AI从被动助手向主动智能体的范式转变。
-
查询 (Query, $q_i$):指用户发起的、用自然语言描述任务目标的初始指令。它是整个智能体交互流程的起点,为后续的协作过程设定了目标和成功标准。
-
轨迹 (Trajectory, $\tau_i$):指响应查询$q_i$而产生的完整、多轮的交互序列,形式化为 $\tau_i={a_{i,1},\ldots,a_{i,n_i}}$。它包含了模型思考过程 ($m_{i,j}$)、工具调用 ($t_{i,j}$) 以及环境反馈 ($o_{i,j}$) 等所有步骤,完整地记录了从任务理解到成功解决的整个协作工作流。
-
智能体效率原则 (Agency Efficiency Principle):本文通过实验得出的核心结论,即机器的自主性并非源于海量数据,而是源于对高质量智能体行为范例的策略性提炼。
相关工作
当前,智能体语言模型 (Agentic Language Model) 的研究已从早期的 Toolformer、ReAct 等方法,发展到GLM-4.5、Kimi-K2等专为智能体能力设计的先进基础模型。这些模型展现了强大的推理、编码和工具调用能力。
然而,目前的主流方法普遍遵循传统的规模法则 (Scaling Laws),即假设“更多数据等于更强的智能体能力”。这导致了越来越复杂、资源消耗巨大的训练流程。尽管LIMA和LIMO等研究在模型对齐和数学推理领域证明了小规模、高质量数据的有效性,但这一“少即是多”的理念在更复杂的智能体领域尚未得到验证。
本文旨在解决的核心问题是:能否通过更高效的方式(而非依赖大规模数据)来培养AI的智能体能力? 作者挑战了当前智能体开发中对数据规模的普遍依赖,探索策略性数据提炼是否比数据量本身更重要。
本文方法
本文的核心方法论 LIMI (Less is More for Intelligent Agency) 证明,通过聚焦于能体现复杂智能体行为的少量高质量范例,可以高效地培养出强大的智能体能力。其创新主要体现在以下几个方面:
创新点
-
新颖的智能体用户查询合成方法:为确保训练数据的真实性和代表性,本文设计了一套双轨制的查询(Query)收集策略。一方面,通过人机协作收集来自专业开发者和研究人员的真实世界任务查询;另一方面,利用先进的LLM(GPT-5)系统性地从高质量的GitHub拉取请求(Pull Requests)中合成查询,确保了训练任务既贴近现实,又具有足够的多样性。
-
系统化的轨迹收集协议:针对每个精选的查询,本文开发了一套严格的轨迹(Trajectory)收集流程。该流程在支持复杂工具交互的\(SII CLI\)环境中进行,由人类专家与AI智能体(GPT-5)协作完成任务。整个过程从任务理解、模型推理、工具使用、环境反馈直到任务成功解决,其完整的、多轮的交互序列都被记录下来,形成了高质量的智能体行为范例。
-
揭示智能体开发的效率原则:本文通过实验证明,智能体能力的涌现遵循“少即是多”的原则。其关键在于数据的“质”而非“量”。通过策略性地专注于两个核心知识工作领域——协同编码 (Vibe Coding) 和 研究工作流 (Research Workflows)——本文证明了极少量(仅78个)但包含了复杂协作、规划和执行过程的演示,足以培养出超越大规模数据训练的智能体。
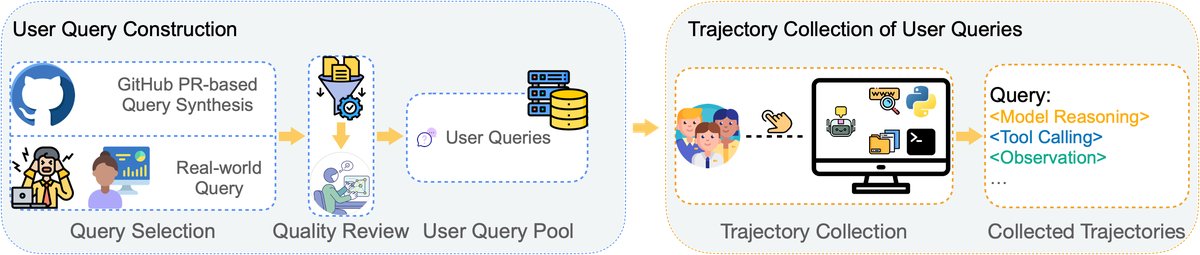
数据集构建流程
LIMI 方法的基石是其战略性的数据集构建过程,旨在以最少的数据捕捉智能体行为的精髓。
查询池构建
本文首先构建了一个包含78个高质量查询的查询池 $\mathcal{Q}={q_1, q_2, \ldots, q_{78}}$。这些查询来自两个渠道:
- 真实世界查询收集:收集了60个来自开发者和研究人员日常工作中的真实任务,确保了任务的复杂性和生态有效性。
- GitHub PR合成:为扩大覆盖面,本文设计了一个流程,从顶级GitHub项目(超过1万星标)的PR中,使用GPT-5合成新的查询。通过多阶段筛选(仓库筛选、PR筛选、专家标注审核),确保了合成查询的真实性和高质量。最终,从中挑选了18个最符合协同编码和研究工作流定义的查询。
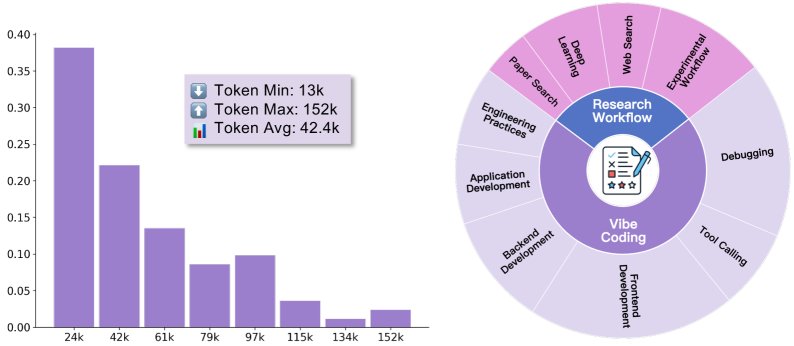
如图所示,这些数据覆盖了协同编码和研究工作流两大领域,并且轨迹长度分布广泛(平均42.4k Token),体现了任务的复杂性。
训练轨迹收集
在构建好查询池后,作者在\(SII CLI\)环境中进行轨迹数据收集。该环境集成了丰富的开发和研究工具,支持复杂的人机协作。 收集过程由四名计算机科学博士生担任“人类协作者”,与GPT-5模型共同解决这78个任务。他们持续迭代,直到任务成功完成,并记录下完整的交互轨迹 $\tau_i$。这些轨迹包含了模型思考、工具调用、环境观察和人类反馈的全部细节,为模型提供了学习复杂问题解决策略的完美范例。最长的轨迹达到了152k Token,表明了其所捕捉的协作过程的深度。
实验结论
实验围绕\(AgencyBench\)和一系列通用基准展开,旨在验证LIMI方法的有效性、数据效率和泛化能力。

核心结果
1. 在AgencyBench上性能卓越: 如下表所示,仅用78个样本训练的LIMI模型在AgencyBench上取得了73.5%的平均分,显著超过所有基线模型,如GLM-4.5(45.1%)、Kimi-K2-Instruct(24.1%)和Qwen3-235B-A22B-Instruct(27.5%)。这证明了LIMI方法的有效性,确立了新的SOTA。
| 模型分组 | 模型 | FTFC (%) | SCR (%) | RR (%) | 平均 (%) | 样本数 | 数据集 |
|---|---|---|---|---|---|---|---|
| 基线 SOTA 模型 | Kimi-K2-Instruct | 20.3 | 28.0 | 24.1 | 24.1 | N/A | 专有 |
| DeepSeek-V3.1 | 10.9 | 12.8 | 12.0 | 11.9 | N/A | 专有 | |
| Qwen3-235B… | 28.5 | 24.3 | 29.8 | 27.5 | N/A | 专有 | |
| GLM-4.5 | 37.8 | 47.4 | 50.0 | 45.1 | N/A | 专有 | |
| 数据效率对比 | GLM-4.5-CC | 46.1 | 42.6 | 45.2 | 44.6 | 260 | CC-Bench |
| GLM-4.5-Web | 47.8 | 45.7 | 45.6 | 46.4 | 7,610 | AFM-WebAgent | |
| GLM-4.5-Code | 49.3 | 47.4 | 46.8 | 47.8 | 10,000 | AFM-CodeAgent | |
| 本文方法 | LIMI (GLM-4.5) | 71.7 | 74.6 | 74.3 | 73.5 | 78 | LIMI (本文) |
| 模型规模泛化 | GLM-4.5-Air | 11.8 | 19.4 | 19.8 | 17.0 | N/A | 专有 |
| LIMI-Air (GLM-4.5-Air) | 30.4 | 36.8 | 35.7 | 34.3 | 78 | LIMI (本文) |
2. 惊人的数据效率: LIMI最引人注目的结论是其极高的数据效率。与在包含10,000个样本的\(AFM-CodeAgent\)数据集上训练的\(GLM-4.5-Code\)(47.8%)相比,使用128倍更少数据的LIMI(73.5%)实现了53.7%的巨大性能提升。这有力地证明了“少即是多”的核心假设:精心策划的高质量数据远比大规模、低密度的数据更有效。
3. 广泛的泛化能力: 在工具使用(tau2-bench)、代码生成(EvalPlus)和科学计算(SciCode)等多个通用基准测试中,LIMI同样表现出色,平均性能(57.2%)超越了所有基线模型。这表明LIMI学到的不仅是特定任务的解法,更是通用的推理、规划和工具使用能力。
| 模型 | TAU2-Air | TAU2-Ret | HE | MP | DS-1000 | SP | 平均 |
|---|---|---|---|---|---|---|---|
| Kimi-K2-Instruct | 20.3 | 44.0 | 88.4 | 76.5 | 32.2 | 2.5 | 37.3 |
| DeepSeek-V3.1 | 22.0 | 33.3 | 88.4 | 77.3 | 20.4 | 0.0 | 29.7 |
| Qwen3-235B… | 30.5 | 40.5 | 87.8 | 79.5 | 31.8 | 0.0 | 36.7 |
| GLM-4.5 | 32.5 | 38.0 | 89.0 | 81.1 | 37.5 | 0.0 | 43.0 |
| LIMI | 34.0 | 45.6 | 92.1 | 82.3 | 45.6 | 3.8 | 57.2 |
4. 执行环境的影响: 通过在有/无\(SII CLI\)工具环境的情况下进行对比评估,实验发现:
- 即使没有工具环境,LIMI(50.0%)的性能依然优于基线模型GLM-4.5(48.7%),证明了其训练方法提升了模型内在的核心能力。
- 当提供\(SII CLI\)工具环境时,LIMI的性能从50.0%提升到57.2%,显示出模型能有效利用工具来充分发挥其智能体潜力。这验证了内在能力提升与环境赋能之间的协同效应。
总结
本文的研究结果确立了智能体效率原则:AI智能体的自主能力并非来自数据量的堆积,而是来自对高质量、能体现复杂协作过程的范例的策略性提炼。LIMI方法通过仅78个精心设计的样本,就实现了超越使用数千甚至上万样本训练的SOTA模型的性能。这一发现从根本上挑战了智能体AI开发中普遍存在的规模依赖范式,为未来开发更高效、更强大的自主AI系统指明了一条新的、更可持续的道路。