LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
-
ArXiv URL: http://arxiv.org/abs/2403.07974v2
-
作者: Wen-Ding Li; Ion Stoica; King Han; Fanjia Yan; Armando Solar-Lezama; Sida Wang; Tianjun Zhang; Naman Jain; Alex Gu; Koushik Sen
-
发布机构: Cornell; MIT; University of California, Berkeley
TL;DR
本文提出了 LiveCodeBench,一个通过持续从编程竞赛平台收集新问题来避免数据污染,并从代码生成、自我修复、代码执行、测试输出预测等多个维度来全面评估大型语言模型(LLM)代码能力的动态基准。
关键定义
本文的核心是围绕一个新的基准测试 \(LiveCodeBench\) 及其评估场景展开的。以下是关键定义:
- LiveCodeBench: 一个为代码能力评估设计的新基准。其核心特性是“实时性” (Live),即不断从 LeetCode、AtCoder 和 CodeForces 等竞赛平台收集新发布的题目,并为每道题标记发布日期。这使得可以通过只在模型训练截止日期之后发布的问题上进行评估,从而有效避免数据污染 (data contamination)。
- 自我修复 (Self-Repair): 一项评估模型调试能力的场景。模型在收到问题描述、一份有错误的代码、导致失败的测试用例以及相应的执行反馈后,需要输出一份修复后的正确代码。
- 代码执行 (Code Execution): 一项评估模型代码理解能力的场景。模型需在给定一段代码和一个输入的情况下,预测该代码在该输入下的确切输出结果,类似于“人肉编译器”。
- 测试输出预测 (Test Output Prediction): 本文引入的一项新任务,旨在评估模型对问题描述的理解和推理能力。模型在只收到问题描述和一个测试输入的情况下,需要直接生成该输入对应的正确输出,而无需生成完整的解题代码。
相关工作
当前,评估大语言模型代码能力的主流基准包括 HumanEval、MBPP 和 APPS 等。然而,这些基准存在两大关键瓶颈:
- 数据污染与过拟合风险: 这些静态基准的问题集是固定的,很可能已被包含在现代 LLM 的大规模训练数据中。这导致评估结果虚高,无法真实反映模型在未见过问题上的泛化能力。虽然有去污方法,但很难做到彻底。
- 评估维度单一: 它们几乎只关注“自然语言到代码”的生成任务,忽略了真实软件开发中同样重要的其他能力,如调试、代码理解、测试用例设计等。这使得评估不够全面,可能产生误导性的结论。
本文提出的 LiveCodeBench 旨在通过动态更新和多维度评估,直接解决上述数据污染和评估片面性的问题。
本文方法
LiveCodeBench 的设计和构建基于四大原则,旨在创建一个更可靠、全面的代码能力评估框架。
构建原则
-
实时更新以防止污染: 这是 LiveCodeBench 的核心创新。通过持续从 LeetCode、AtCoder 等竞赛平台爬取每周发布的新题目,并标记其发布日期,可以为任何模型创建一个“无污染”的测试集。评估时,只需筛选出在该模型训练数据截止日期之后发布的题目即可,从而保证了评估的公平性和有效性。
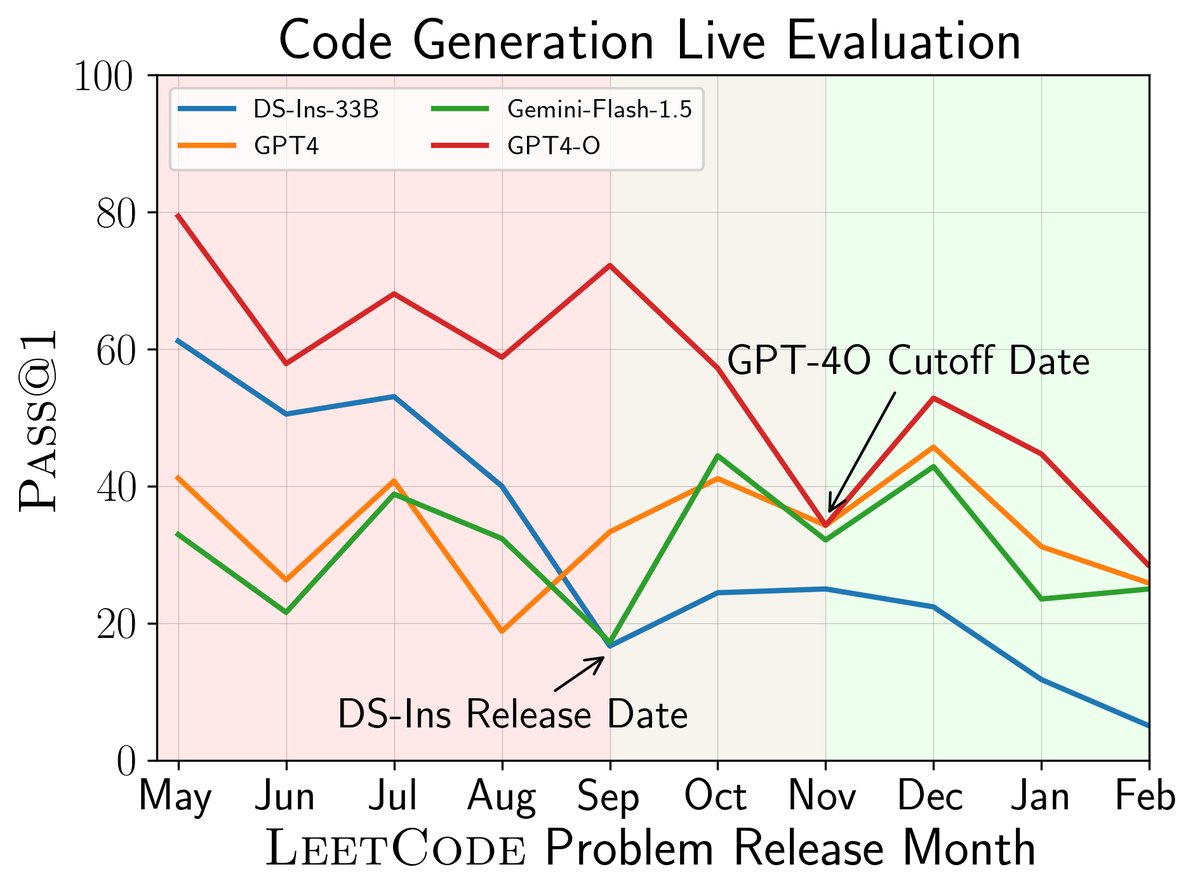 图1(左):代码生成任务中,DeepSeek-Instruct 和 GPT-4-O 在其截止日期(2023年9月和11月)之后发布的问题上表现明显下降,表明早期问题存在污染。
图1(左):代码生成任务中,DeepSeek-Instruct 和 GPT-4-O 在其截止日期(2023年9月和11月)之后发布的问题上表现明显下降,表明早期问题存在污染。 - 全面评估 (Holistic Evaluation): 除了传统的代码生成,LiveCodeBench 还额外引入了三个评估场景,以考察模型更广泛的代码相关能力:
- 自我修复:评估调试能力。
- 代码执行:评估代码理解能力。
- 测试输出预测:评估问题理解和推理能力。
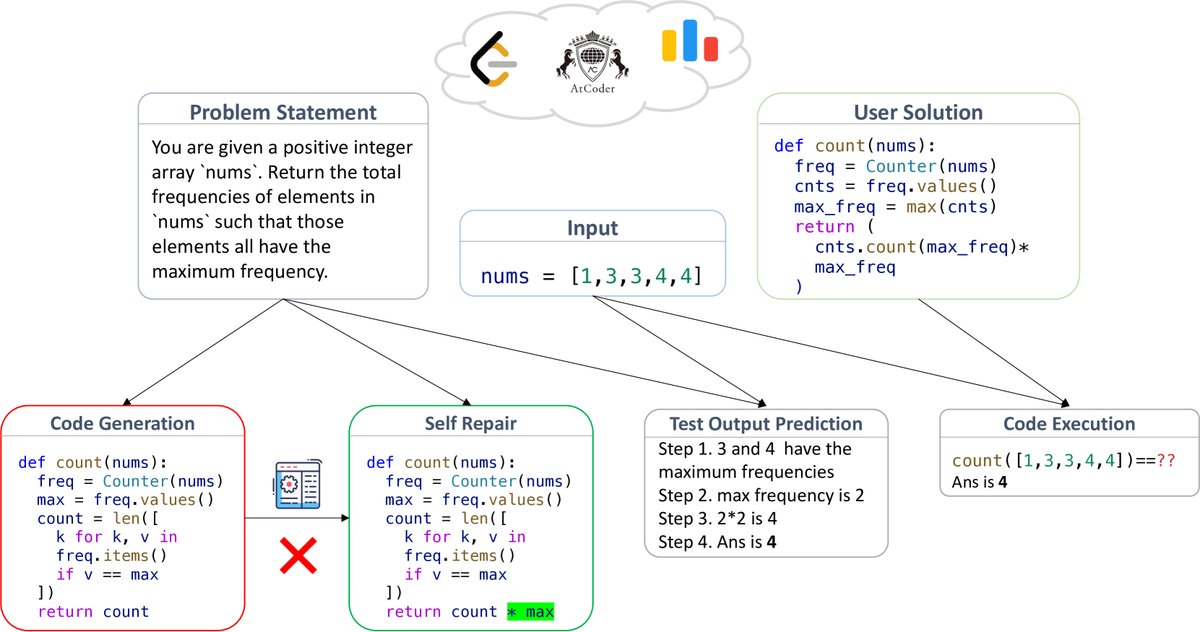 图3:LiveCodeBench 的四个评估场景概览
图3:LiveCodeBench 的四个评估场景概览这种多维度的评估能够更全面地揭示不同模型之间的能力差异。
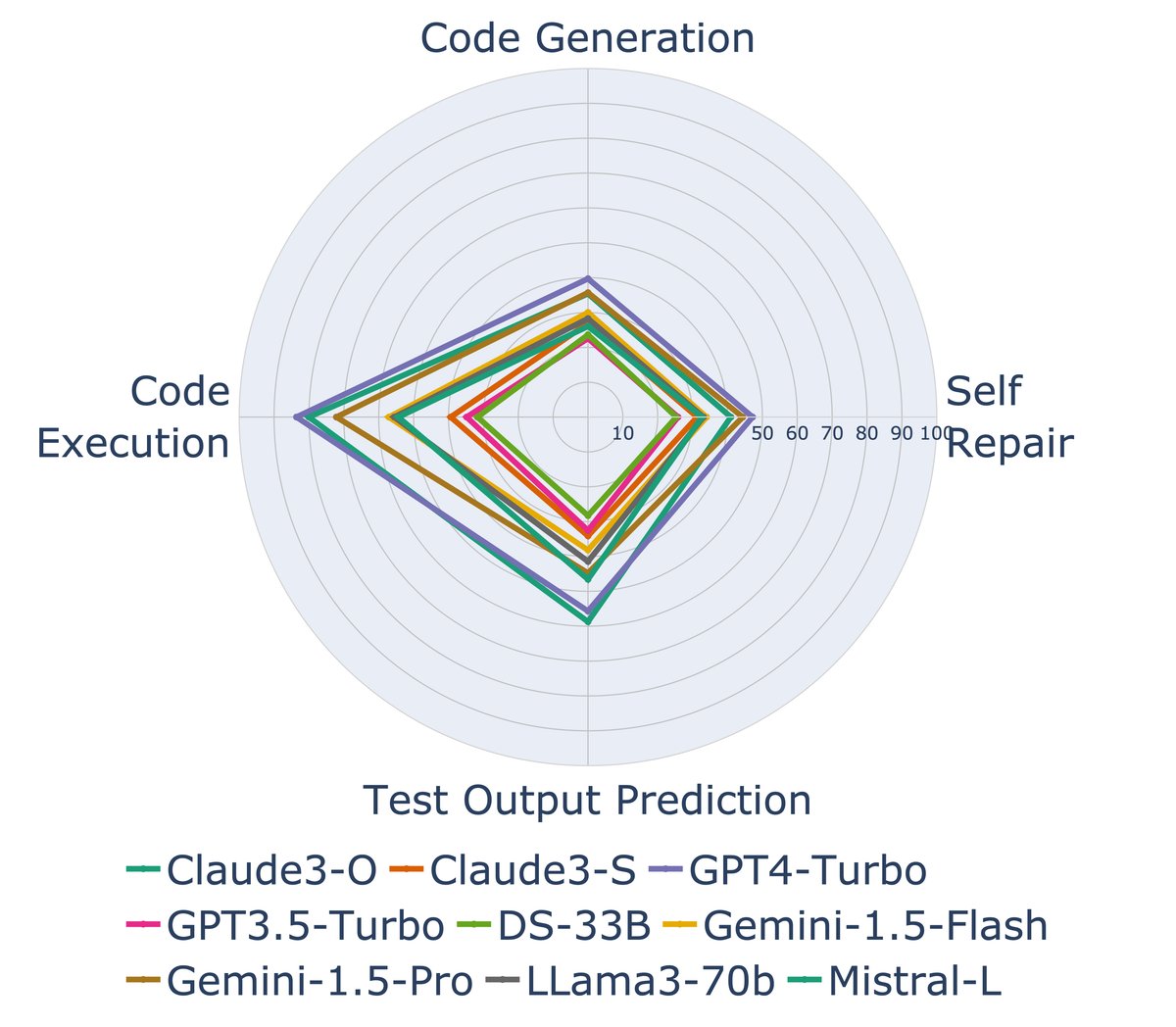 图2(左):不同模型在四个场景下的性能雷达图,显示了模型相对优势在不同任务间会发生变化。
图2(左):不同模型在四个场景下的性能雷达图,显示了模型相对优势在不同任务间会发生变化。 -
高质量的问题与测试: 问题来源于世界知名的编程竞赛平台,其质量、清晰度和正确性已经过数千名参赛者的验证。此外,每个问题平均配备约 17 个测试用例,确保了评估的鲁棒性。
- 均衡的问题难度: 许多竞赛题目对现有 LLM 来说过难,导致得分区分度低。LiveCodeBench 利用平台提供的问题难度等级,筛选掉极难的题目,并将问题分为“简单”、“中等”和“困难”三个级别,从而可以进行更细粒度的模型比较。
基准构建与数据统计
本文从 LeetCode、AtCoder 和 CodeForces 三个平台收集了从2023年5月到2024年5月的511个问题。测试用例一部分直接从平台获取,另一部分通过本文设计的基于生成器的测试生成方法(使用 GPT-4-Turbo)构建。
| 平台/子集 | 总数 | #简单 | #中等 | #困难 | 平均测试数 |
|---|---|---|---|---|---|
| LCB (截至5月底) | 511 | 182 | 206 | 123 | 17.0 |
| LCB (截至9月底) | 349 | 125 | 136 | 88 | 18.0 |
| AtCoder | 267 | 99 | 91 | 77 | 15.6 |
| LeetCode | 235 | 79 | 113 | 43 | 19.0 |
| CodeForces | 9 | 4 | 2 | 3 | 11.1 |
| LCB-Easy | 182 | 182 | 0 | 0 | 16.1 |
| LCB-Medium | 206 | 0 | 206 | 0 | 17.4 |
| LCB-Hard | 123 | 0 | 0 | 123 | 18.0 |
表1: LiveCodeBench 中收集的问题统计数据。
根据不同的任务场景,这些原始数据被构造成相应的评测实例。例如,对于代码执行任务,本文从 LeetCode 收集了约2000个人类提交的正确解法,并经过筛选,最终构成了包含479个样本的数据集。
实验结论
本文对18个基础模型和34个指令微调模型进行了全面评估,得出了几个在以往基准中未能揭示的重要发现。所有比较均在剔除可能受污染的数据后进行(即使用2023年9月之后的问题)。
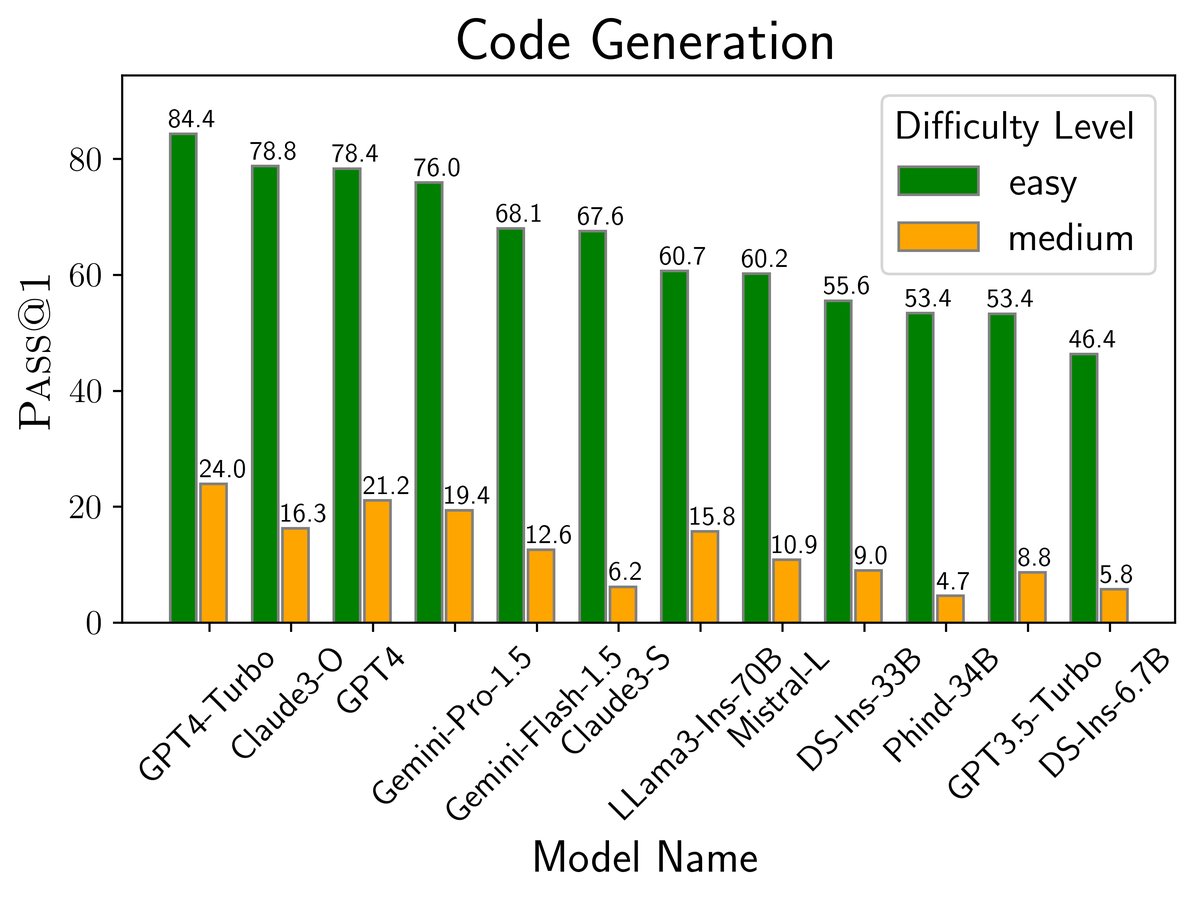 图4: 不同模型在 LiveCodeBench 四个场景下的性能表现 (Pass@1)。
图4: 不同模型在 LiveCodeBench 四个场景下的性能表现 (Pass@1)。
-
成功检测并规避了数据污染: 通过按月分析性能,实验明确显示 DeepSeek 和 GPT-4-O 模型在 LeetCode 题目上的表现,在其各自训练数据截止日期(分别为2023年8月和11月)后出现断崖式下跌。这证实了数据污染的普遍性,并凸显了 LiveCodeBench 时间分段评估方法的有效性。
- 全面评估揭示模型能力差异:
- 虽然模型在不同任务上的表现高度相关(相关系数>0.88),但相对优势各不相同。例如,Claude-3-Opus 在“测试输出预测”任务上甚至超越了 GPT-4-Turbo,而其代码生成能力则稍逊一筹。这证明了多维度评估的必要性。
- 闭源模型在自我修复和测试输出预测等更复杂的任务上,相较于开源模型的优势进一步扩大。
- 揭示 HumanEval 基准的过拟合现象:
- 将 LiveCodeBench 与 HumanEval+ 的性能进行对比发现,模型明显分为两类:一类在两个基准上表现一致(主要是基础模型和闭源模型);另一类在 HumanEval+ 上表现优异,但在 LiveCodeBench 上表现平平(主要是开源微调模型)。
- 这表明许多开源模型可能针对 HumanEval 进行了过拟合,其高分无法泛化到 LiveCodeBench 中更具挑战性和多样性的问题上。
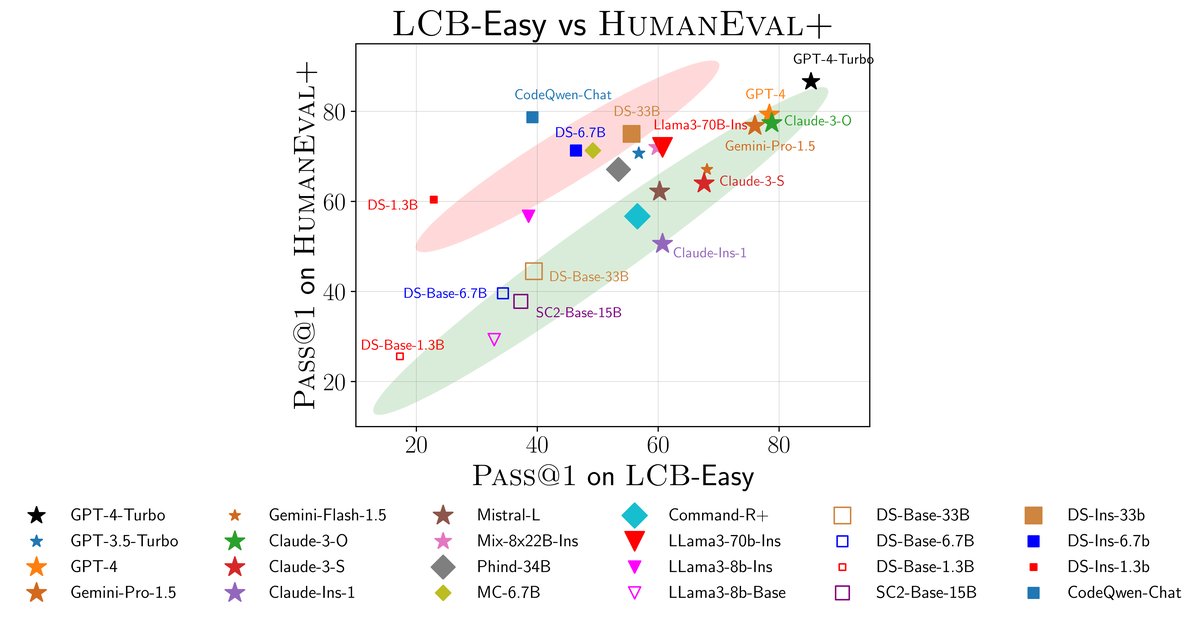 图5: 模型在 HumanEval+ 和 LiveCodeBench-Easy 上的性能散点图。红色区域的模型可能对 HumanEval+ 存在过拟合。
图5: 模型在 HumanEval+ 和 LiveCodeBench-Easy 上的性能散点图。红色区域的模型可能对 HumanEval+ 存在过拟合。 - 模型对比的清晰洞察:
- 顶尖模型与开源模型的差距: LiveCodeBench 清楚地揭示了 GPT-4 系列、Claude-3-Opus 等顶尖闭源模型与现有开源模型之间的巨大性能鸿沟,这个差距在 HumanEval 等旧基准上并不明显。
- 基础模型对比: 在开源基础模型中,LLaMa-3-Base 和 DeepSeek-Base 系列显著优于 CodeLLaMa-Base 和 StarCoder2-Base 系列。
- 后训练的重要性与风险: 指令微调等后训练技术能显著提升模型性能,但如果微调数据不够多样化,则容易导致模型在旧基准上过拟合,而无法应对新挑战。