LiveThinking: Enabling Real-Time Efficient Reasoning for AI-Powered Livestreaming via Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.07685v1
-
作者: Wanqing Cui; Yuhan Sun; Meiguang Jin; Zhiwei Huang; Shaopan Xiong
-
发布机构: Alibaba
TL;DR
本文提出了一种名为 LiveThinking 的两阶段优化框架,旨在解决AI直播等实时场景中推理质量与延迟之间的权衡问题。该框架首先通过知识蒸馏将大型推理模型的能力压缩到轻量级模型中,然后利用强化学习进一步优化推理路径的效率,最终实现了在大幅降低延迟和计算成本的同时,提升响应的正确性与帮助性。
关键定义
本文沿用了现有概念,并提出了两个关键的评估指标用于模型优化:
- 正确性 (Correctness, C): 用于衡量模型响应在事實層面是否與提供的产品知识对齐。一个正确的响应,其所有声明都必须能在提供的文档 \(D_t\) 中得到验证,与对话历史 \(H_t\) 保持逻辑一致,并且直接回答当前的用户问题 \(Q_t\)。
- 帮助性 (Helpfulness, H): 用于评估模型响应是否能为用户提供超越基础回答的额外价值。一个有帮助的响应,除了正确回答问题外,还应能预判用户的潜在需求,并根据对话上下文 \(H_t\) 主动提供补充性的相关信息。
- LLM Judge: 本文使用一个大型语言模型作为裁判,根据上述定义的正确性(Correctness)和帮助性(Helpfulness)标准来自动评估和筛选模型生成的响应。该裁判在第一阶段的拒绝采样微调中用于数据过滤,在第二阶段的强化学习中用于生成奖励信号。
相关工作
当前,大型推理模型 (Large Reasoning Models, LRM) 在复杂推理任务上表现出色,能够生成准确且细致的响应。然而,其巨大的参数规模和冗长的推理路径导致了极高的推理延迟,这在需要即时反馈的AI直播等交互式场景中是不可接受的。
现有研究尝试通过强化学习(Reinforcement Learning, RL)来优化语言模型,但常常面临模型产生冗长、计算成本高昂的思维链(Chain-of-Thought, CoT)的“过度思考” (overthinking) 现象。虽然一些工作尝试在奖励函数中加入长度惩罚来鼓励简洁性,但如何系统性地在保证响应质量(如正确性和帮助性)的同时,高效地压缩推理过程,仍然是一个关键瓶颈。
本文旨在解决LRM在部署于实时交互应用时,响应质量与低延迟要求之間的尖锐矛盾。
本文方法
本文提出了一个名为 LiveThinking 的两阶段优化框架,以在保证响应质量的同时,实现高效的实时推理。该框架首先通过知识蒸馏来传递能力,然后通过强化学习来优化效率。
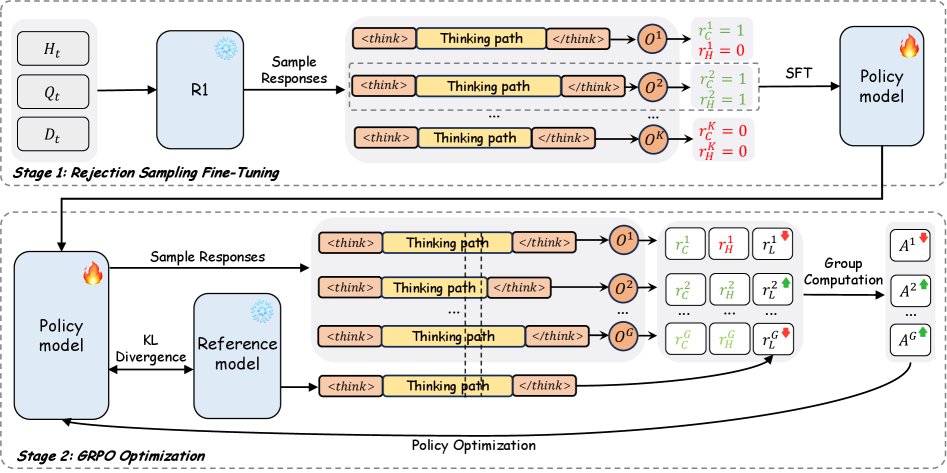
第一阶段:基于拒绝采样微调 (RFT) 的知识蒸馏
此阶段的目标是将一个大型教师模型(670B MoE)的推理能力迁移到一个轻量级的学生模型(30B MoE,3B激活)上。
-
教师数据生成: 使用教师模型 $P_{\theta_{\text{teacher}}}$ 为每个无标签的电商领域数据 $(D_t, Q_t, H_t)$ 生成 $k$ 个候选的推理轨迹和响应 $(T_t, R_t)$。
-
LLM Judge 过滤: 引入一个LLM Judge,根据预定义的“正确性”和“帮助性”标准,对生成的所有候选轨迹进行评估。只有同时满足这两个标准的轨迹才会被保留,形成一个高质量的 distilled 数据集 $\mathcal{D}_{\text{distill}}$。
\[\mathcal{D}_{\text{distill}}\subseteq\bigcup_{i=1}^{N}\bigcup_{j=1}^{k}\left\{\tau^{(i,j)}\mid C(\tau^{(i,j)})=1\land H(\tau^{(i,j)})=1\right\}\] -
学生模型微调: 使用高质量数据集 $\mathcal{D}_{\text{distill}}$ 对学生MoE模型进行微调。其损失函数包含标准的监督微调损失 $\mathcal{L}_{\text{SFT}}$ 和一个用于平衡 Experten 负载的辅助损失 $\mathcal{L}_{\text{aux}}$。
\[\mathcal{L}_{\text{total}}=\mathcal{L}_{\text{SFT}}+\lambda_{\text{aux}}\cdot\mathcal{L}_{\text{aux}}\] \[\mathcal{L}_{\text{SFT}}=-\mathbb{E}_{(D,Q,H,T,R)\sim\mathcal{D}_{\text{distill}}}\left[\sum_{i=1}^{L_y}\log P_{\theta^{\text{student}}}\left(y_i\mid\mathbf{x},y_{<i}\right)\right]\]
第二阶段:基于强化学习 (GRPO) 的推理效率优化
第一阶段得到的学生模型虽然能力很强,但也继承了教师模型冗长的推理习惯。第二阶段使用强化学习来解决这个问题,显式地缩短推理路径。
1. 多目标奖励函数设计
为了在压缩推理路径的同时保持高质量输出,设计了一个包含三个部分的复合奖励函数:
-
长度奖励 ($r_{\mathrm{length}}$): 该奖励旨在将模型生成内容的长度 $L_{\mathrm{policy}}$ 控制在一个理想区间内。该区间由参考长度 $L_{\mathrm{ref}}$(RFT阶段模型的输出长度)和上下界系数 $\lambda_{\mathrm{upper}}, \lambda_{\mathrm{lower}}$ 决定。当输出长度超出此区间时,会产生惩罚。
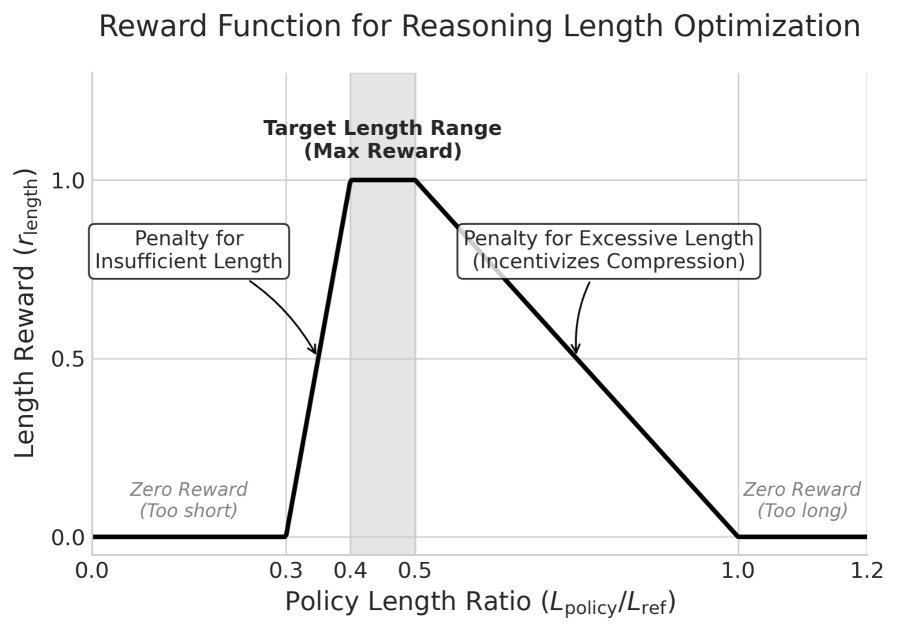
具体的计算公式如下:
\[L_{\mathrm{upper}} =\lambda_{\mathrm{upper}}L_{\mathrm{ref}},\quad L_{\mathrm{lower}}=\lambda_{\mathrm{lower}}L_{\mathrm{ref}}\] \[d =\begin{cases}\max(L_{\mathrm{lower}}-L_{\mathrm{policy}},0)&L_{\mathrm{policy}}<L_{\mathrm{lower},}\\ \max(L_{\mathrm{policy}}-L_{\mathrm{upper}},0)&L_{\mathrm{policy}}>L_{\mathrm{upper},}\\ 0&\text{otherwise,}\end{cases}\] \[r_{\mathrm{length}} =\max\left(0,1-\frac{d}{\epsilon}\right)\] -
正确性奖励 ($r_{\mathrm{correct}}$): 一个二元奖励,由LLM Judge判断响应是否符合事实,以减少幻觉。
\[r_{\mathrm{correct}}=C(D_t,Q_t,H_t,R_t)\in\{0,1\}\] -
帮助性奖励 ($r_{\mathrm{helpful}}$): 一个二元奖励,由LLM Judge判断响应是否提供了额外的有用信息,以防止模型变得过于保守。
\[r_{\mathrm{helpful}}=H(Q_t,H_t,R_t)\in\{0,1\}\]
2. Group Relative Policy Optimization (GRPO)
本文采用GRPO算法进行策略优化,因为它在处理复杂多目标奖励时比标准PPO更高效、更稳定。
-
组相对优势计算: 首先,将上述三个奖励加权求和,得到每个响应的复合奖励 $r_j$。然后,在一个批次(group)内,通过Z-score标准化计算每个响应的相对优势 $A_j$。
\[r_j =w_c r_j^{\mathrm{correct}}+w_h r_j^{\mathrm{helpful}}+w_l r_j^{\mathrm{length}}\] \[A_j =\frac{r_j-\mu}{\sigma+\epsilon_{\mathrm{std}}},\quad\text{where }\mu,\sigma=\text{mean, stddev}\left(\{r_i\}_{i=1}^{K}\right)\] -
策略优化: 使用计算出的优势 $A_j$ 来更新策略网络,其目标函数如下,其中包含了一个KL散度项以防止策略偏离过远。
\[\mathcal{L}^{\mathrm{GRPO}}(\theta)=\frac{1}{K}\sum_{j=1}^{K}\Bigg[ \min\left(\frac{\pi_\theta(a_j \mid s_j)}{\pi_{\theta_{\text{old}}}(a_j \mid s_j)}A_j, \text{clip}\left(\frac{\pi_\theta(a_j \mid s_j)}{\pi_{\theta_{\text{old}}}(a_j \mid s_j)},1-\eta,1+\eta\right)A_j\right) -\beta D_{\text{KL}}\left(\pi_{\theta_{\text{old}}}\ \mid \pi_\theta\right)\Bigg]\]
实验结论
实验结果表明,LiveThinking框架在工业级和公开 benchmarks 上均取得了显著成果。
主要结果
| 模型 | 数据集 | 正确率(%) | 帮助性(%) | EM | F1 | 每响应Token数(TPR) | 解码TFLOPs |
|---|---|---|---|---|---|---|---|
| Tblive-E-Commerce QA | |||||||
| DeepSeek-R1-670B (教师) | 89.0 | 75.0 | - | - | 341 | 1483.5 | |
| Qwen3-30B-A3B (基线) | 67.3 | 56.5 | - | - | 396 | 46.7 | |
| + RFT + RL (本文) | 92.3 | 96.8 | - | - | 152 | 47.4 | |
| MuSiQue | |||||||
| DeepSeek-R1-670B (教师) | - | - | 41.2 | 57.0 | 807 | 4519.2 | |
| Qwen3-30B-A3B (基线) | - | - | 13.0 | 36.3 | 755 | 118.0 | |
| + RFT + RL (本文) | - | - | 53.5 | 67.2 | 473 | 233.1 |
- 性能超越与效率提升: 在工业数据集 Tblive-E-Commerce QA 上,最终模型(Qwen3-30B-A3B + RFT + RL)的正确性和帮助性分别达到92.3%和96.8%,显著超过了670B的教师模型。同时,其解码计算成本降低了超过30倍,响应长度缩短了55%。
- 泛化能力: 在公开的多跳推理数据集 MuSiQue 上,本文方法同样超越了教师模型(EM +12.3, F1 +10.2),且响应长度缩短了41%,证明了该方法的泛化能力。
- 架构通用性: 该框架在8B的Llama稠密模型上也取得了巨大提升,证明了其方法不局限于特定的MoE架构。
消融研究
- 两阶段的互补性:
- 仅使用RFT(第一阶段)虽然能显著提升正确性(67.3%→81.3%)和帮助性(56.5%→77.0%),但模型继承了教师模型的冗长推理习惯,响应长度几乎没有减少。
- 仅使用RL(第二阶段)能同时提升质量和效率(正确率87.5%,帮助性90.0%,TPR 152)。
- RFT + RL 的组合取得了最佳效果(正确率92.3%,帮助性96.8%)。这表明,RFT为模型注入了高质量的推理能力先验知识,而RL在此基础上进行压缩和微调,两者相辅相成,实现了1+1>2的效果。
核心组件有效性
- RFT vs SFT: 与标准的监督微调(SFT)相比,使用RFT(Rejection Sampling Fine-Tuning)蒸馏的模型在正确性和帮助性上均表现更优,尤其在帮助性上提升了5.0%。这证明通过LLM Judge过滤掉低质量的教师输出,对于学习 nuanced、以用户为中心的推理模式至关重要。
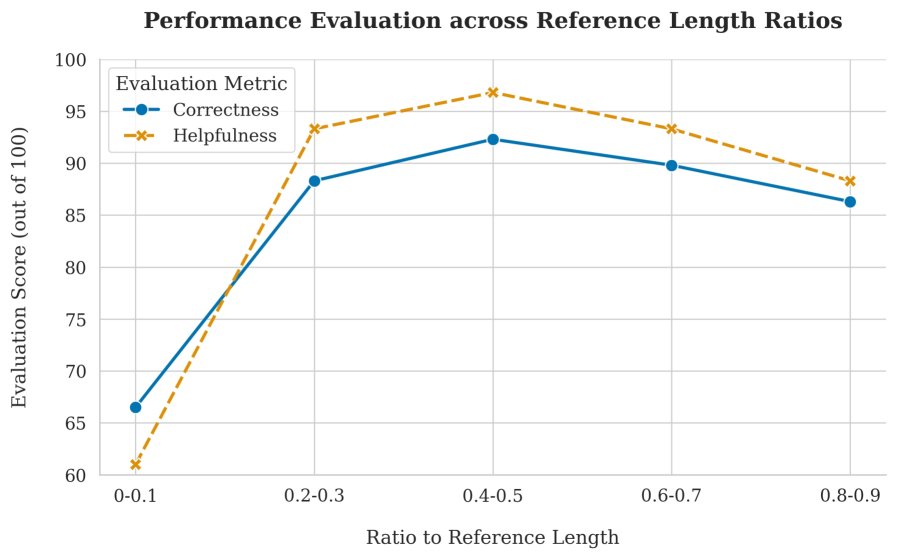
- 目标推理长度的影响: 实验表明,推理简洁性与响应质量之间存在权衡。过度追求 brevity(过强的长度惩罚)会导致模型性能下降。这凸显了在RL阶段精心设计和调整长度奖励函数的重要性。
最终,本文方法成功部署于淘宝直播的生产环境中,计算成本降低了30倍,同时带来了订单转化率和用户多轮对话 engagement 的显著增长,验证了其在真实、高流量工业场景中的有效性和商业价值。