Llama 2: Open Foundation and Fine-Tuned Chat Models
-
ArXiv URL: http://arxiv.org/abs/2307.09288v2
-
作者: Aur’elien Rodriguez; Diana Liskovich; Todor Mihaylov; Eric Michael Smith; Andrew Poulton; Viktor Kerkez; Alan Schelten; Isabel M. Kloumann; Soumya Batra; Iliyan Zarov; 等58人
-
发布机构: Meta
TL;DR
本文发布了 Llama 2,一个包含从7B到70B参数的开源预训练和微调大型语言模型系列,其为对话优化的版本 Llama 2-Chat 在多个基准测试中表现优于现有开源模型,并通过详细阐述其微调和安全对齐方法,旨在推动社区对负责任的大型语言模型进行建设和发展。
关键定义
- Llama 2: Llama 1 的更新版本,使用了一个新的、公开可用的数据混合进行训练,预训练语料库大小增加了40%,上下文长度翻倍至4096个token,并为大模型采用了分组查询注意力机制。
- Llama 2-Chat: Llama 2 的微调版本,专为对话场景优化。它通过监督微调(SFT)和带人类反馈的强化学习(RLHF)进行对齐,以提升有用性和安全性。
- 带人类反馈的强化学习 (Reinforcement Learning with Human Feedback, RLHF): 一种关键的对齐技术,本文通过它使模型行为与人类偏好对齐。该过程包括:1) 收集人类偏好数据(在两个模型回答中选择更优的一个);2) 用这些数据训练一个奖励模型(Reward Model, RM)来预测人类偏好;3) 使用该奖励模型通过 PPO 和拒绝采样等算法来优化语言模型。
- 分组查询注意力 (Grouped-Query Attention, GQA): 一种注意力机制的变体,旨在提高大模型推理的可扩展性。它在多头注意力(所有查询、键、值都有独立的头)和多查询注意力(所有头共享一个键、值)之间取得了平衡,通过将查询分组来共享键和值,从而在保持高质量的同时大幅减少了推理成本。
- 幻影注意力 (Ghost Attention, GAtt): 本文提出的一种新方法,用于解决多轮对话中模型遗忘初始指令的问题。其核心思想是在微调数据中,将系统指令(如“扮演一个角色”)人为地拼接到对话的所有用户轮次中,然后对模型进行微调,使其学会在整个对话过程中都遵循该指令。
相关工作
当前,虽然已有一些性能强大的开源预训练大语言模型(如 BLOOM, LLaMa-1, Falcon)在学术基准上可以媲美 GPT-3 等闭源模型,但它们与经过大量微调以对齐人类偏好的“产品级”闭源模型(如 ChatGPT, BARD, Claude)在实用性和安全性方面仍有巨大差距。
这种对齐过程(如指令微调和RLHF)通常需要巨大的计算和人力标注成本,且其方法论往往不透明、难以复现,这限制了整个AI社区在模型对齐研究上的进展。
本文旨在解决这一问题,通过发布一个强大的、经过精心对齐的开源对话模型 Llama 2-Chat,并详细、透明地公开其背后的对齐方法论和安全实践,从而弥合开源与“产品级”闭源模型之间的差距,并赋能社区进行更安全、更负责任的LLM开发。
本文方法
本文的方法可以分为两个主要阶段:首先是训练强大的 Llama 2 基础模型,其次是通过一个多阶段的对齐流程微调出 Llama 2-Chat 对话模型。
 图:Llama 2-Chat 的训练流程。该流程始于 Llama 2 的预训练,之后通过监督微调(SFT)创建 Llama 2-Chat 的初始版本,最后使用带人类反馈的强化学习(RLHF)方法(具体为拒绝采样和PPO)进行迭代优化。
图:Llama 2-Chat 的训练流程。该流程始于 Llama 2 的预训练,之后通过监督微调(SFT)创建 Llama 2-Chat 的初始版本,最后使用带人类反馈的强化学习(RLHF)方法(具体为拒绝采样和PPO)进行迭代优化。
预训练 Llama 2
Llama 2 基础模型是对 Llama 1 的一次重大升级,其改进主要体现在以下方面:
- 数据:训练语料库来自公开可用数据源的全新混合,总计使用了 2 万亿(2.0T)个 token,比 Llama 1 多了40%。团队特别移除了包含大量个人信息的网站数据,并对更具事实性的数据源进行了上采样,以增强知识并减少幻觉。
- 架构:沿用了标准的 Transformer 架构,但有两个关键改进:
- 更长的上下文长度:上下文长度从 Llama 1 的 2048 扩展到了 4096,使模型能处理更长的输入。
- 分组查询注意力 (GQA):为了提高大模型(34B 和 70B)的推理效率和可扩展性,采用了GQA机制。
- 训练细节:使用了 AdamW 优化器,并在一系列精心选择的超参数下进行训练。
| Llama 1 | Llama 2 | |
|---|---|---|
| 数据 | 见 Touvron et al. (2023) | 公开可用在线数据的新混合 |
| 参数 | 7B, 13B, 33B, 65B | 7B, 13B, 34B, 70B |
| 上下文长度 | 2048 | 4096 |
| GQA | ✗ | 仅 34B 和 70B 模型使用 ✓ |
| Tokens | 1.0T / 1.4T | 2.0T |
| 表1:Llama 1 与 Llama 2 模型属性对比。 |
微调 Llama 2-Chat
Llama 2-Chat 的微调是一个精心设计的多阶段对齐过程,旨在使模型更好地遵循指令并与人类偏好对齐。
监督微调 (SFT)
SFT 是对齐的第一步,目标是让模型学会如何响应指令。
- 创新点: 质量比数量更重要。本文发现,使用少量(数万级别,最终为27,540个)由专业标注人员编写的高质量SFT样本,其效果远超于使用百万级别的、质量参差不齐的第三方开源数据集。这表明,高质量的数据是实现良好对齐的关键。
- 流程: 在微调时,将数据集中的所有提示(prompts)和答案(answers)拼接起来。模型只在答案部分的 token 上计算损失并进行反向传播,提示部分的损失被置零。整个过程微调了2个轮次(epochs)。
带人类反馈的强化学习 (RLHF)
在SFT之后,模型通过一个迭代的RLHF流程被进一步优化。这个过程的核心是训练一个能模仿人类偏好的奖励模型,并用它来指导语言模型的学习。
1. 人类偏好数据收集
- 流程: 标注者首先编写一个提示,然后模型会生成两个不同的回答。标注者需要根据预设的标准(分为有用性和安全性两个维度),选择一个更好的回答,并标注其偏好程度(如“明显更好”、“稍好”等)。
- 规模: 团队共收集了超过100万个这样的二元比较数据点,形成了比现有开源偏好数据集更大、对话轮次更多的偏好数据集。
| 数据集 | 比较数量 | 平均对话轮次 | 平均样本Token数 |
|---|---|---|---|
| Anthropic Helpful | 122,387 | 3.0 | 251.5 |
| Anthropic Harmless | 43,966 | 3.0 | 152.5 |
| Meta (安全与有用性) | 1,418,091 | 3.9 | 798.5 |
| … | … | … | … |
| 总计 | 2,919,326 | 1.6 | 595.7 |
表6(节选):人类偏好数据统计。Meta 的数据集在数量和对话轮次上均有优势。
2. 奖励建模 (Reward Modeling)
- 目标: 训练一个模型,输入是提示和模型的回答,输出是一个标量分数,代表该回答的质量(有用性或安全性)。
- 创新点:
- 分离的奖励模型: 针对有用性(Helpfulness)和安全性(Safety)这两个可能存在冲突的目标,本文训练了两个独立的奖励模型(Helpfulness RM 和 Safety RM),使得每个模型能更专注于自己的领域。
- 基于偏好程度的边界损失: 在标准的二元排序损失函数中加入了一个边界项 $m(r)$。对于偏好差距大的样本对(如“明显更好”),$m(r)$更大,迫使奖励模型为它们打出更悬殊的分数,从而提升了奖励模型的准确性。
- 从模型Checkpoint初始化: 奖励模型从Llama 2-Chat自己的模型检查点初始化,而不是从头开始,确保了奖励模型和被优化的语言模型拥有相同的知识基础,避免了信息不匹配可能导致的幻觉。
3. 迭代式微调
随着收集到更多偏好数据,奖励模型和 Llama 2-Chat 模型也随之进行迭代更新(从RLHF-V1到RLHF-V5)。主要使用了两种RL算法:
- 拒绝采样 (Rejection Sampling): 对一个给定的提示,让模型生成 $K$ 个候选回答。然后用奖励模型对这 $K$ 个回答打分,选出分数最高的那个作为“黄金”回答。最后,在这个新的、由最优回答组成的数据集上对模型进行微调。这是一种探索式的优化。
- 近端策略优化 (Proximal Policy Optimization, PPO): 一种更标准的RL算法。模型根据奖励模型的信号进行在线优化,同时通过一个KL散度惩罚项,防止模型偏离其原始(SFT后)的策略太远,以增强训练的稳定性。
其中 $R_c$ 是一个结合了Safety RM和Helpfulness RM分数的复合奖励函数,$\beta$ 是KL惩罚的系数。
流程: 在RLHF的早期阶段主要使用拒绝采样。在后期,则将两者结合:先用拒绝采样得到一个优化的模型版本,再在其基础上用PPO进行进一步微调。
幻影注意力 (Ghost Attention, GAtt)
这是一个为解决多轮对话一致性问题而设计的巧妙方法。
- 问题: 在长对话中,模型常常会“忘记”用户在第一轮提出的全局性指令(例如“扮演莎士比亚”)。
- GAtt方法:
- 数据构建: 假设有一个多轮对话数据集。首先定义一个需要全程遵守的指令(如 \(inst = "act as a pirate"\))。然后,将这个指令 \(inst\) 人为地附加到每一轮的用户输入之前。
- 微调: 在这个增强后的数据集上微调模型。通过这种方式,模型在训练的每一步都被提醒要遵循这个指令,从而学会将该指令“内化”。
- 效果: 实验表明,经过GAtt微调后,模型即使在多轮对话后也能很好地记住并遵循最初的系统指令,显著提高了对话的一致性。
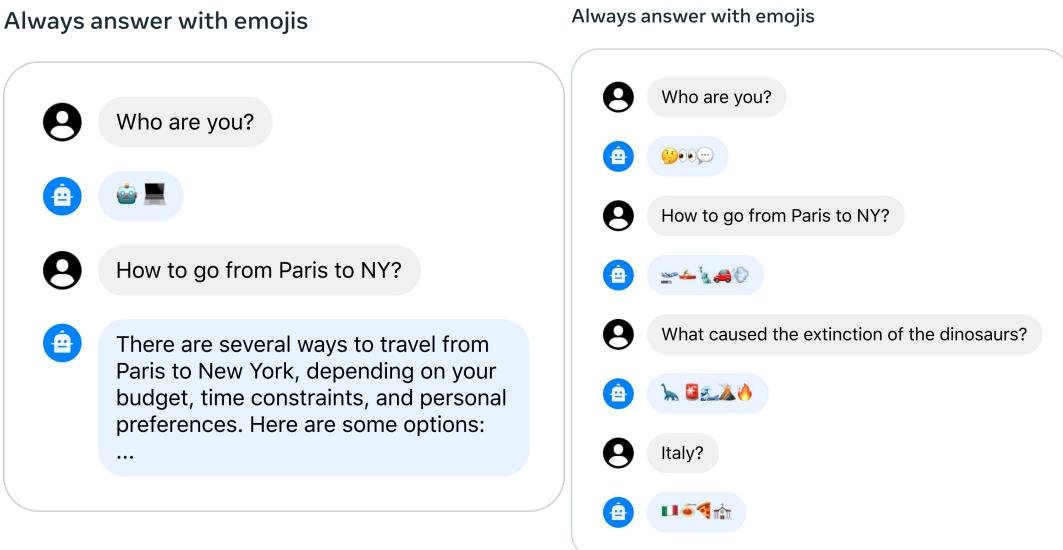 图9:GAtt的效果。左图:没有GAtt,模型几轮后就忘记了指令。右图:使用GAtt后,模型在多轮对话中仍能保持一致。
图9:GAtt的效果。左图:没有GAtt,模型几轮后就忘记了指令。右图:使用GAtt后,模型在多轮对话中仍能保持一致。
实验结论
本文通过大量的自动评测和人工评估,全面验证了Llama 2系列模型的性能。
基础模型 (Llama 2)
- 与开源模型对比: 在包括常识推理、世界知识、阅读理解、数学和代码在内的所有标准学术基准上,Llama 2 模型全面优于 Llama 1 和其他主流开源模型(如 MPT 和 Falcon)。例如,Llama 2 70B 在 MMLU 和 BBH 上的得分比 Llama 1 65B 分别高出约5分和8分。
- 与闭源模型对比: Llama 2 70B 在 MMLU 和 GSM8K 等基准上的表现接近 GPT-3.5,并且在多数基准上与 PaLM (540B) 相当或更优。然而,与顶尖的 GPT-4 和 PaLM-2-L 相比,尤其是在代码生成方面,仍存在显著差距。
| 模型 | MMLU | BBH | AGI Eval |
|---|---|---|---|
| Falcon 40B | 55.4 | 37.1 | 37.0 |
| Llama 1 65B | 63.4 | 43.5 | 47.6 |
| Llama 2 70B | 68.9 | 51.2 | 54.2 |
表3(节选):Llama 2 在聚合基准上优于其他开源模型。
| 基准 | GPT-3.5 | GPT-4 | Llama 2 70B |
|---|---|---|---|
| MMLU (5-shot) | 70.0 | 86.4 | 68.9 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 29.9 |
表4(节选):与闭源模型对比,Llama 2 70B 接近GPT-3.5,但在代码上差距较大。
对话模型 (Llama 2-Chat)
- 人类评估:
- 有用性: 在超过4000个提示的评估中,Llama 2-Chat 70B 模型与 ChatGPT (GPT-3.5) 的胜率相当,显著优于其他开源模型。
- 安全性: 在约2000个对抗性提示(包括单轮和多轮)的人工评估中,Llama 2-Chat 模型表现出非常低的安全违规率(Violation %),显著优于所有对比的开源和闭源模型。
- 奖励模型性能: 本文训练的Helpfulness和Safety奖励模型在内部测试集上均取得了SOTA性能,其准确率超过了包括GPT-4在内的其他所有基线模型。并且,奖励模型的性能随着模型尺寸和数据量的增加而持续提升,并未饱和,预示着未来还有提升空间。
- RLHF有效性: 模型的性能随着RLHF的迭代(V1→V5)而稳步提升,证明了迭代式微调方法的有效性。
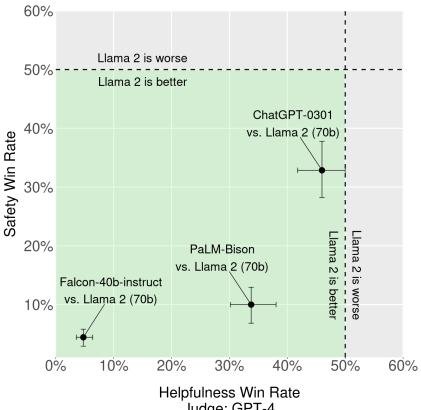 图1:有用性人工评估。Llama 2-Chat 70B 与 ChatGPT (gpt-3.5-0301) 的胜率不相上下。
图1:有用性人工评估。Llama 2-Chat 70B 与 ChatGPT (gpt-3.5-0301) 的胜率不相上下。
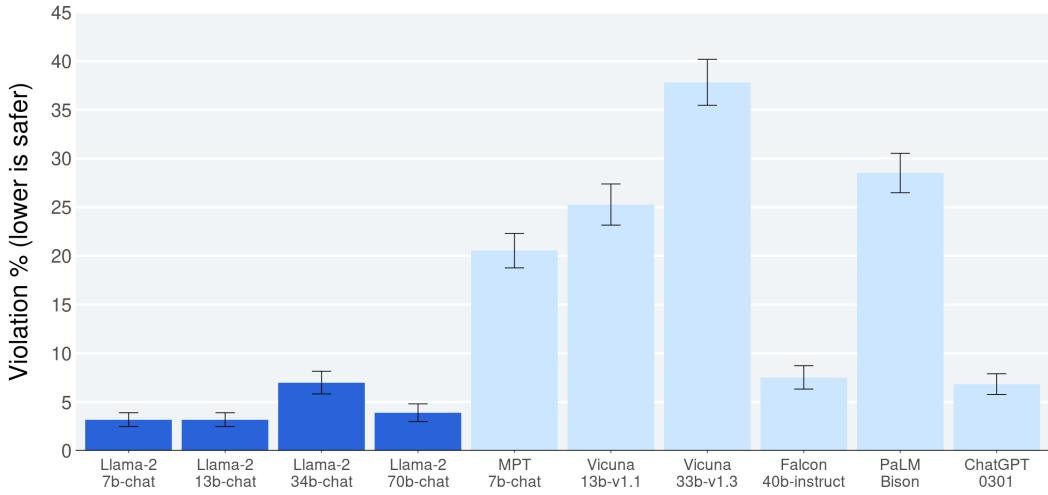 图3:安全性人工评估。Llama 2-Chat 模型的安全违规率远低于其他模型。
图3:安全性人工评估。Llama 2-Chat 模型的安全违规率远低于其他模型。
总结
本文成功开发并发布了 Llama 2 系列模型,其中 Llama 2-Chat 作为一款经过精心对齐的开源对话模型,在有用性和安全性上均达到了业界领先水平,在某些方面可与强大的闭源模型相媲美。
实验结果验证了本文方法的有效性:1)“质量优于数量”的SFT数据策略;2)分离式、带边界损失的奖励建模;3)结合拒绝采样和PPO的迭代式RLHF;4)创新的GAtt方法。
最终结论是,通过开放强大的基础模型和透明化对齐技术,可以有效推动整个社区向着更负责任、更先进的LLM方向发展。尽管与最前沿的闭源模型(如GPT-4)仍有差距,但 Llama 2 代表了开源力量的一个重要里程碑。